 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Second Challenge on Real-World Face Restoration at NTIRE 2026: Methods and Results
Apr 12, 2026This paper provides a review of the NTIRE 2026 challenge on real-world face restoration, highlighting the proposed solutions and the resulting outcomes. The challenge focuses on generating natural and realistic outputs while maintaining identity consistency. Its goal is to advance state-of-the-art solutions for perceptual quality and realism, without imposing constraints on computational resources or training data. Performance is evaluated using a weighted image quality assessment (IQA) score and employs the AdaFace model as an identity checker. The competition attracted 96 registrants, with 10 teams submitting valid models; ultimately, 9 teams achieved valid scores in the final ranking. This collaborative effort advances the performance of real-world face restoration while offering an in-depth overview of the latest trends in the field.
Hallucination-aware intermediate representation edit in large vision-language models
Mar 31, 2026Large Vision-Language Models have demonstrated exceptional performance in multimodal reasoning and complex scene understanding. However, these models still face significant hallucination issues, where outputs contradict visual facts. Recent research on hallucination mitigation has focused on retraining methods and Contrastive Decoding (CD) methods. While both methods perform well, retraining methods require substantial training resources, and CD methods introduce dual inference overhead. These factors hinder their practical applicability. To address the above issue, we propose a framework for dynamically detecting hallucination representations and performing hallucination-eliminating edits on these representations. With minimal additional computational cost, we achieve state-of-the-art performance on existing benchmarks. Extensive experiments demonstrate the effectiveness of our approach, highlighting its efficient and robust hallucination elimination capability and its powerful controllability over hallucinations. Code is available at https://github.com/ASGO-MM/HIRE
Understanding and Mitigating Hallucinations in Multimodal Chain-of-Thought Models
Mar 28, 2026Multimodal Chain-of-Thought (MCoT) models have demonstrated impressive capability in complex visual reasoning tasks. Unfortunately, recent studies reveal that they suffer from severe hallucination problems due to diminished visual attention during the generation process. However, visual attention decay is a well-studied problem in Large Vision-Language Models (LVLMs). Considering the fundamental differences in reasoning processes between MCoT models and traditional LVLMs, we raise a basic question: Whether MCoT models have unique causes of hallucinations? To answer this question, we systematically investigate the hallucination patterns of MCoT models and find that fabricated texts are primarily generated in associative reasoning steps, which we term divergent thinking. Leveraging these insights, we introduce a simple yet effective strategy that can effectively localize divergent thinking steps and intervene in the decoding process to mitigate hallucinations. Extensive experiments show that our method outperforms existing methods by a large margin. More importantly, our proposed method can be conveniently integrated with other hallucination mitigation methods and further boost their performance. The code is publicly available at https://github.com/ASGO-MM/MCoT-hallucination.
Towards Video Anomaly Detection from Event Streams: A Baseline and Benchmark Datasets
Mar 26, 2026Event-based vision, characterized by low redundancy, focus on dynamic motion, and inherent privacy-preserving properties, naturally fits the demands of video anomaly detection (VAD). However, the absence of dedicated event-stream anomaly detection datasets and effective modeling strategies has significantly hindered progress in this field. In this work, we take the first major step toward establishing event-based VAD as a unified research direction. We first construct multiple event-stream based benchmarks for video anomaly detection, featuring synchronized event and RGB recordings. Leveraging the unique properties of events, we then propose an EVent-centric spatiotemporal Video Anomaly Detection framework, namely EWAD, with three key innovations: an event density aware dynamic sampling strategy to select temporally informative segments; a density-modulated temporal modeling approach that captures contextual relations from sparse event streams; and an RGB-to-event knowledge distillation mechanism to enhance event-based representations under weak supervision. Extensive experiments on three benchmarks demonstrate that our EWAD achieves significant improvements over existing approaches, highlighting the potential and effectiveness of event-driven modeling for video anomaly detection. The benchmark datasets will be made publicly available.
DualTSR: Unified Dual-Diffusion Transformer for Scene Text Image Super-Resolution
Mar 15, 2026Scene Text Image Super-Resolution (STISR) aims to restore high-resolution details in low-resolution text images, which is crucial for both human readability and machine recognition. Existing methods, however, often depend on external Optical Character Recognition (OCR) models for textual priors or rely on complex multi-component architectures that are difficult to train and reproduce. In this paper, we introduce DualTSR, a unified end-to-end framework that addresses both issues. DualTSR employs a single multimodal transformer backbone trained with a dual diffusion objective. It simultaneously models the continuous distribution of high-resolution images via Conditional Flow Matching and the discrete distribution of textual content via discrete diffusion. This shared design enables visual and textual information to interact at every layer, allowing the model to infer text priors internally instead of relying on an external OCR module. Compared with prior multi-branch diffusion systems, DualTSR offers a simpler end-to-end formulation with fewer hand-crafted components. Experiments on synthetic Chinese benchmarks and a curated real-world evaluation protocol show that DualTSR achieves strong perceptual quality and text fidelity.
Knowing the Unknown: Interpretable Open-World Object Detection via Concept Decomposition Model
Feb 24, 2026Open-world object detection (OWOD) requires incrementally detecting known categories while reliably identifying unknown objects. Existing methods primarily focus on improving unknown recall, yet overlook interpretability, often leading to known-unknown confusion and reduced prediction reliability. This paper aims to make the entire OWOD framework interpretable, enabling the detector to truly "knowing the unknown". To this end, we propose a concept-driven InterPretable OWOD framework(IPOW) by introducing a Concept Decomposition Model (CDM) for OWOD, which explicitly decomposes the coupled RoI features in Faster R-CNN into discriminative, shared, and background concepts. Discriminative concepts identify the most discriminative features to enlarge the distances between known categories, while shared and background concepts, due to their strong generalization ability, can be readily transferred to detect unknown categories. Leveraging the interpretable framework, we identify that known-unknown confusion arises when unknown objects fall into the discriminative space of known classes. To address this, we propose Concept-Guided Rectification (CGR) to further resolve such confusion. Extensive experiments show that IPOW significantly improves unknown recall while mitigating confusion, and provides concept-level interpretability for both known and unknown predictions.
YOLO-IOD: Towards Real Time Incremental Object Detection
Dec 28, 2025Current methods for incremental object detection (IOD) primarily rely on Faster R-CNN or DETR series detectors; however, these approaches do not accommodate the real-time YOLO detection frameworks. In this paper, we first identify three primary types of knowledge conflicts that contribute to catastrophic forgetting in YOLO-based incremental detectors: foreground-background confusion, parameter interference, and misaligned knowledge distillation. Subsequently, we introduce YOLO-IOD, a real-time Incremental Object Detection (IOD) framework that is constructed upon the pretrained YOLO-World model, facilitating incremental learning via a stage-wise parameter-efficient fine-tuning process. Specifically, YOLO-IOD encompasses three principal components: 1) Conflict-Aware Pseudo-Label Refinement (CPR), which mitigates the foreground-background confusion by leveraging the confidence levels of pseudo labels and identifying potential objects relevant to future tasks. 2) Importancebased Kernel Selection (IKS), which identifies and updates the pivotal convolution kernels pertinent to the current task during the current learning stage. 3) Cross-Stage Asymmetric Knowledge Distillation (CAKD), which addresses the misaligned knowledge distillation conflict by transmitting the features of the student target detector through the detection heads of both the previous and current teacher detectors, thereby facilitating asymmetric distillation between existing and newly introduced categories. We further introduce LoCo COCO, a more realistic benchmark that eliminates data leakage across stages. Experiments on both conventional and LoCo COCO benchmarks show that YOLO-IOD achieves superior performance with minimal forgetting.
GMODiff: One-Step Gain Map Refinement with Diffusion Priors for HDR Reconstruction
Dec 18, 2025

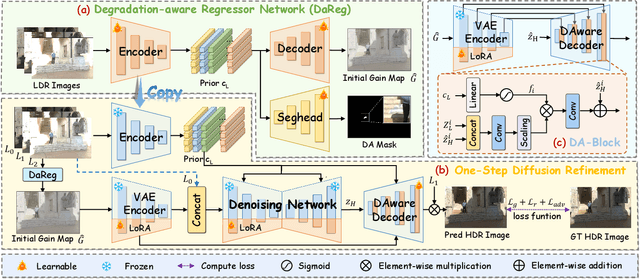

Pre-trained Latent Diffusion Models (LDMs) have recently shown strong perceptual priors for low-level vision tasks, making them a promising direction for multi-exposure High Dynamic Range (HDR) reconstruction. However, directly applying LDMs to HDR remains challenging due to: (1) limited dynamic-range representation caused by 8-bit latent compression, (2) high inference cost from multi-step denoising, and (3) content hallucination inherent to generative nature. To address these challenges, we introduce GMODiff, a gain map-driven one-step diffusion framework for multi-exposure HDR reconstruction. Instead of reconstructing full HDR content, we reformulate HDR reconstruction as a conditionally guided Gain Map (GM) estimation task, where the GM encodes the extended dynamic range while retaining the same bit depth as LDR images. We initialize the denoising process from an informative regression-based estimate rather than pure noise, enabling the model to generate high-quality GMs in a single denoising step. Furthermore, recognizing that regression-based models excel in content fidelity while LDMs favor perceptual quality, we leverage regression priors to guide both the denoising process and latent decoding of the LDM, suppressing hallucinations while preserving structural accuracy. Extensive experiments demonstrate that our GMODiff performs favorably against several state-of-the-art methods and is 100 faster than previous LDM-based methods.
SOMA: Feature Gradient Enhanced Affine-Flow Matching for SAR-Optical Registration
Nov 17, 2025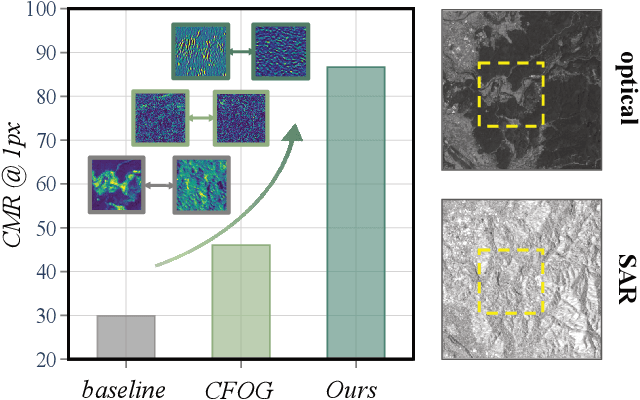
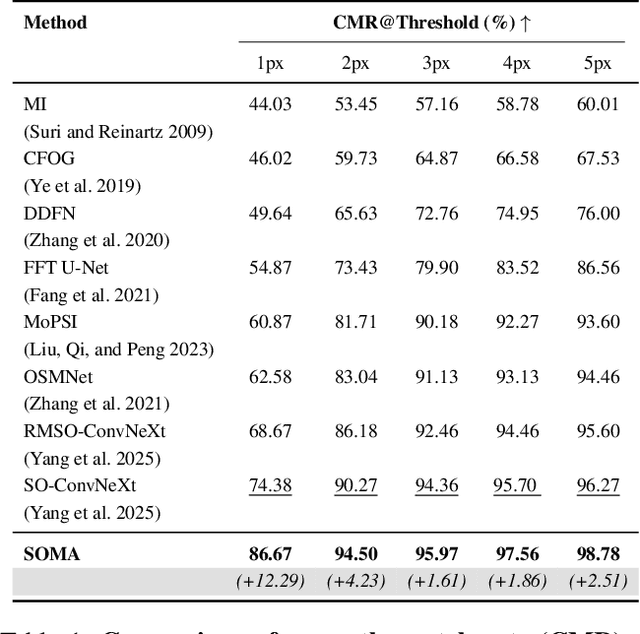
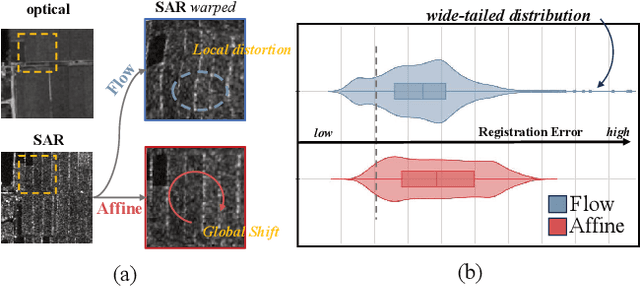
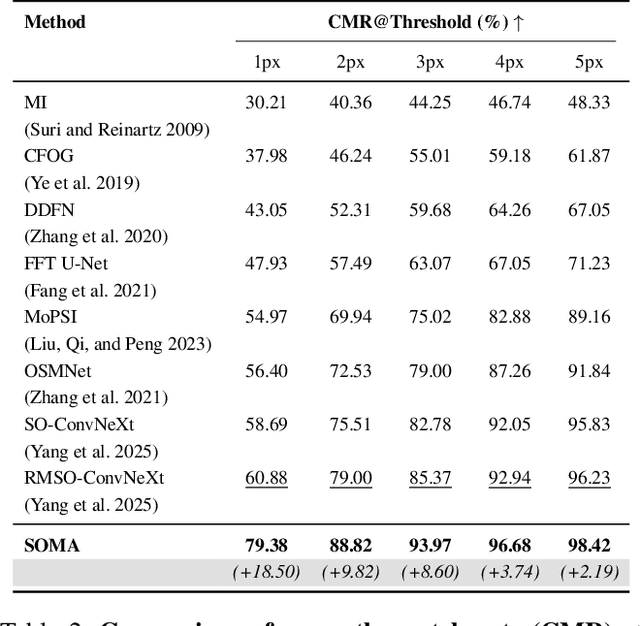
Achieving pixel-level registration between SAR and optical images remains a challenging task due to their fundamentally different imaging mechanisms and visual characteristics. Although deep learning has achieved great success in many cross-modal tasks, its performance on SAR-Optical registration tasks is still unsatisfactory. Gradient-based information has traditionally played a crucial role in handcrafted descriptors by highlighting structural differences. However, such gradient cues have not been effectively leveraged in deep learning frameworks for SAR-Optical image matching. To address this gap, we propose SOMA, a dense registration framework that integrates structural gradient priors into deep features and refines alignment through a hybrid matching strategy. Specifically, we introduce the Feature Gradient Enhancer (FGE), which embeds multi-scale, multi-directional gradient filters into the feature space using attention and reconstruction mechanisms to boost feature distinctiveness. Furthermore, we propose the Global-Local Affine-Flow Matcher (GLAM), which combines affine transformation and flow-based refinement within a coarse-to-fine architecture to ensure both structural consistency and local accuracy. Experimental results demonstrate that SOMA significantly improves registration precision, increasing the CMR@1px by 12.29% on the SEN1-2 dataset and 18.50% on the GFGE_SO dataset. In addition, SOMA exhibits strong robustness and generalizes well across diverse scenes and resolutions.
FreDFT: Frequency Domain Fusion Transformer for Visible-Infrared Object Detection
Nov 14, 2025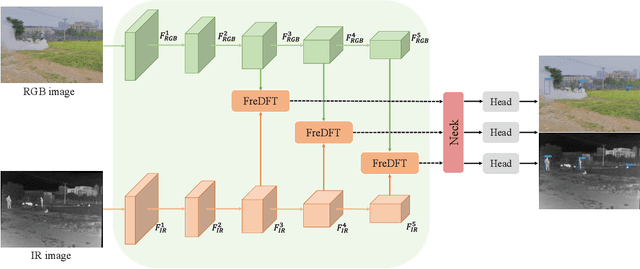

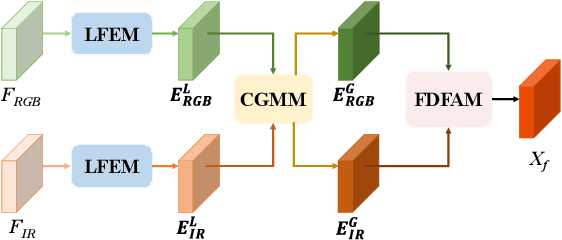
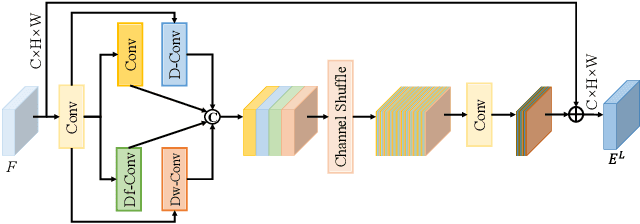
Visible-infrared object detection has gained sufficient attention due to its detection performance in low light, fog, and rain conditions. However, visible and infrared modalities captured by different sensors exist the information imbalance problem in complex scenarios, which can cause inadequate cross-modal fusion, resulting in degraded detection performance. \textcolor{red}{Furthermore, most existing methods use transformers in the spatial domain to capture complementary features, ignoring the advantages of developing frequency domain transformers to mine complementary information.} To solve these weaknesses, we propose a frequency domain fusion transformer, called FreDFT, for visible-infrared object detection. The proposed approach employs a novel multimodal frequency domain attention (MFDA) to mine complementary information between modalities and a frequency domain feed-forward layer (FDFFL) via a mixed-scale frequency feature fusion strategy is designed to better enhance multimodal features. To eliminate the imbalance of multimodal information, a cross-modal global modeling module (CGMM) is constructed to perform pixel-wise inter-modal feature interaction in a spatial and channel manner. Moreover, a local feature enhancement module (LFEM) is developed to strengthen multimodal local feature representation and promote multimodal feature fusion by using various convolution layers and applying a channel shuffle. Extensive experimental results have verified that our proposed FreDFT achieves excellent performance on multiple public datasets compared with other state-of-the-art methods. The code of our FreDFT is linked at https://github.com/WenCongWu/FreDFT.