 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Prompt Following with Visual Control Through Training-Free Mask-Guided Diffusion
Apr 23, 2024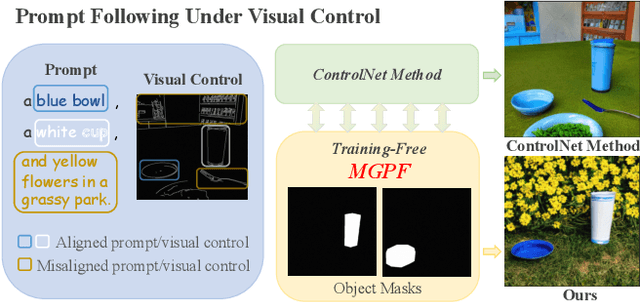
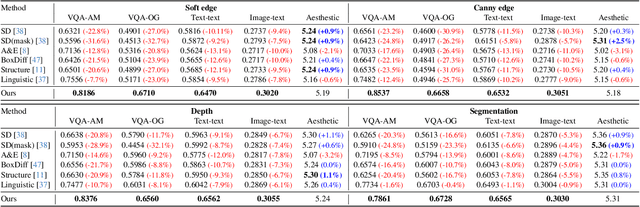
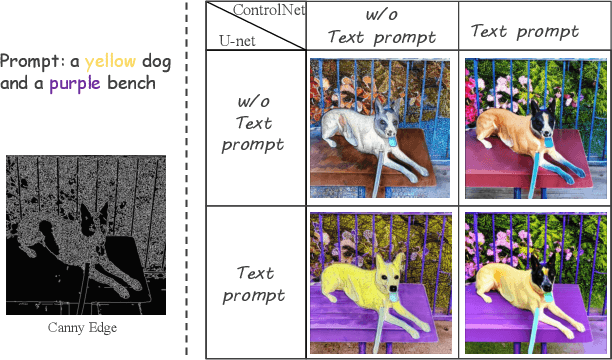
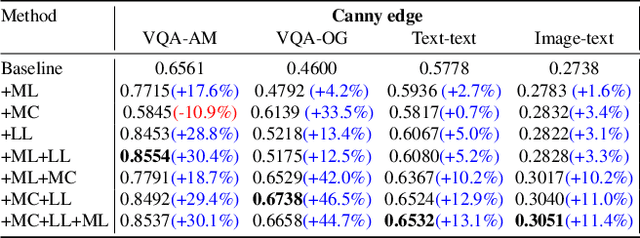
Recently, integrating visual controls into text-to-image~(T2I) models, such as ControlNet method, has received significant attention for finer control capabilities. While various training-free methods make efforts to enhance prompt following in T2I models, the issue with visual control is still rarely studied, especially in the scenario that visual controls are misaligned with text prompts. In this paper, we address the challenge of ``Prompt Following With Visual Control" and propose a training-free approach named Mask-guided Prompt Following (MGPF). Object masks are introduced to distinct aligned and misaligned parts of visual controls and prompts. Meanwhile, a network, dubbed as Masked ControlNet, is designed to utilize these object masks for object generation in the misaligned visual control region. Further, to improve attribute matching, a simple yet efficient loss is designed to align the attention maps of attributes with object regions constrained by ControlNet and object masks. The efficacy and superiority of MGPF are validated through comprehensive quantitative and qualitative experiments.
Human-centric Behavior Description in Videos: New Benchmark and Model
Oct 04, 2023



In the domain of video surveillance, describing the behavior of each individual within the video is becoming increasingly essential, especially in complex scenarios with multiple individuals present. This is because describing each individual's behavior provides more detailed situational analysis, enabling accurate assessment and response to potential risks, ensuring the safety and harmony of public places. Currently, video-level captioning datasets cannot provide fine-grained descriptions for each individual's specific behavior. However, mere descriptions at the video-level fail to provide an in-depth interpretation of individual behaviors, making it challenging to accurately determine the specific identity of each individual. To address this challenge, we construct a human-centric video surveillance captioning dataset, which provides detailed descriptions of the dynamic behaviors of 7,820 individuals. Specifically, we have labeled several aspects of each person, such as location, clothing, and interactions with other elements in the scene, and these people are distributed across 1,012 videos. Based on this dataset, we can link individuals to their respective behaviors, allowing for further analysis of each person's behavior in surveillance videos. Besides the dataset, we propose a novel video captioning approach that can describe individual behavior in detail on a person-level basis, achieving state-of-the-art results. To facilitate further research in this field, we intend to release our dataset and code.
S3C: Semi-Supervised VQA Natural Language Explanation via Self-Critical Learning
Sep 05, 2023VQA Natural Language Explanation (VQA-NLE) task aims to explain the decision-making process of VQA models in natural language. Unlike traditional attention or gradient analysis, free-text rationales can be easier to understand and gain users' trust. Existing methods mostly use post-hoc or self-rationalization models to obtain a plausible explanation. However, these frameworks are bottlenecked by the following challenges: 1) the reasoning process cannot be faithfully responded to and suffer from the problem of logical inconsistency. 2) Human-annotated explanations are expensive and time-consuming to collect. In this paper, we propose a new Semi-Supervised VQA-NLE via Self-Critical Learning (S3C), which evaluates the candidate explanations by answering rewards to improve the logical consistency between answers and rationales. With a semi-supervised learning framework, the S3C can benefit from a tremendous amount of samples without human-annotated explanations. A large number of automatic measures and human evaluations all show the effectiveness of our method. Meanwhile, the framework achieves a new state-of-the-art performance on the two VQA-NLE datasets.
Dual-Level Decoupled Transformer for Video Captioning
May 06, 2022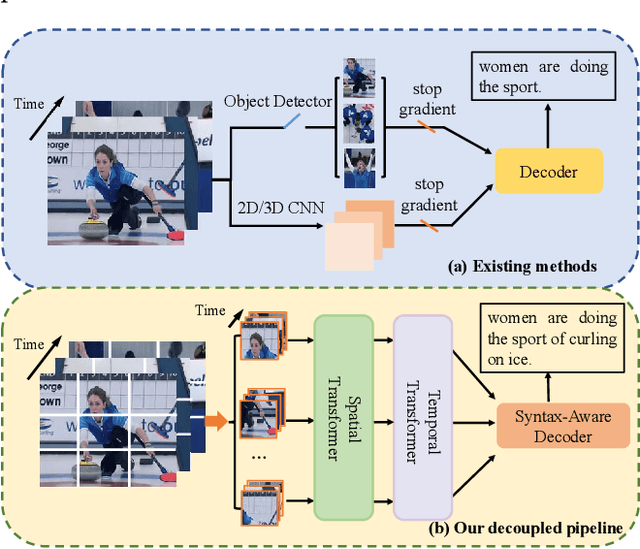
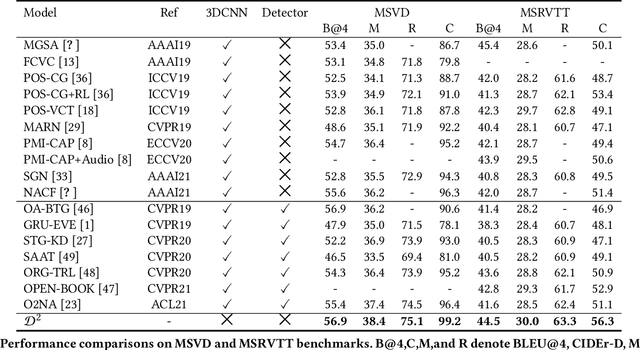
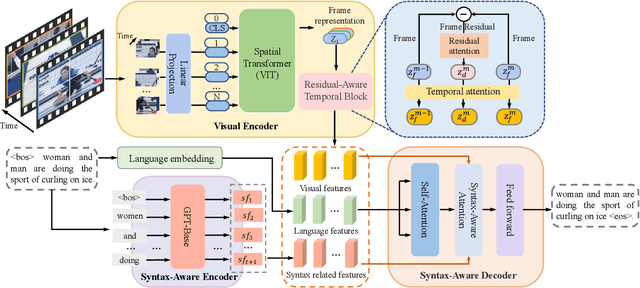
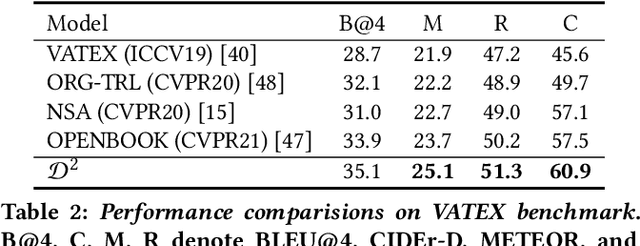
Video captioning aims to understand the spatio-temporal semantic concept of the video and generate descriptive sentences. The de-facto approach to this task dictates a text generator to learn from \textit{offline-extracted} motion or appearance features from \textit{pre-trained} vision models. However, these methods may suffer from the so-called \textbf{\textit{"couple"}} drawbacks on both \textit{video spatio-temporal representation} and \textit{sentence generation}. For the former, \textbf{\textit{"couple"}} means learning spatio-temporal representation in a single model(3DCNN), resulting the problems named \emph{disconnection in task/pre-train domain} and \emph{hard for end-to-end training}. As for the latter, \textbf{\textit{"couple"}} means treating the generation of visual semantic and syntax-related words equally. To this end, we present $\mathcal{D}^{2}$ - a dual-level decoupled transformer pipeline to solve the above drawbacks: \emph{(i)} for video spatio-temporal representation, we decouple the process of it into "first-spatial-then-temporal" paradigm, releasing the potential of using dedicated model(\textit{e.g.} image-text pre-training) to connect the pre-training and downstream tasks, and makes the entire model end-to-end trainable. \emph{(ii)} for sentence generation, we propose \emph{Syntax-Aware Decoder} to dynamically measure the contribution of visual semantic and syntax-related words. Extensive experiments on three widely-used benchmarks (MSVD, MSR-VTT and VATEX) have shown great potential of the proposed $\mathcal{D}^{2}$ and surpassed the previous methods by a large margin in the task of video captioning.
CapOnImage: Context-driven Dense-Captioning on Image
Apr 27, 2022
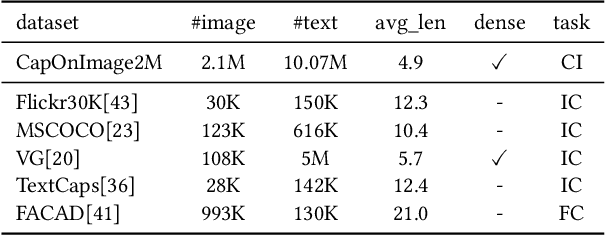
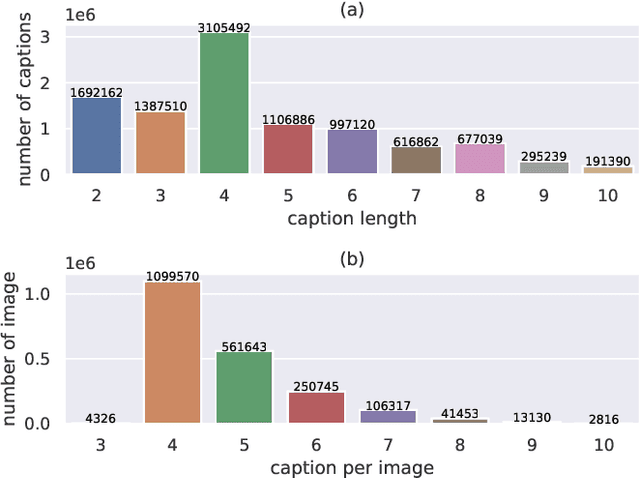
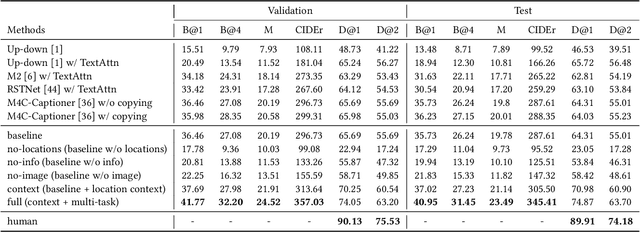
Existing image captioning systems are dedicated to generating narrative captions for images, which are spatially detached from the image in presentation. However, texts can also be used as decorations on the image to highlight the key points and increase the attractiveness of images. In this work, we introduce a new task called captioning on image (CapOnImage), which aims to generate dense captions at different locations of the image based on contextual information. To fully exploit the surrounding visual context to generate the most suitable caption for each location, we propose a multi-modal pre-training model with multi-level pre-training tasks that progressively learn the correspondence between texts and image locations from easy to difficult. Since the model may generate redundant captions for nearby locations, we further enhance the location embedding with neighbor locations as context. For this new task, we also introduce a large-scale benchmark called CapOnImage2M, which contains 2.1 million product images, each with an average of 4.8 spatially localized captions. Compared with other image captioning model variants, our model achieves the best results in both captioning accuracy and diversity aspects. We will make code and datasets public to facilitate future research.