 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterCSI: Channel-Adaptive Heterogeneous CSI Pretraining Framework for Generalized Wireless Foundation Models
Jan 26, 2026Wireless foundation models promise transformative capabilities for channel state information (CSI) processing across diverse 6G network applications, yet face fundamental challenges due to the inherent dual heterogeneity of CSI across both scale and scenario dimensions. However, current pretraining approaches either constrain inputs to fixed dimensions or isolate training by scale, limiting the generalization and scalability of wireless foundation models. In this paper, we propose HeterCSI, a channel-adaptive pretraining framework that reconciles training efficiency with robust cross-scenario generalization via a new understanding of gradient dynamics in heterogeneous CSI pretraining. Our key insight reveals that CSI scale heterogeneity primarily causes destructive gradient interference, while scenario diversity actually promotes constructive gradient alignment when properly managed. Specifically, we formulate heterogeneous CSI batch construction as a partitioning optimization problem that minimizes zero-padding overhead while preserving scenario diversity. To solve this, we develop a scale-aware adaptive batching strategy that aligns CSI samples of similar scales, and design a double-masking mechanism to isolate valid signals from padding artifacts. Extensive experiments on 12 datasets demonstrate that HeterCSI establishes a generalized foundation model without scenario-specific finetuning, achieving superior average performance over full-shot baselines. Compared to the state-of-the-art zero-shot benchmark WiFo, it reduces NMSE by 7.19 dB, 4.08 dB, and 5.27 dB for CSI reconstruction, time-domain, and frequency-domain prediction, respectively. The proposed HeterCSI framework also reduces training latency by 53% compared to existing approaches while improving generalization performance by 1.53 dB on average.
Overview of AI and Communication for 6G Network: Fundamentals, Challenges, and Future Research Opportunities
Dec 19, 2024



With the increasing demand for seamless connectivity and intelligent communication, the integration of artificial intelligence (AI) and communication for sixth-generation (6G) network is emerging as a revolutionary architecture. This paper presents a comprehensive overview of AI and communication for 6G networks, emphasizing their foundational principles, inherent challenges, and future research opportunities. We commence with a retrospective analysis of AI and the evolution of large-scale AI models, underscoring their pivotal roles in shaping contemporary communication technologies. The discourse then transitions to a detailed exposition of the envisioned integration of AI within 6G networks, delineated across three progressive developmental stages. The initial stage, AI for Network, focuses on employing AI to augment network performance, optimize efficiency, and enhance user service experiences. The subsequent stage, Network for AI, highlights the role of the network in facilitating and buttressing AI operations and presents key enabling technologies, including digital twins for AI and semantic communication. In the final stage, AI as a Service, it is anticipated that future 6G networks will innately provide AI functions as services and support application scenarios like immersive communication and intelligent industrial robots. Specifically, we have defined the quality of AI service, which refers to the measurement framework system of AI services within the network. In addition to these developmental stages, we thoroughly examine the standardization processes pertinent to AI in network contexts, highlighting key milestones and ongoing efforts. Finally, we outline promising future research opportunities that could drive the evolution and refinement of AI and communication for 6G, positioning them as a cornerstone of next-generation communication infrastructure.
Sharp Bounds for Sequential Federated Learning on Heterogeneous Data
May 02, 2024There are two paradigms in Federated Learning (FL): parallel FL (PFL), where models are trained in a parallel manner across clients; and sequential FL (SFL), where models are trained in a sequential manner across clients. In contrast to that of PFL, the convergence theory of SFL on heterogeneous data is still lacking. To resolve the theoretical dilemma of SFL, we establish sharp convergence guarantees for SFL on heterogeneous data with both upper and lower bounds. Specifically, we derive the upper bounds for strongly convex, general convex and non-convex objective functions, and construct the matching lower bounds for the strongly convex and general convex objective functions. Then, we compare the upper bounds of SFL with those of PFL, showing that SFL outperforms PFL (at least, when the level of heterogeneity is relatively high). Experimental results on quadratic functions and real data sets validate the counterintuitive comparison result.
Boosting the Transferability of Adversarial Examples via Local Mixup and Adaptive Step Size
Jan 24, 2024Adversarial examples are one critical security threat to various visual applications, where injected human-imperceptible perturbations can confuse the output.Generating transferable adversarial examples in the black-box setting is crucial but challenging in practice. Existing input-diversity-based methods adopt different image transformations, but may be inefficient due to insufficient input diversity and an identical perturbation step size. Motivated by the fact that different image regions have distinctive weights in classification, this paper proposes a black-box adversarial generative framework by jointly designing enhanced input diversity and adaptive step sizes. We design local mixup to randomly mix a group of transformed adversarial images, strengthening the input diversity. For precise adversarial generation, we project the perturbation into the $tanh$ space to relax the boundary constraint. Moreover, the step sizes of different regions can be dynamically adjusted by integrating a second-order momentum.Extensive experiments on ImageNet validate that our framework can achieve superior transferability compared to state-of-the-art baselines.
Convergence Analysis of Sequential Federated Learning on Heterogeneous Data
Nov 06, 2023There are two categories of methods in Federated Learning (FL) for joint training across multiple clients: i) parallel FL (PFL), where clients train models in a parallel manner; and ii) sequential FL (SFL), where clients train models in a sequential manner. In contrast to that of PFL, the convergence theory of SFL on heterogeneous data is still lacking. In this paper, we establish the convergence guarantees of SFL for strongly/general/non-convex objectives on heterogeneous data. The convergence guarantees of SFL are better than that of PFL on heterogeneous data with both full and partial client participation. Experimental results validate the counterintuitive analysis result that SFL outperforms PFL on extremely heterogeneous data in cross-device settings.
Boosting Physical Layer Black-Box Attacks with Semantic Adversaries in Semantic Communications
Mar 30, 2023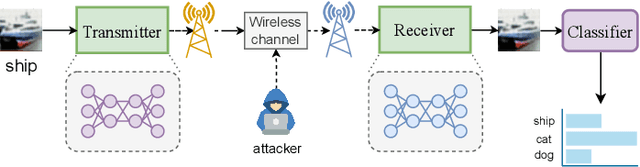

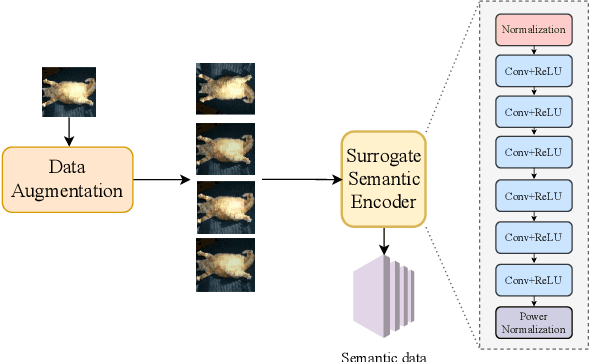

End-to-end semantic communication (ESC) system is able to improve communication efficiency by only transmitting the semantics of the input rather than raw bits. Although promising, ESC has also been shown susceptible to the crafted physical layer adversarial perturbations due to the openness of wireless channels and the sensitivity of neural models. Previous works focus more on the physical layer white-box attacks, while the challenging black-box ones, as more practical adversaries in real-world cases, are still largely under-explored. To this end, we present SemBLK, a novel method that can learn to generate destructive physical layer semantic attacks for an ESC system under the black-box setting, where the adversaries are imperceptible to humans. Specifically, 1) we first introduce a surrogate semantic encoder and train its parameters by exploring a limited number of queries to an existing ESC system. 2) Equipped with such a surrogate encoder, we then propose a novel semantic perturbation generation method to learn to boost the physical layer attacks with semantic adversaries. Experiments on two public datasets show the effectiveness of our proposed SemBLK in attacking the ESC system under the black-box setting. Finally, we provide case studies to visually justify the superiority of our physical layer semantic perturbations.
Convergence Analysis of Split Learning on Non-IID Data
Feb 03, 2023Split Learning (SL) is one promising variant of Federated Learning (FL), where the AI model is split and trained at the clients and the server collaboratively. By offloading the computation-intensive portions to the server, SL enables efficient model training on resource-constrained clients. Despite its booming applications, SL still lacks rigorous convergence analysis on non-IID data, which is critical for hyperparameter selection. In this paper, we first prove that SL exhibits an $\mathcal{O}(1/\sqrt{R})$ convergence rate for non-convex objectives on non-IID data, where $R$ is the number of total training rounds. The derived convergence results can facilitate understanding the effect of some crucial factors in SL (e.g., data heterogeneity and synchronization interval). Furthermore, comparing with the convergence result of FL, we show that the guarantee of SL is worse than FL in terms of training rounds on non-IID data. The experimental results verify our theory. More findings on the comparison between FL and SL in cross-device settings are also reported.
Clustering Label Inference Attack against Practical Split Learning
Mar 10, 2022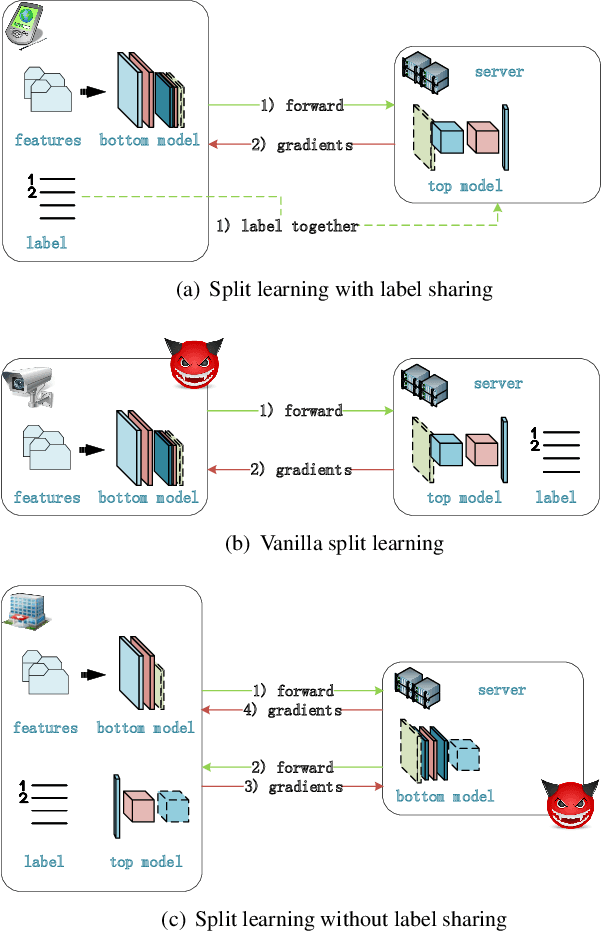

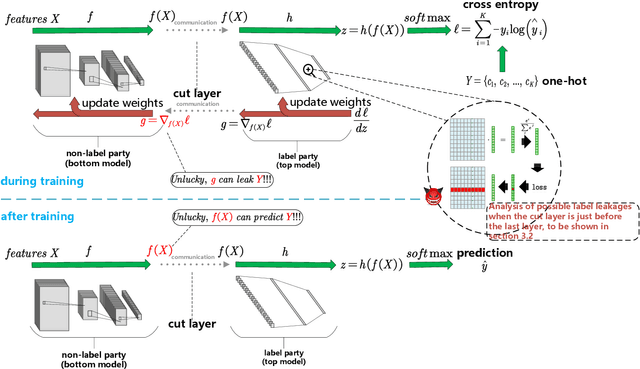
Split learning is deemed as a promising paradigm for privacy-preserving distributed learning, where the learning model can be cut into multiple portions to be trained at the participants collaboratively. The participants only exchange the intermediate learning results at the cut layer, including smashed data via forward-pass (i.e., features extracted from the raw data) and gradients during backward-propagation.Understanding the security performance of split learning is critical for various privacy-sensitive applications.With the emphasis on private labels, this paper proposes a passive clustering label inference attack for practical split learning. The adversary (either clients or servers) can accurately retrieve the private labels by collecting the exchanged gradients and smashed data.We mathematically analyse potential label leakages in split learning and propose the cosine and Euclidean similarity measurements for clustering attack. Experimental results validate that the proposed approach is scalable and robust under different settings (e.g., cut layer positions, epochs, and batch sizes) for practical split learning.The adversary can still achieve accurate predictions, even when differential privacy and gradient compression are adopted for label protections.
Online Offloading Scheduling for NOMA-Aided MEC Under Partial Device Knowledge
Jun 30, 2021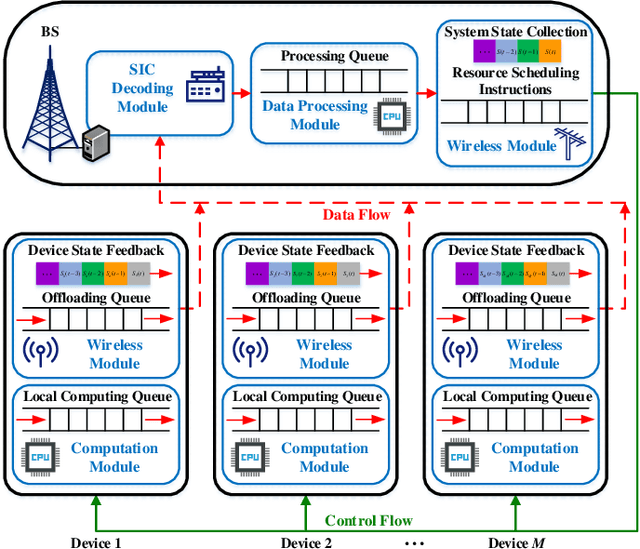
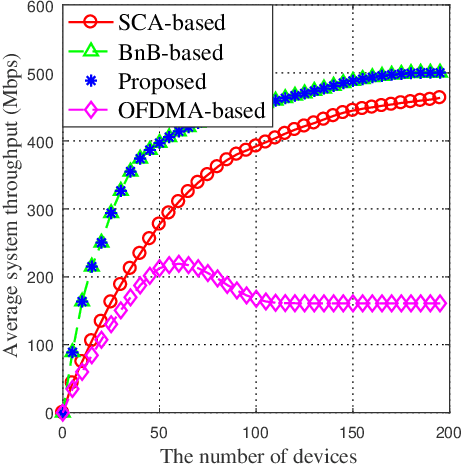
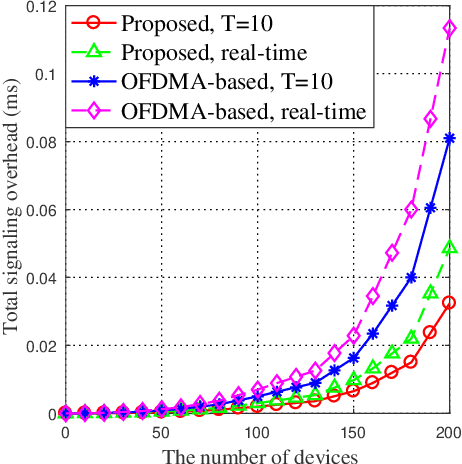
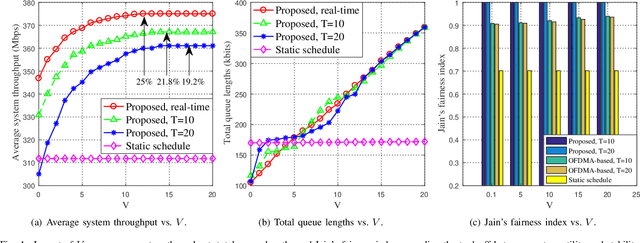
By exploiting the superiority of non-orthogonal multiple access (NOMA), NOMA-aided mobile edge computing (MEC) can provide scalable and low-latency computing services for the Internet of Things. However, given the prevalent stochasticity of wireless networks and sophisticated signal processing of NOMA, it is critical but challenging to design an efficient task offloading algorithm for NOMA-aided MEC, especially under a large number of devices. This paper presents an online algorithm that jointly optimizes offloading decisions and resource allocation to maximize the long-term system utility (i.e., a measure of throughput and fairness). Since the optimization variables are temporary coupled, we first apply Lyapunov technique to decouple the long-term stochastic optimization into a series of per-slot deterministic subproblems, which does not require any prior knowledge of network dynamics. Second, we propose to transform the non-convex per-slot subproblem of optimizing NOMA power allocation equivalently to a convex form by introducing a set of auxiliary variables, whereby the time-complexity is reduced from the exponential complexity to $\mathcal{O} (M^{3/2})$. The proposed algorithm is proved to be asymptotically optimal, even under partial knowledge of the device states at the base station. Simulation results validate the superiority of the proposed algorithm in terms of system utility, stability improvement, and the overhead reduction.