 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgebig.LITTLE Vision Transformer for Efficient Visual Recognition
Paper and Code
Oct 14, 2024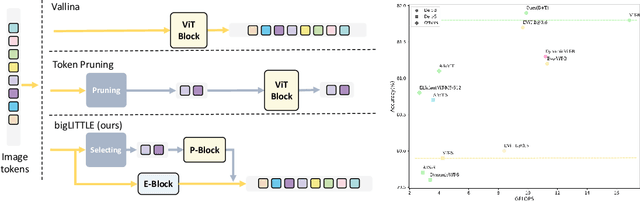
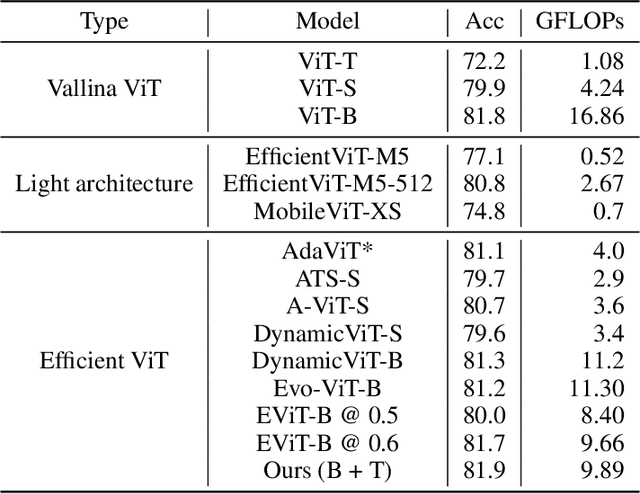
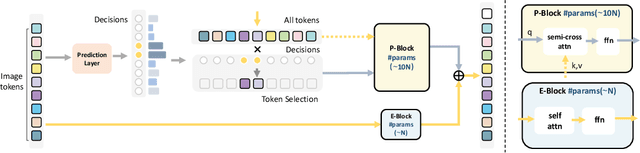

In this paper, we introduce the big.LITTLE Vision Transformer, an innovative architecture aimed at achieving efficient visual recognition. This dual-transformer system is composed of two distinct blocks: the big performance block, characterized by its high capacity and substantial computational demands, and the LITTLE efficiency block, designed for speed with lower capacity. The key innovation of our approach lies in its dynamic inference mechanism. When processing an image, our system determines the importance of each token and allocates them accordingly: essential tokens are processed by the high-performance big model, while less critical tokens are handled by the more efficient little model. This selective processing significantly reduces computational load without sacrificing the overall performance of the model, as it ensures that detailed analysis is reserved for the most important information. To validate the effectiveness of our big.LITTLE Vision Transformer, we conducted comprehensive experiments on image classification and segment anything task. Our results demonstrate that the big.LITTLE architecture not only maintains high accuracy but also achieves substantial computational savings. Specifically, our approach enables the efficient handling of large-scale visual recognition tasks by dynamically balancing the trade-offs between performance and efficiency. The success of our method underscores the potential of hybrid models in optimizing both computation and performance in visual recognition tasks, paving the way for more practical and scalable deployment of advanced neural networks in real-world applications.