 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Promising Tokens for Large Language Models
Feb 03, 2026Reinforcement learning (RL) has emerged as a key paradigm for aligning and optimizing large language models (LLMs). Standard approaches treat the LLM as the policy and apply RL directly over the full vocabulary space. However, this formulation includes the massive tail of contextually irrelevant tokens in the action space, which could distract the policy from focusing on decision-making among the truly reasonable tokens. In this work, we verify that valid reasoning paths could inherently concentrate within a low-rank subspace. Based on this insight, we introduce Reinforcement Learning with Promising Tokens (RLPT), a framework that mitigates the action space issue by decoupling strategic decision-making from token generation. Specifically, RLPT leverages the semantic priors of the base model to identify a dynamic set of \emph{promising tokens} and constrains policy optimization exclusively to this refined subset via masking. Theoretical analysis and empirical results demonstrate that RLPT effectively reduces gradient variance, stabilizes the training process, and improves sample efficiency. Experiment results on math, coding, and telecom reasoning show that RLPT outperforms standard RL baselines and integrates effectively across various model sizes (4B and 8B) and RL algorithms (GRPO and DAPO).
LFS: Learnable Frame Selector for Event-Aware and Temporally Diverse Video Captioning
Jan 21, 2026Video captioning models convert frames into visual tokens and generate descriptions with large language models (LLMs). Since encoding all frames is prohibitively expensive, uniform sampling is the default choice, but it enforces equal temporal coverage while ignoring the uneven events distribution. This motivates a Learnable Frame Selector (LFS) that selects temporally diverse and event-relevant frames. LFS explicitly models temporal importance to balance temporal diversity and event relevance, and employs a stratified strategy to ensure temporal coverage while avoiding clustering. Crucially, LFS leverages caption feedback from frozen video-LLMs to learn frame selection that directly optimizes downstream caption quality. Additionally, we identify the gap between existing benchmark and human's cognition. Thus, we introduce ICH-CC built from carefully designed questions by annotators that reflect human-consistent understanding of video. Experiments indicate that LFS consistently improves detailed video captioning across two representative community benchmarks and ICH-CC, achieving up to 2.0% gains on VDC and over 4% gains on ICH-CC. Moreover, we observe that enhanced captions with LFS leads to improved performance on video question answering. Overall, LFS provides an effective and easy-to-integrate solution for detailed video captioning.
Multi-Modal LLM based Image Captioning in ICT: Bridging the Gap Between General and Industry Domain
Jan 14, 2026In the information and communications technology (ICT) industry, training a domain-specific large language model (LLM) or constructing a retrieval-augmented generation system requires a substantial amount of high-value domain knowledge. However, the knowledge is not only hidden in the textual modality but also in the image modality. Traditional methods can parse text from domain documents but dont have image captioning ability. Multi-modal LLM (MLLM) can understand images, but they do not have sufficient domain knowledge. To address the above issues, this paper proposes a multi-stage progressive training strategy to train a Domain-specific Image Captioning Model (DICModel) in ICT, and constructs a standard evaluation system to validate the performance of DICModel. Specifically, this work first synthesizes about 7K image-text pairs by combining the Mermaid tool and LLMs, which are used for the first-stage supervised-fine-tuning (SFT) of DICModel. Then, ICT-domain experts manually annotate about 2K image-text pairs for the second-stage SFT of DICModel. Finally, experts and LLMs jointly synthesize about 1.5K visual question answering data for the instruction-based SFT. Experimental results indicate that our DICModel with only 7B parameters performs better than other state-of-the-art models with 32B parameters. Compared to the SOTA models with 7B and 32B parameters, our DICModel increases the BLEU metric by approximately 56.8% and 20.8%, respectively. On the objective questions constructed by ICT domain experts, our DICModel outperforms Qwen2.5-VL 32B by 1% in terms of accuracy rate. In summary, this work can efficiently and accurately extract the logical text from images, which is expected to promote the development of multimodal models in the ICT domain.
EDCO: Dynamic Curriculum Orchestration for Domain-specific Large Language Model Fine-tuning
Jan 07, 2026Domain-specific large language models (LLMs), typically developed by fine-tuning a pre-trained general-purpose LLM on specialized datasets, represent a significant advancement in applied AI. A common strategy in LLM fine-tuning is curriculum learning, which pre-orders training samples based on metrics like difficulty to improve learning efficiency compared to a random sampling strategy. However, most existing methods for LLM fine-tuning rely on a static curriculum, designed prior to training, which lacks adaptability to the model's evolving needs during fine-tuning. To address this, we propose EDCO, a novel framework based on two key concepts: inference entropy and dynamic curriculum orchestration. Inspired by recent findings that maintaining high answer entropy benefits long-term reasoning gains, EDCO prioritizes samples with high inference entropy in a continuously adapted curriculum. EDCO integrates three core components: an efficient entropy estimator that uses prefix tokens to approximate full-sequence entropy, an entropy-based curriculum generator that selects data points with the highest inference entropy, and an LLM trainer that optimizes the model on the selected curriculum. Comprehensive experiments in communication, medicine and law domains, EDCO outperforms traditional curriculum strategies for fine-tuning Qwen3-4B and Llama3.2-3B models under supervised and reinforcement learning settings. Furthermore, the proposed efficient entropy estimation reduces computational time by 83.5% while maintaining high accuracy.
Mem-PAL: Towards Memory-based Personalized Dialogue Assistants for Long-term User-Agent Interaction
Nov 17, 2025With the rise of smart personal devices, service-oriented human-agent interactions have become increasingly prevalent. This trend highlights the need for personalized dialogue assistants that can understand user-specific traits to accurately interpret requirements and tailor responses to individual preferences. However, existing approaches often overlook the complexities of long-term interactions and fail to capture users' subjective characteristics. To address these gaps, we present PAL-Bench, a new benchmark designed to evaluate the personalization capabilities of service-oriented assistants in long-term user-agent interactions. In the absence of available real-world data, we develop a multi-step LLM-based synthesis pipeline, which is further verified and refined by human annotators. This process yields PAL-Set, the first Chinese dataset comprising multi-session user logs and dialogue histories, which serves as the foundation for PAL-Bench. Furthermore, to improve personalized service-oriented interactions, we propose H$^2$Memory, a hierarchical and heterogeneous memory framework that incorporates retrieval-augmented generation to improve personalized response generation. Comprehensive experiments on both our PAL-Bench and an external dataset demonstrate the effectiveness of the proposed memory framework.
CTR-Driven Ad Text Generation via Online Feedback Preference Optimization
Jul 27, 2025Advertising text plays a critical role in determining click-through rates (CTR) in online advertising. Large Language Models (LLMs) offer significant efficiency advantages over manual ad text creation. However, LLM-generated ad texts do not guarantee higher CTR performance compared to human-crafted texts, revealing a gap between generation quality and online performance of ad texts. In this work, we propose a novel ad text generation method which optimizes for CTR through preference optimization from online feedback. Our approach adopts an innovative two-stage framework: (1) diverse ad text sampling via one-shot in-context learning, using retrieval-augmented generation (RAG) to provide exemplars with chain-of-thought (CoT) reasoning; (2) CTR-driven preference optimization from online feedback, which weighs preference pairs according to their CTR gains and confidence levels. Through our method, the resulting model enables end-to-end generation of high-CTR ad texts. Extensive experiments have demonstrated the effectiveness of our method in both offline and online metrics. Notably, we have applied our method on a large-scale online shopping platform and achieved significant CTR improvements, showcasing its strong applicability and effectiveness in advertising systems.
Differentiable Solver Search for Fast Diffusion Sampling
May 27, 2025Diffusion models have demonstrated remarkable generation quality but at the cost of numerous function evaluations. Recently, advanced ODE-based solvers have been developed to mitigate the substantial computational demands of reverse-diffusion solving under limited sampling steps. However, these solvers, heavily inspired by Adams-like multistep methods, rely solely on t-related Lagrange interpolation. We show that t-related Lagrange interpolation is suboptimal for diffusion model and reveal a compact search space comprised of time steps and solver coefficients. Building on our analysis, we propose a novel differentiable solver search algorithm to identify more optimal solver. Equipped with the searched solver, rectified-flow models, e.g., SiT-XL/2 and FlowDCN-XL/2, achieve FID scores of 2.40 and 2.35, respectively, on ImageNet256 with only 10 steps. Meanwhile, DDPM model, DiT-XL/2, reaches a FID score of 2.33 with only 10 steps. Notably, our searched solver outperforms traditional solvers by a significant margin. Moreover, our searched solver demonstrates generality across various model architectures, resolutions, and model sizes.
DMM: Building a Versatile Image Generation Model via Distillation-Based Model Merging
Apr 16, 2025The success of text-to-image (T2I) generation models has spurred a proliferation of numerous model checkpoints fine-tuned from the same base model on various specialized datasets. This overwhelming specialized model production introduces new challenges for high parameter redundancy and huge storage cost, thereby necessitating the development of effective methods to consolidate and unify the capabilities of diverse powerful models into a single one. A common practice in model merging adopts static linear interpolation in the parameter space to achieve the goal of style mixing. However, it neglects the features of T2I generation task that numerous distinct models cover sundry styles which may lead to incompatibility and confusion in the merged model. To address this issue, we introduce a style-promptable image generation pipeline which can accurately generate arbitrary-style images under the control of style vectors. Based on this design, we propose the score distillation based model merging paradigm (DMM), compressing multiple models into a single versatile T2I model. Moreover, we rethink and reformulate the model merging task in the context of T2I generation, by presenting new merging goals and evaluation protocols. Our experiments demonstrate that DMM can compactly reorganize the knowledge from multiple teacher models and achieve controllable arbitrary-style generation.
SceneBooth: Diffusion-based Framework for Subject-preserved Text-to-Image Generation
Jan 07, 2025



Due to the demand for personalizing image generation, subject-driven text-to-image generation method, which creates novel renditions of an input subject based on text prompts, has received growing research interest. Existing methods often learn subject representation and incorporate it into the prompt embedding to guide image generation, but they struggle with preserving subject fidelity. To solve this issue, this paper approaches a novel framework named SceneBooth for subject-preserved text-to-image generation, which consumes inputs of a subject image, object phrases and text prompts. Instead of learning the subject representation and generating a subject, our SceneBooth fixes the given subject image and generates its background image guided by the text prompts. To this end, our SceneBooth introduces two key components, i.e., a multimodal layout generation module and a background painting module. The former determines the position and scale of the subject by generating appropriate scene layouts that align with text captions, object phrases, and subject visual information. The latter integrates two adapters (ControlNet and Gated Self-Attention) into the latent diffusion model to generate a background that harmonizes with the subject guided by scene layouts and text descriptions. In this manner, our SceneBooth ensures accurate preservation of the subject's appearance in the output. Quantitative and qualitative experimental results demonstrate that SceneBooth significantly outperforms baseline methods in terms of subject preservation, image harmonization and overall quality.
FlowDCN: Exploring DCN-like Architectures for Fast Image Generation with Arbitrary Resolution
Oct 30, 2024


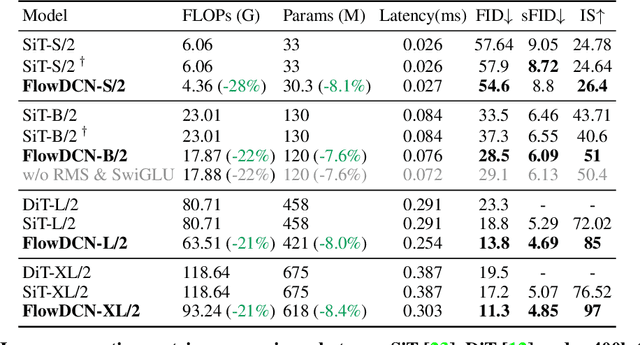
Arbitrary-resolution image generation still remains a challenging task in AIGC, as it requires handling varying resolutions and aspect ratios while maintaining high visual quality. Existing transformer-based diffusion methods suffer from quadratic computation cost and limited resolution extrapolation capabilities, making them less effective for this task. In this paper, we propose FlowDCN, a purely convolution-based generative model with linear time and memory complexity, that can efficiently generate high-quality images at arbitrary resolutions. Equipped with a new design of learnable group-wise deformable convolution block, our FlowDCN yields higher flexibility and capability to handle different resolutions with a single model. FlowDCN achieves the state-of-the-art 4.30 sFID on $256\times256$ ImageNet Benchmark and comparable resolution extrapolation results, surpassing transformer-based counterparts in terms of convergence speed (only $\frac{1}{5}$ images), visual quality, parameters ($8\%$ reduction) and FLOPs ($20\%$ reduction). We believe FlowDCN offers a promising solution to scalable and flexible image synthesis.