 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Head to Tail: Asymmetric Knowledge Transfer in Long-tail Recommendation with Generative Semantic IDs
May 22, 2026Long-tail recommendation in real-world e-commerce platforms remains challenging due to severe data imbalance. Existing methods often struggle to combine content-based multimodal features with collaborative signals. Many of these methods also ignore an important asymmetry in knowledge transfer between head and tail IDs: noisy signals from tail IDs can hurt representation learning for head IDs. This paper presents AKT-Rec, a framework for Asymmetric Knowledge Transfer in long-tail Recommendation that uses LLM-generated semantic IDs. AKT-Rec uses Multimodal LLMs (MLLMs) with supervised fine-tuning to align content representations with collaborative information for both items and users, producing semantic representations. It then discretizes these representations into semantic IDs with a Residual-Quantized VAE (RQ-VAE), which yields semantic clusters of similar entities. AKT-Rec has two main components: (1) Cluster-Guided Adaptive Embedding, which decomposes each ID representation into a cluster-level embedding that captures shared semantics and an individual embedding. Through an asymmetric contrastive objective and an activity-aware gating mechanism, this module directs knowledge transfer from head to tail IDs. (2) Hierarchical Feature Aggregation, which builds parallel feature views and adaptively fuses them to optimize predictions for samples with varying activity levels. Extensive experiments on a large-scale industrial dataset and online A/B testing on the Alibaba Tmall platform demonstrate the effectiveness of AKT-Rec. AKT-Rec improves offline performance by 0.35% in AUC and 1.53% in GAUC, outperforming several competitive baselines. In online A/B testing, AKT-Rec achieves a 2.76% increase in CTR and a 3.47% increase in GMV, validating its utility in real-world production environments.
big.LITTLE Vision Transformer for Efficient Visual Recognition
Oct 14, 2024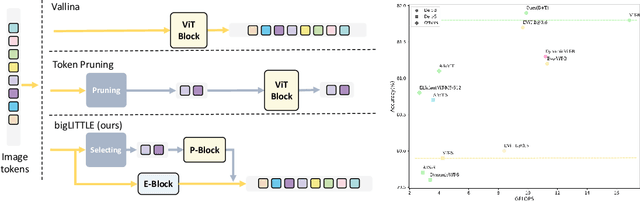
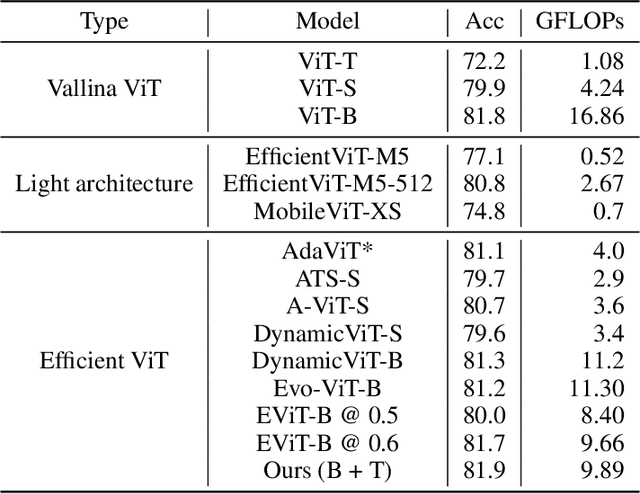
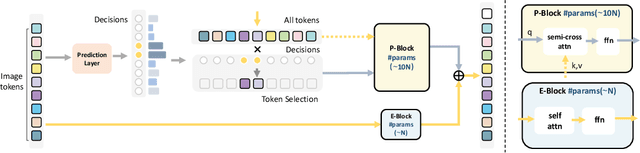

In this paper, we introduce the big.LITTLE Vision Transformer, an innovative architecture aimed at achieving efficient visual recognition. This dual-transformer system is composed of two distinct blocks: the big performance block, characterized by its high capacity and substantial computational demands, and the LITTLE efficiency block, designed for speed with lower capacity. The key innovation of our approach lies in its dynamic inference mechanism. When processing an image, our system determines the importance of each token and allocates them accordingly: essential tokens are processed by the high-performance big model, while less critical tokens are handled by the more efficient little model. This selective processing significantly reduces computational load without sacrificing the overall performance of the model, as it ensures that detailed analysis is reserved for the most important information. To validate the effectiveness of our big.LITTLE Vision Transformer, we conducted comprehensive experiments on image classification and segment anything task. Our results demonstrate that the big.LITTLE architecture not only maintains high accuracy but also achieves substantial computational savings. Specifically, our approach enables the efficient handling of large-scale visual recognition tasks by dynamically balancing the trade-offs between performance and efficiency. The success of our method underscores the potential of hybrid models in optimizing both computation and performance in visual recognition tasks, paving the way for more practical and scalable deployment of advanced neural networks in real-world applications.
In-Context Matting
Mar 23, 2024We introduce in-context matting, a novel task setting of image matting. Given a reference image of a certain foreground and guided priors such as points, scribbles, and masks, in-context matting enables automatic alpha estimation on a batch of target images of the same foreground category, without additional auxiliary input. This setting marries good performance in auxiliary input-based matting and ease of use in automatic matting, which finds a good trade-off between customization and automation. To overcome the key challenge of accurate foreground matching, we introduce IconMatting, an in-context matting model built upon a pre-trained text-to-image diffusion model. Conditioned on inter- and intra-similarity matching, IconMatting can make full use of reference context to generate accurate target alpha mattes. To benchmark the task, we also introduce a novel testing dataset ICM-$57$, covering 57 groups of real-world images. Quantitative and qualitative results on the ICM-57 testing set show that IconMatting rivals the accuracy of trimap-based matting while retaining the automation level akin to automatic matting. Code is available at https://github.com/tiny-smart/in-context-matting
Visual Encoding and Debiasing for CTR Prediction
May 09, 2022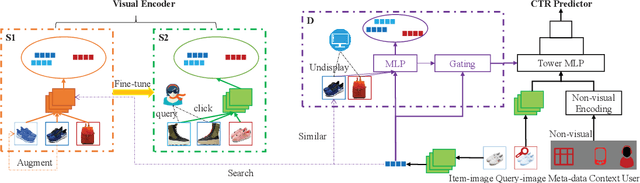
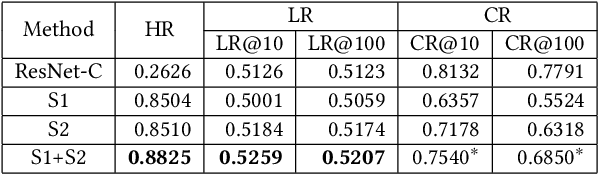

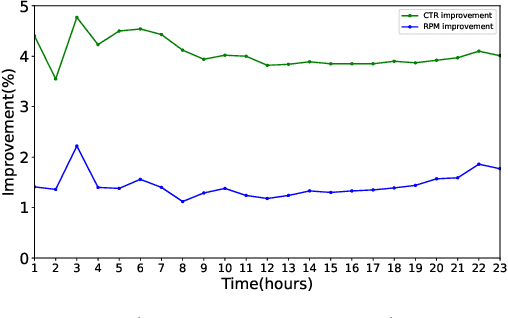
Extracting expressive visual features is crucial for accurate Click-Through-Rate (CTR) prediction in visual search advertising systems. Current commercial systems use off-the-shelf visual encoders to facilitate fast online service. However, the extracted visual features are coarse-grained and/or biased. In this paper, we present a visual encoding framework for CTR prediction to overcome these problems. The framework is based on contrastive learning which pulls positive pairs closer and pushes negative pairs apart in the visual feature space. To obtain fine-grained visual features,we present contrastive learning supervised by click through data to fine-tune the visual encoder. To reduce sample selection bias, firstly we train the visual encoder offline by leveraging both unbiased self-supervision and click supervision signals. Secondly, we incorporate a debiasing network in the online CTR predictor to adjust the visual features by contrasting high impression items with selected items with lower impressions.We deploy the framework in the visual sponsor search system at Alibaba. Offline experiments on billion-scale datasets and online experiments demonstrate that the proposed framework can make accurate and unbiased predictions.
Big Networks: A Survey
Aug 09, 2020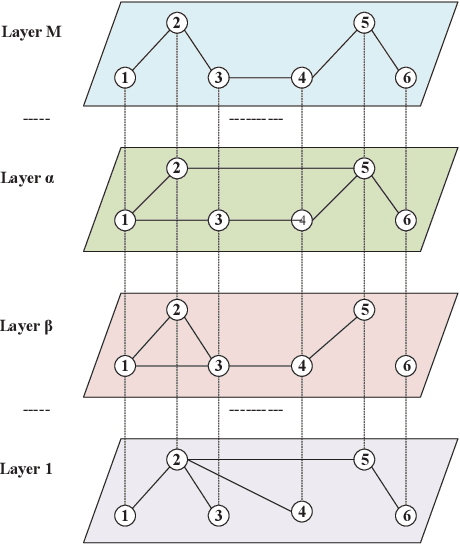

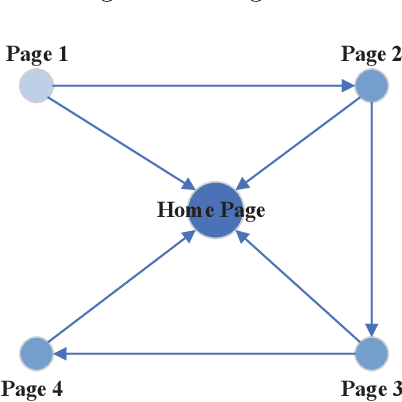

A network is a typical expressive form of representing complex systems in terms of vertices and links, in which the pattern of interactions amongst components of the network is intricate. The network can be static that does not change over time or dynamic that evolves through time. The complication of network analysis is different under the new circumstance of network size explosive increasing. In this paper, we introduce a new network science concept called big network. Big networks are generally in large-scale with a complicated and higher-order inner structure. This paper proposes a guideline framework that gives an insight into the major topics in the area of network science from the viewpoint of a big network. We first introduce the structural characteristics of big networks from three levels, which are micro-level, meso-level, and macro-level. We then discuss some state-of-the-art advanced topics of big network analysis. Big network models and related approaches, including ranking methods, partition approaches, as well as network embedding algorithms are systematically introduced. Some typical applications in big networks are then reviewed, such as community detection, link prediction, recommendation, etc. Moreover, we also pinpoint some critical open issues that need to be investigated further.
* 69 pages, 4 figures