 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Time-Varying mmWave MIMO Channel Estimation and Reconstruction: An Efficient Rank-Aware Matrix Completion Method
Nov 08, 2025We address the problem of fast time-varying channel estimation in millimeter-wave (mmWave) MIMO systems with imperfect channel state information (CSI) and facilitate efficient channel reconstruction. Specifically, leveraging the low-rank and sparse characteristics of the mmWave channel matrix, a two-phase rank-aware compressed sensing framework is proposed for efficient channel estimation and reconstruction. In the first phase, a robust rank-one matrix completion (R1MC) algorithm is used to reconstruct part of the observed channel matrix through low-rank matrix completion (LRMC). To address abrupt rank changes caused by user mobility, a discrete-time autoregressive (AR) model is established that leverages temporal rank correlations across consecutive time instances to enable adaptive observation matrix completion, thereby improving estimation accuracy under dynamic conditions. In the second phase, a rank-aware block orthogonal matching pursuit (RA-BOMP) algorithm is developed for sparse channel recovery with low computational complexity. Furthermore, a rank-aware measurement matrix design is introduced to improve angle estimation accuracy. Simulation results demonstrate that, compared with existing benchmark algorithms, the proposed approach achieves superior channel estimation performance while significantly reducing computational complexity and training overhead.
Uncertainty Quantification for Regression using Proper Scoring Rules
Sep 30, 2025
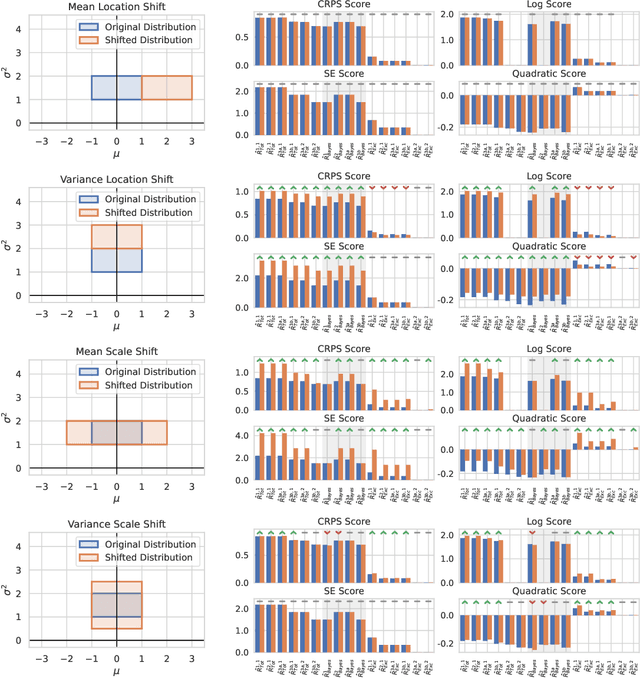


Quantifying uncertainty of machine learning model predictions is essential for reliable decision-making, especially in safety-critical applications. Recently, uncertainty quantification (UQ) theory has advanced significantly, building on a firm basis of learning with proper scoring rules. However, these advances were focused on classification, while extending these ideas to regression remains challenging. In this work, we introduce a unified UQ framework for regression based on proper scoring rules, such as CRPS, logarithmic, squared error, and quadratic scores. We derive closed-form expressions for the resulting uncertainty measures under practical parametric assumptions and show how to estimate them using ensembles of models. In particular, the derived uncertainty measures naturally decompose into aleatoric and epistemic components. The framework recovers popular regression UQ measures based on predictive variance and differential entropy. Our broad evaluation on synthetic and real-world regression datasets provides guidance for selecting reliable UQ measures.
Not Only Grey Matter: OmniBrain for Robust Multimodal Classification of Alzheimer's Disease
Jul 28, 2025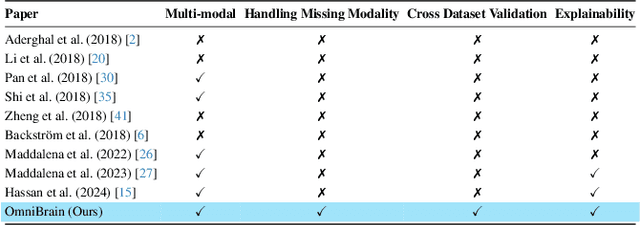
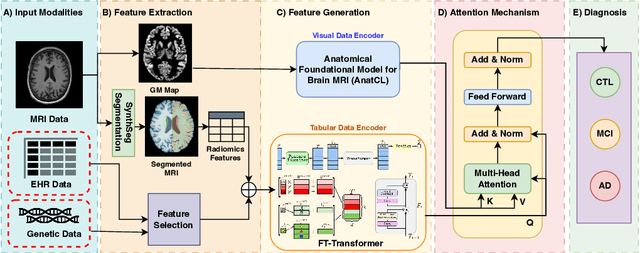
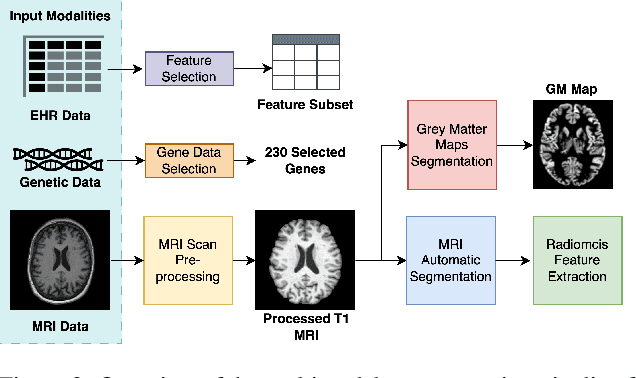
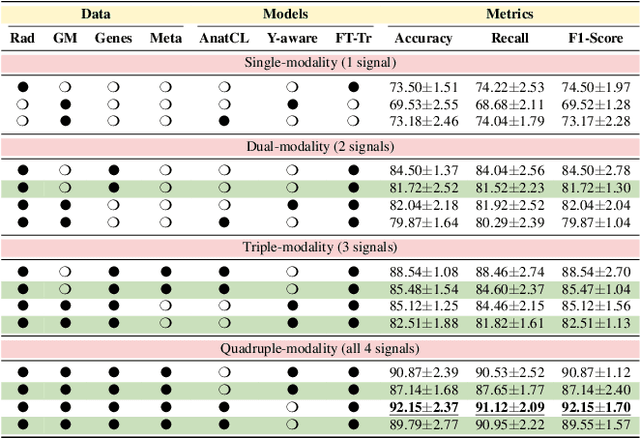
Alzheimer's disease affects over 55 million people worldwide and is projected to more than double by 2050, necessitating rapid, accurate, and scalable diagnostics. However, existing approaches are limited because they cannot achieve clinically acceptable accuracy, generalization across datasets, robustness to missing modalities, and explainability all at the same time. This inability to satisfy all these requirements simultaneously undermines their reliability in clinical settings. We propose OmniBrain, a multimodal framework that integrates brain MRI, radiomics, gene expression, and clinical data using a unified model with cross-attention and modality dropout. OmniBrain achieves $92.2 \pm 2.4\%$accuracy on the ANMerge dataset and generalizes to the MRI-only ADNI dataset with $70.4 \pm 2.7\%$ accuracy, outperforming unimodal and prior multimodal approaches. Explainability analyses highlight neuropathologically relevant brain regions and genes, enhancing clinical trust. OmniBrain offers a robust, interpretable, and practical solution for real-world Alzheimer's diagnosis.
Adaptive Temperature Scaling with Conformal Prediction
May 21, 2025Conformal prediction enables the construction of high-coverage prediction sets for any pre-trained model, guaranteeing that the true label lies within the set with a specified probability. However, these sets do not provide probability estimates for individual labels, limiting their practical use. In this paper, we propose, to the best of our knowledge, the first method for assigning calibrated probabilities to elements of a conformal prediction set. Our approach frames this as an adaptive calibration problem, selecting an input-specific temperature parameter to match the desired coverage level. Experiments on several challenging image classification datasets demonstrate that our method maintains coverage guarantees while significantly reducing expected calibration error.
Learning in Chaos: Efficient Autoscaling and Self-healing for Distributed Training at the Edge
May 19, 2025Frequent node and link changes in edge AI clusters disrupt distributed training, while traditional checkpoint-based recovery and cloud-centric autoscaling are too slow for scale-out and ill-suited to chaotic and self-governed edge. This paper proposes Chaos, a resilient and scalable edge distributed training system with built-in self-healing and autoscaling. It speeds up scale-out by using multi-neighbor replication with fast shard scheduling, allowing a new node to pull the latest training state from nearby neighbors in parallel while balancing the traffic load between them. It also uses a cluster monitor to track resource and topology changes to assist scheduler decisions, and handles scaling events through peer negotiation protocols, enabling fully self-governed autoscaling without a central admin. Extensive experiments show that Chaos consistently achieves much lower scale-out delays than Pollux, EDL, and Autoscaling, and handles scale-in, connect-link, and disconnect-link events within 1 millisecond, making it smoother to handle node joins, exits, and failures. It also delivers the lowest idle time, showing superior resource use and scalability as the cluster grows.
Real-Time Aerial Fire Detection on Resource-Constrained Devices Using Knowledge Distillation
Feb 28, 2025Wildfire catastrophes cause significant environmental degradation, human losses, and financial damage. To mitigate these severe impacts, early fire detection and warning systems are crucial. Current systems rely primarily on fixed CCTV cameras with a limited field of view, restricting their effectiveness in large outdoor environments. The fusion of intelligent fire detection with remote sensing improves coverage and mobility, enabling monitoring in remote and challenging areas. Existing approaches predominantly utilize convolutional neural networks and vision transformer models. While these architectures provide high accuracy in fire detection, their computational complexity limits real-time performance on edge devices such as UAVs. In our work, we present a lightweight fire detection model based on MobileViT-S, compressed through the distillation of knowledge from a stronger teacher model. The ablation study highlights the impact of a teacher model and the chosen distillation technique on the model's performance improvement. We generate activation map visualizations using Grad-CAM to confirm the model's ability to focus on relevant fire regions. The high accuracy and efficiency of the proposed model make it well-suited for deployment on satellites, UAVs, and IoT devices for effective fire detection. Experiments on common fire benchmarks demonstrate that our model suppresses the state-of-the-art model by 0.44%, 2.00% while maintaining a compact model size. Our model delivers the highest processing speed among existing works, achieving real-time performance on resource-constrained devices.
A Multi-Agent DRL-Based Framework for Optimal Resource Allocation and Twin Migration in the Multi-Tier Vehicular Metaverse
Feb 26, 2025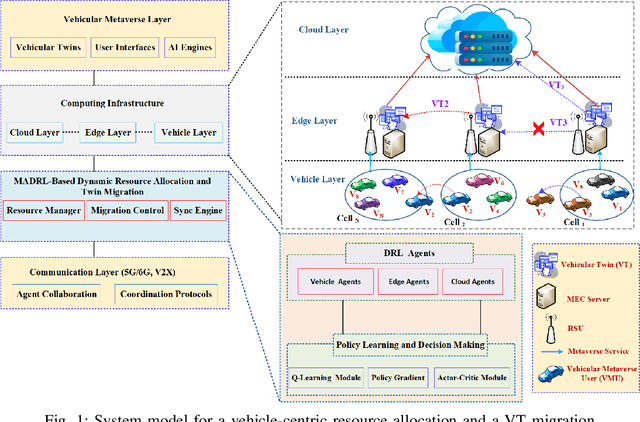
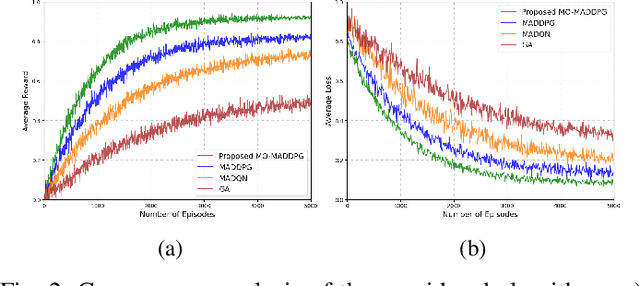
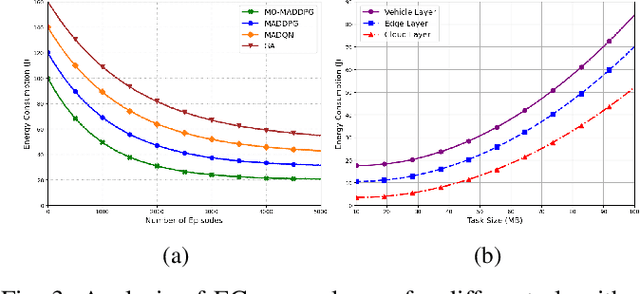
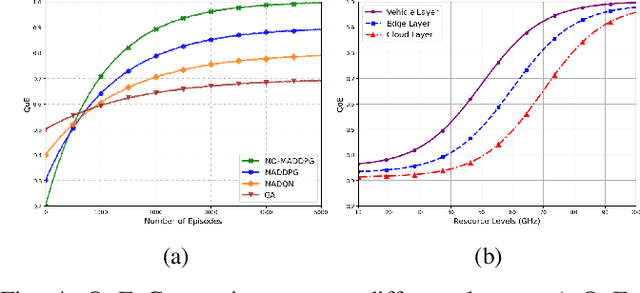
Although multi-tier vehicular Metaverse promises to transform vehicles into essential nodes -- within an interconnected digital ecosystem -- using efficient resource allocation and seamless vehicular twin (VT) migration, this can hardly be achieved by the existing techniques operating in a highly dynamic vehicular environment, since they can hardly balance multi-objective optimization problems such as latency reduction, resource utilization, and user experience (UX). To address these challenges, we introduce a novel multi-tier resource allocation and VT migration framework that integrates Graph Convolutional Networks (GCNs), a hierarchical Stackelberg game-based incentive mechanism, and Multi-Agent Deep Reinforcement Learning (MADRL). The GCN-based model captures both spatial and temporal dependencies within the vehicular network; the Stackelberg game-based incentive mechanism fosters cooperation between vehicles and infrastructure; and the MADRL algorithm jointly optimizes resource allocation and VT migration in real time. By modeling this dynamic and multi-tier vehicular Metaverse as a Markov Decision Process (MDP), we develop a MADRL-based algorithm dubbed the Multi-Objective Multi-Agent Deep Deterministic Policy Gradient (MO-MADDPG), which can effectively balances the various conflicting objectives. Extensive simulations validate the effectiveness of this algorithm that is demonstrated to enhance scalability, reliability, and efficiency while considerably improving latency, resource utilization, migration cost, and overall UX by 12.8%, 9.7%, 14.2%, and 16.1%, respectively.
Rectifying Conformity Scores for Better Conditional Coverage
Feb 22, 2025We present a new method for generating confidence sets within the split conformal prediction framework. Our method performs a trainable transformation of any given conformity score to improve conditional coverage while ensuring exact marginal coverage. The transformation is based on an estimate of the conditional quantile of conformity scores. The resulting method is particularly beneficial for constructing adaptive confidence sets in multi-output problems where standard conformal quantile regression approaches have limited applicability. We develop a theoretical bound that captures the influence of the accuracy of the quantile estimate on the approximate conditional validity, unlike classical bounds for conformal prediction methods that only offer marginal coverage. We experimentally show that our method is highly adaptive to the local data structure and outperforms existing methods in terms of conditional coverage, improving the reliability of statistical inference in various applications.
Vision-Language Models for Edge Networks: A Comprehensive Survey
Feb 11, 2025

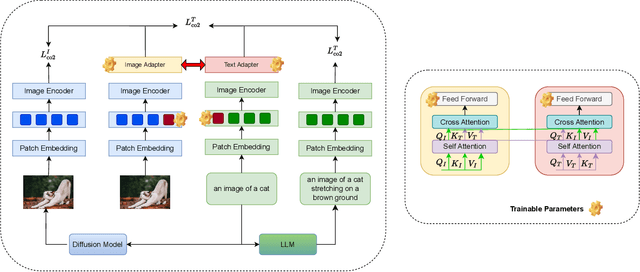
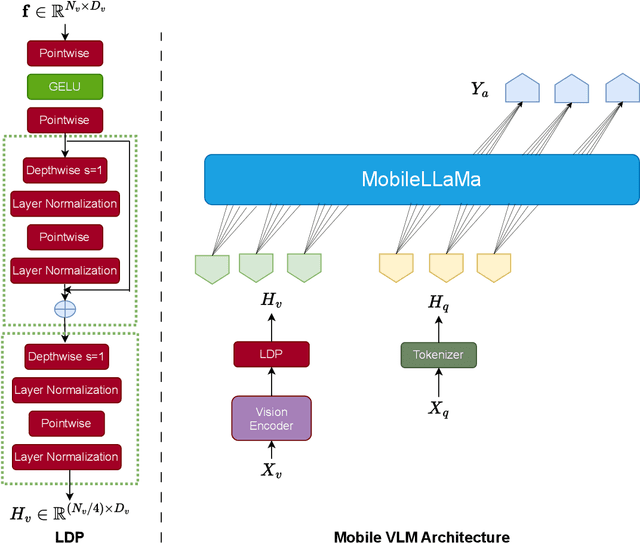
Vision Large Language Models (VLMs) combine visual understanding with natural language processing, enabling tasks like image captioning, visual question answering, and video analysis. While VLMs show impressive capabilities across domains such as autonomous vehicles, smart surveillance, and healthcare, their deployment on resource-constrained edge devices remains challenging due to processing power, memory, and energy limitations. This survey explores recent advancements in optimizing VLMs for edge environments, focusing on model compression techniques, including pruning, quantization, knowledge distillation, and specialized hardware solutions that enhance efficiency. We provide a detailed discussion of efficient training and fine-tuning methods, edge deployment challenges, and privacy considerations. Additionally, we discuss the diverse applications of lightweight VLMs across healthcare, environmental monitoring, and autonomous systems, illustrating their growing impact. By highlighting key design strategies, current challenges, and offering recommendations for future directions, this survey aims to inspire further research into the practical deployment of VLMs, ultimately making advanced AI accessible in resource-limited settings.
Safeguarding connected autonomous vehicle communication: Protocols, intra- and inter-vehicular attacks and defenses
Feb 06, 2025



The advancements in autonomous driving technology, coupled with the growing interest from automotive manufacturers and tech companies, suggest a rising adoption of Connected Autonomous Vehicles (CAVs) in the near future. Despite some evidence of higher accident rates in AVs, these incidents tend to result in less severe injuries compared to traditional vehicles due to cooperative safety measures. However, the increased complexity of CAV systems exposes them to significant security vulnerabilities, potentially compromising their performance and communication integrity. This paper contributes by presenting a detailed analysis of existing security frameworks and protocols, focusing on intra- and inter-vehicle communications. We systematically evaluate the effectiveness of these frameworks in addressing known vulnerabilities and propose a set of best practices for enhancing CAV communication security. The paper also provides a comprehensive taxonomy of attack vectors in CAV ecosystems and suggests future research directions for designing more robust security mechanisms. Our key contributions include the development of a new classification system for CAV security threats, the proposal of practical security protocols, and the introduction of use cases that demonstrate how these protocols can be integrated into real-world CAV applications. These insights are crucial for advancing secure CAV adoption and ensuring the safe integration of autonomous vehicles into intelligent transportation systems.