 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowAct-R1: Towards Interactive Humanoid Video Generation
Jan 15, 2026Interactive humanoid video generation aims to synthesize lifelike visual agents that can engage with humans through continuous and responsive video. Despite recent advances in video synthesis, existing methods often grapple with the trade-off between high-fidelity synthesis and real-time interaction requirements. In this paper, we propose FlowAct-R1, a framework specifically designed for real-time interactive humanoid video generation. Built upon a MMDiT architecture, FlowAct-R1 enables the streaming synthesis of video with arbitrary durations while maintaining low-latency responsiveness. We introduce a chunkwise diffusion forcing strategy, complemented by a novel self-forcing variant, to alleviate error accumulation and ensure long-term temporal consistency during continuous interaction. By leveraging efficient distillation and system-level optimizations, our framework achieves a stable 25fps at 480p resolution with a time-to-first-frame (TTFF) of only around 1.5 seconds. The proposed method provides holistic and fine-grained full-body control, enabling the agent to transition naturally between diverse behavioral states in interactive scenarios. Experimental results demonstrate that FlowAct-R1 achieves exceptional behavioral vividness and perceptual realism, while maintaining robust generalization across diverse character styles.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
STRGCN: Capturing Asynchronous Spatio-Temporal Dependencies for Irregular Multivariate Time Series Forecasting
May 07, 2025Irregular multivariate time series (IMTS) are prevalent in real-world applications across many fields, where varying sensor frequencies and asynchronous measurements pose significant modeling challenges. Existing solutions often rely on a pre-alignment strategy to normalize data, which can distort intrinsic patterns and escalate computational and memory demands. Addressing these limitations, we introduce STRGCN, a Spatio-Temporal Relational Graph Convolutional Network that avoids pre-alignment and directly captures the complex interdependencies in IMTS by representing them as a fully connected graph. Each observation is represented as a node, allowing the model to effectively handle misaligned timestamps by mapping all inter-node relationships, thus faithfully preserving the asynchronous nature of the data. Moreover, we enhance this model with a hierarchical ``Sandwich'' structure that strategically aggregates nodes to optimize graph embeddings, reducing computational overhead while maintaining detailed local and global context. Extensive experiments on four public datasets demonstrate that STRGCN achieves state-of-the-art accuracy, competitive memory usage and training speed.
FilterTS: Comprehensive Frequency Filtering for Multivariate Time Series Forecasting
May 07, 2025Multivariate time series forecasting is crucial across various industries, where accurate extraction of complex periodic and trend components can significantly enhance prediction performance. However, existing models often struggle to capture these intricate patterns. To address these challenges, we propose FilterTS, a novel forecasting model that utilizes specialized filtering techniques based on the frequency domain. FilterTS introduces a Dynamic Cross-Variable Filtering Module, a key innovation that dynamically leverages other variables as filters to extract and reinforce shared variable frequency components across variables in multivariate time series. Additionally, a Static Global Filtering Module captures stable frequency components, identified throughout the entire training set. Moreover, the model is built in the frequency domain, converting time-domain convolutions into frequency-domain multiplicative operations to enhance computational efficiency. Extensive experimental results on eight real-world datasets have demonstrated that FilterTS significantly outperforms existing methods in terms of prediction accuracy and computational efficiency.
TeDA: Boosting Vision-Lanuage Models for Zero-Shot 3D Object Retrieval via Testing-time Distribution Alignment
May 05, 2025Learning discriminative 3D representations that generalize well to unknown testing categories is an emerging requirement for many real-world 3D applications. Existing well-established methods often struggle to attain this goal due to insufficient 3D training data from broader concepts. Meanwhile, pre-trained large vision-language models (e.g., CLIP) have shown remarkable zero-shot generalization capabilities. Yet, they are limited in extracting suitable 3D representations due to substantial gaps between their 2D training and 3D testing distributions. To address these challenges, we propose Testing-time Distribution Alignment (TeDA), a novel framework that adapts a pretrained 2D vision-language model CLIP for unknown 3D object retrieval at test time. To our knowledge, it is the first work that studies the test-time adaptation of a vision-language model for 3D feature learning. TeDA projects 3D objects into multi-view images, extracts features using CLIP, and refines 3D query embeddings with an iterative optimization strategy by confident query-target sample pairs in a self-boosting manner. Additionally, TeDA integrates textual descriptions generated by a multimodal language model (InternVL) to enhance 3D object understanding, leveraging CLIP's aligned feature space to fuse visual and textual cues. Extensive experiments on four open-set 3D object retrieval benchmarks demonstrate that TeDA greatly outperforms state-of-the-art methods, even those requiring extensive training. We also experimented with depth maps on Objaverse-LVIS, further validating its effectiveness. Code is available at https://github.com/wangzhichuan123/TeDA.
Omni-AD: Learning to Reconstruct Global and Local Features for Multi-class Anomaly Detection
Mar 27, 2025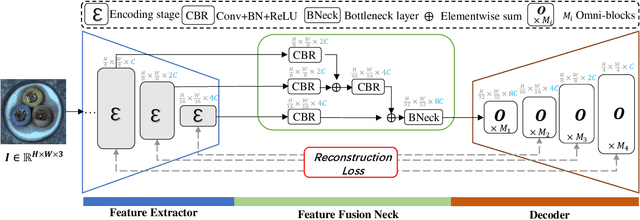



In multi-class unsupervised anomaly detection(MUAD), reconstruction-based methods learn to map input images to normal patterns to identify anomalous pixels. However, this strategy easily falls into the well-known "learning shortcut" issue when decoders fail to capture normal patterns and reconstruct both normal and abnormal samples naively. To address that, we propose to learn the input features in global and local manners, forcing the network to memorize the normal patterns more comprehensively. Specifically, we design a two-branch decoder block, named Omni-block. One branch corresponds to global feature learning, where we serialize two self-attention blocks but replace the query and (key, value) with learnable tokens, respectively, thus capturing global features of normal patterns concisely and thoroughly. The local branch comprises depth-separable convolutions, whose locality enables effective and efficient learning of local features for normal patterns. By stacking Omni-blocks, we build a framework, Omni-AD, to learn normal patterns of different granularity and reconstruct them progressively. Comprehensive experiments on public anomaly detection benchmarks show that our method outperforms state-of-the-art approaches in MUAD. Code is available at https://github.com/easyoo/Omni-AD.git.
HRR: Hierarchical Retrospection Refinement for Generated Image Detection
Feb 25, 2025



Generative artificial intelligence holds significant potential for abuse, and generative image detection has become a key focus of research. However, existing methods primarily focused on detecting a specific generative model and emphasizing the localization of synthetic regions, while neglecting the interference caused by image size and style on model learning. Our goal is to reach a fundamental conclusion: Is the image real or generated? To this end, we propose a diffusion model-based generative image detection framework termed Hierarchical Retrospection Refinement~(HRR). It designs a multi-scale style retrospection module that encourages the model to generate detailed and realistic multi-scale representations, while alleviating the learning biases introduced by dataset styles and generative models. Additionally, based on the principle of correntropy sparse additive machine, a feature refinement module is designed to reduce the impact of redundant features on learning and capture the intrinsic structure and patterns of the data, thereby improving the model's generalization ability. Extensive experiments demonstrate the HRR framework consistently delivers significant performance improvements, outperforming state-of-the-art methods in generated image detection task.
Linear Chain Transformation: Expanding Optimization Dynamics for Fine-Tuning Large Language Models
Oct 29, 2024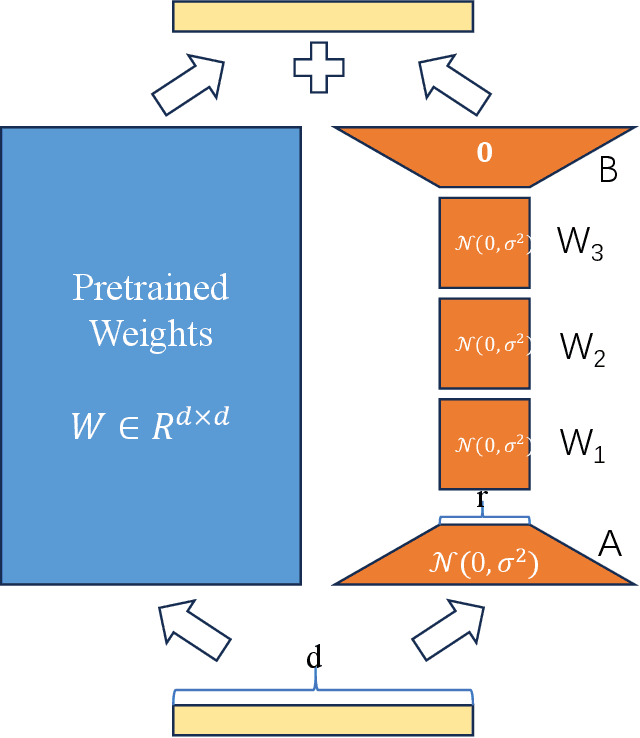
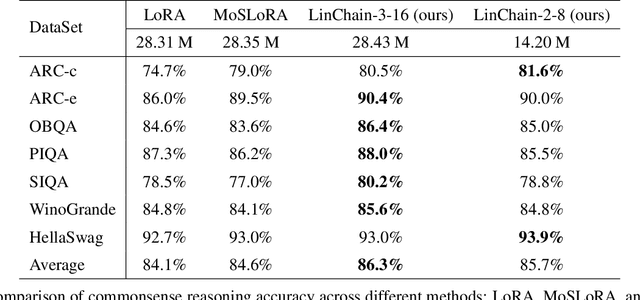
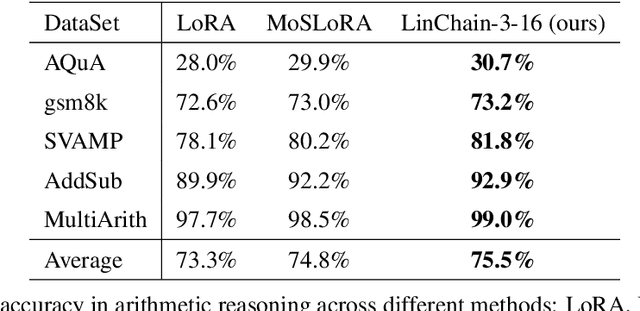
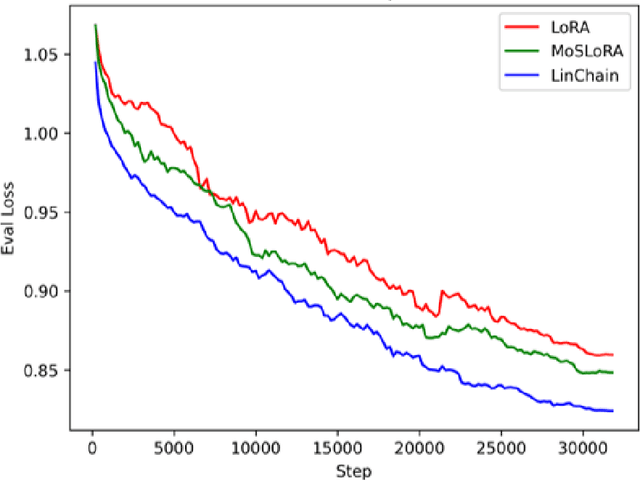
Fine-tuning large language models (LLMs) has become essential for adapting pretrained models to specific downstream tasks. In this paper, we propose Linear Chain Transformation (LinChain), a novel approach that introduces a sequence of linear transformations during fine-tuning to enrich optimization dynamics. By incorporating multiple linear transformations into the parameter update process, LinChain expands the effective rank of updates and enhances the model's ability to learn complex task-specific representations. We demonstrate that this method significantly improves the performance of LLM fine-tuning over state-of-the-art methods by providing more flexible optimization paths during training, while maintaining the inference efficiency of the resulting model. Our experiments on various benchmark tasks show that LinChain leads to better generalization, fewer learnable parameters, and improved task adaptation, making it a compelling strategy for LLM fine-tuning.
big.LITTLE Vision Transformer for Efficient Visual Recognition
Oct 14, 2024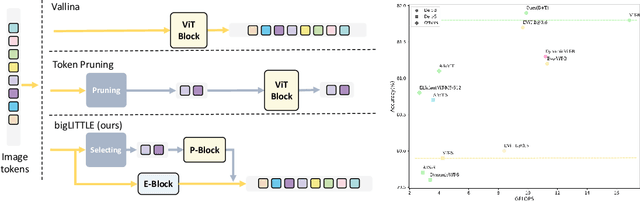
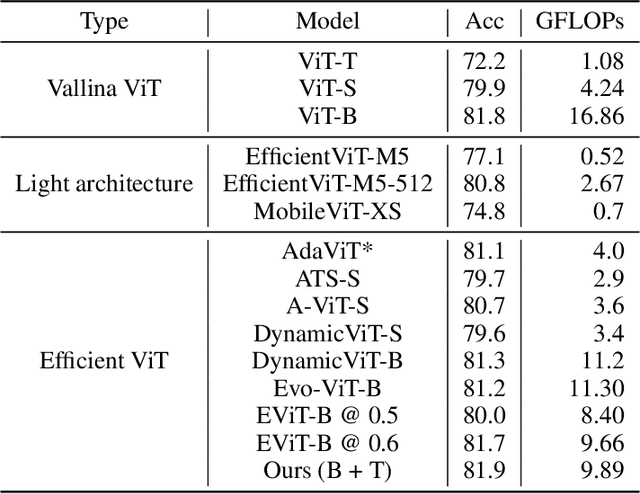
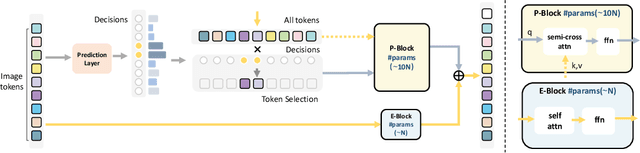

In this paper, we introduce the big.LITTLE Vision Transformer, an innovative architecture aimed at achieving efficient visual recognition. This dual-transformer system is composed of two distinct blocks: the big performance block, characterized by its high capacity and substantial computational demands, and the LITTLE efficiency block, designed for speed with lower capacity. The key innovation of our approach lies in its dynamic inference mechanism. When processing an image, our system determines the importance of each token and allocates them accordingly: essential tokens are processed by the high-performance big model, while less critical tokens are handled by the more efficient little model. This selective processing significantly reduces computational load without sacrificing the overall performance of the model, as it ensures that detailed analysis is reserved for the most important information. To validate the effectiveness of our big.LITTLE Vision Transformer, we conducted comprehensive experiments on image classification and segment anything task. Our results demonstrate that the big.LITTLE architecture not only maintains high accuracy but also achieves substantial computational savings. Specifically, our approach enables the efficient handling of large-scale visual recognition tasks by dynamically balancing the trade-offs between performance and efficiency. The success of our method underscores the potential of hybrid models in optimizing both computation and performance in visual recognition tasks, paving the way for more practical and scalable deployment of advanced neural networks in real-world applications.
Sibyl: Simple yet Effective Agent Framework for Complex Real-world Reasoning
Jul 16, 2024Existing agents based on large language models (LLMs) demonstrate robust problem-solving capabilities by integrating LLMs' inherent knowledge, strong in-context learning and zero-shot capabilities, and the use of tools combined with intricately designed LLM invocation workflows by humans. However, these agents still exhibit shortcomings in long-term reasoning and under-use the potential of existing tools, leading to noticeable deficiencies in complex real-world reasoning scenarios. To address these limitations, we introduce Sibyl, a simple yet powerful LLM-based agent framework designed to tackle complex reasoning tasks by efficiently leveraging a minimal set of tools. Drawing inspiration from Global Workspace Theory, Sibyl incorporates a global workspace to enhance the management and sharing of knowledge and conversation history throughout the system. Furthermore, guided by Society of Mind Theory, Sibyl implements a multi-agent debate-based jury to self-refine the final answers, ensuring a comprehensive and balanced approach. This approach aims to reduce system complexity while expanding the scope of problems solvable-from matters typically resolved by humans in minutes to those requiring hours or even days, thus facilitating a shift from System-1 to System-2 thinking. Sibyl has been designed with a focus on scalability and ease of debugging by incorporating the concept of reentrancy from functional programming from its inception, with the aim of seamless and low effort integration in other LLM applications to improve capabilities. Our experimental results on the GAIA benchmark test set reveal that the Sibyl agent instantiated with GPT-4 achieves state-of-the-art performance with an average score of 34.55%, compared to other agents based on GPT-4. We hope that Sibyl can inspire more reliable and reusable LLM-based agent solutions to address complex real-world reasoning tasks.