 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStacked Intelligent Metasurfaces-Based Electromagnetic Wave Domain Interference-Free Precoding
Jan 27, 2026This paper introduces an interference-free multi-stream transmission architecture leveraging stacked intelligent metasurfaces (SIMs), from a new perspective of interference exploitation. Unlike traditional interference exploitation precoding (IEP) which relies on computational hardware circuitry, we perform the precoding operations within the analog wave domain provided by SIMs. However, the benefits of SIM-enabled IEP are limited by the nonlinear distortion (NLD) caused by power amplifiers. A hardware-efficient interference-free transmitter architecture is developed to exploit SIM's high and flexible degree of freedom (DoF), where the NLD on modulated symbols can be directly compensated in the wave domain. Moreover, we design a frame-level SIM configuration scheme and formulate a maxmin problem on the safety margin function. With respect to the optimization of SIM phase shifts, we propose a recursive oblique manifold (ROM) algorithm to tackle the complex coupling among phase shifts across multiple layers. A flexible DoF-driven antenna selection (AS) scheme is explored in the SIM-enabled IEP system. Using an ROM-based alternating optimization (ROM-AO) framework, our approach jointly optimizes transmit AS, SIM phase shift design, and power allocation (PA), and develops a greedy safety margin-based AS algorithm. Simulations show that the proposed SIM-enabled frame-level IEP scheme significantly outperforms benchmarks. Specifically, the strategy with AS and PA can achieve a 20 dB performance gain compared to the case without any strategy under the 12 dB signal-to-noise ratio, which confirms the superiority of the NLD-aware IEP scheme and the effectiveness of the proposed algorithm.
Overview of AI and Communication for 6G Network: Fundamentals, Challenges, and Future Research Opportunities
Dec 19, 2024



With the increasing demand for seamless connectivity and intelligent communication, the integration of artificial intelligence (AI) and communication for sixth-generation (6G) network is emerging as a revolutionary architecture. This paper presents a comprehensive overview of AI and communication for 6G networks, emphasizing their foundational principles, inherent challenges, and future research opportunities. We commence with a retrospective analysis of AI and the evolution of large-scale AI models, underscoring their pivotal roles in shaping contemporary communication technologies. The discourse then transitions to a detailed exposition of the envisioned integration of AI within 6G networks, delineated across three progressive developmental stages. The initial stage, AI for Network, focuses on employing AI to augment network performance, optimize efficiency, and enhance user service experiences. The subsequent stage, Network for AI, highlights the role of the network in facilitating and buttressing AI operations and presents key enabling technologies, including digital twins for AI and semantic communication. In the final stage, AI as a Service, it is anticipated that future 6G networks will innately provide AI functions as services and support application scenarios like immersive communication and intelligent industrial robots. Specifically, we have defined the quality of AI service, which refers to the measurement framework system of AI services within the network. In addition to these developmental stages, we thoroughly examine the standardization processes pertinent to AI in network contexts, highlighting key milestones and ongoing efforts. Finally, we outline promising future research opportunities that could drive the evolution and refinement of AI and communication for 6G, positioning them as a cornerstone of next-generation communication infrastructure.
Linear Chain Transformation: Expanding Optimization Dynamics for Fine-Tuning Large Language Models
Oct 29, 2024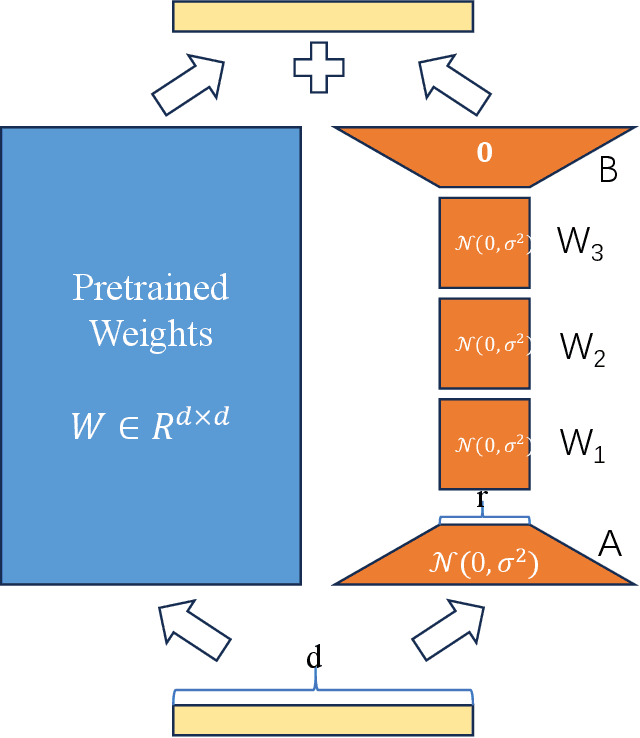
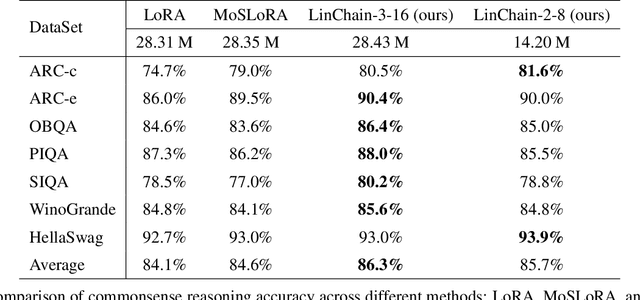
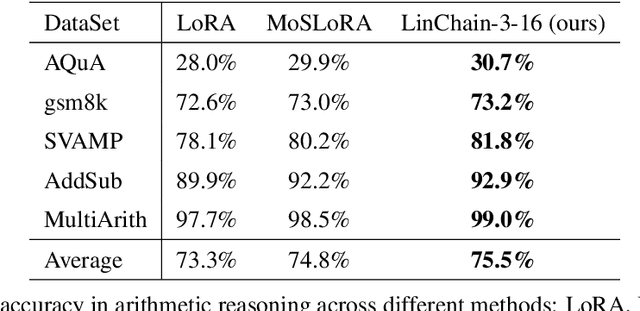
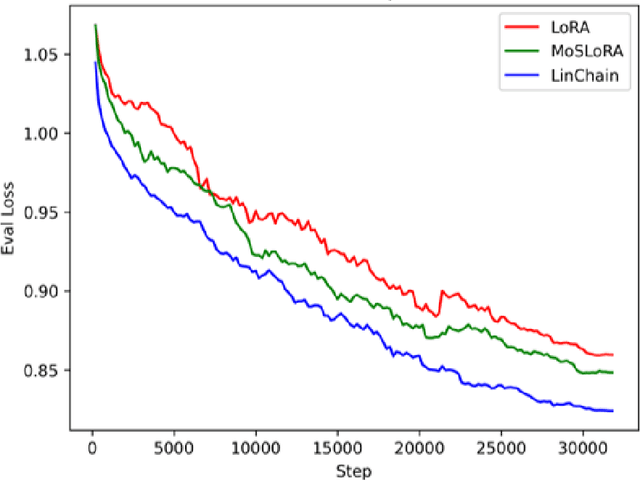
Fine-tuning large language models (LLMs) has become essential for adapting pretrained models to specific downstream tasks. In this paper, we propose Linear Chain Transformation (LinChain), a novel approach that introduces a sequence of linear transformations during fine-tuning to enrich optimization dynamics. By incorporating multiple linear transformations into the parameter update process, LinChain expands the effective rank of updates and enhances the model's ability to learn complex task-specific representations. We demonstrate that this method significantly improves the performance of LLM fine-tuning over state-of-the-art methods by providing more flexible optimization paths during training, while maintaining the inference efficiency of the resulting model. Our experiments on various benchmark tasks show that LinChain leads to better generalization, fewer learnable parameters, and improved task adaptation, making it a compelling strategy for LLM fine-tuning.