 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Guided Dual-Domain Learning for Reliable Skin Lesion Segmentation
May 10, 2026Accurate skin lesion segmentation is vital for dermoscopic Computer-Aided Diagnosis. However, visual ambiguity and morphological irregularity often defeat spatial modeling, necessitating multi-domain architectures. Existing paradigms frequently overlook the active use of prediction uncertainty, leading to deterministic frameworks that suffer from blind cross-domain fusion and overfit to label noise. To address these issues, we propose the Uncertainty-Guided Dual-Domain Network (UGDD-Net). UGDD-Net introduces a novel "Glance-and-Gaze" mechanism to transform uncertainty into an active guiding signal. Specifically, the Uncertainty-Guided Bi-directional Feature Fusion (UGBFF) module uses pixel-level uncertainty to modulate spatial-spectral interactions. The Uncertainty-Guided Graph Refinement (UGGR) module constructs a topology-aware graph to propagate reliable semantic consensus and refine uncertain nodes. Finally, the Uncertainty-Guided Margin-Adaptive Loss (UGML) enforces strict constraints on confident pixels while relaxing penalties on uncertain ones to improve statistical calibration. Extensive experiments on ISIC2017, ISIC2018, PH2, and HAM10000 datasets demonstrate that UGDD-Net achieves state-of-the-art performance, especially on "Hard Samples". Our uncertainty maps align with expert inter-observer variability, providing robust interpretability for human-machine collaborative diagnosis.
EAPFusion: Intrinsic Evolving Auxiliary Prior Guidance for Infrared and Visible Image Fusion
May 03, 2026Infrared-visible image fusion aims to create an information-rich fused image by integrating the complementary thermal saliency from infrared sensing and fine textures from visible imaging. Such accurate fusion is essential for real-world perception applications in complex scenes, including nighttime autonomous driving, search and rescue, and surveillance, and can further benefit downstream tasks such as semantic segmentation. However, most existing fusion methods rely upon static trained weights that cannot adapt to scene-specific content at inference time, and often suffer from a granularity mismatch when coarse auxiliary semantics are injected, which makes it difficult to simultaneously highlight targets and preserve details. In this work, we propose EAPFusion to address these issues by using self-evolving intrinsic priors instead of relying on external auxiliary models. Concretely, EAPFusion maintains a compact set of intrinsic priors and progressively updates them across scales. These evolved priors are utilized to dynamically generate convolutional kernels, shifting the paradigm from fixed, pre-trained filters to instance-adaptive parameters via prior-conditioned dynamic convolution. Furthermore, we design a channel-level fusion module that shuffles and interleaves infrared and visible channels, applying local channel mixing to boost cross-modal complementarity. Experiments on different datasets, including cross-dataset evaluation and semantic segmentation, show that the proposed method achieves state-of-the-art quantitative and qualitative fusion results, and consistently boosts downstream performance. Code is coming soon.
Redefining Quality Criteria and Distance-Aware Score Modeling for Image Editing Assessment
Apr 14, 2026Recent advances in image editing have heightened the need for reliable Image Editing Quality Assessment (IEQA). Unlike traditional methods, IEQA requires complex reasoning over multimodal inputs and multi-dimensional assessments. Existing MLLM-based approaches often rely on human heuristic prompting, leading to two key limitations: rigid metric prompting and distance-agnostic score modeling. These issues hinder alignment with implicit human criteria and fail to capture the continuous structure of score spaces. To address this, we propose Define-and-Score Image Editing Quality Assessment (DS-IEQA), a unified framework that jointly learns evaluation criteria and score representations. Specifically, we introduce Feedback-Driven Metric Prompt Optimization (FDMPO) to automatically refine metric definitions via probabilistic feedback. Furthermore, we propose Token-Decoupled Distance Regression Loss (TDRL), which decouples numerical tokens from language modeling to explicitly model score continuity through expected distance minimization. Extensive experiments show our method's superior performance; it ranks 4th in the 2026 NTIRE X-AIGC Quality Assessment Track 2 without any additional training data.
NTIRE 2026 The 3rd Restore Any Image Model (RAIM) Challenge: Professional Image Quality Assessment (Track 1)
Apr 14, 2026In this paper, we present an overview of the NTIRE 2026 challenge on the 3rd Restore Any Image Model in the Wild, specifically focusing on Track 1: Professional Image Quality Assessment. Conventional Image Quality Assessment (IQA) typically relies on scalar scores. By compressing complex visual characteristics into a single number, these methods fundamentally struggle to distinguish subtle differences among uniformly high-quality images. Furthermore, they fail to articulate why one image is superior, lacking the reasoning capabilities required to provide guidance for vision tasks. To bridge this gap, recent advancements in Multimodal Large Language Models (MLLMs) offer a promising paradigm. Inspired by this potential, our challenge establishes a novel benchmark exploring the ability of MLLMs to mimic human expert cognition in evaluating high-quality image pairs. Participants were tasked with overcoming critical bottlenecks in professional scenarios, centering on two primary objectives: (1) Comparative Quality Selection: reliably identifying the visually superior image within a high-quality pair; and (2) Interpretative Reasoning: generating grounded, expert-level explanations that detail the rationale behind the selection. In total, the challenge attracted nearly 200 registrations and over 2,500 submissions. The top-performing methods significantly advanced the state of the art in professional IQA. The challenge dataset is available at https://github.com/narthchin/RAIM-PIQA, and the official homepage is accessible at https://www.codabench.org/competitions/12789/.
Towards Video Anomaly Detection from Event Streams: A Baseline and Benchmark Datasets
Mar 26, 2026Event-based vision, characterized by low redundancy, focus on dynamic motion, and inherent privacy-preserving properties, naturally fits the demands of video anomaly detection (VAD). However, the absence of dedicated event-stream anomaly detection datasets and effective modeling strategies has significantly hindered progress in this field. In this work, we take the first major step toward establishing event-based VAD as a unified research direction. We first construct multiple event-stream based benchmarks for video anomaly detection, featuring synchronized event and RGB recordings. Leveraging the unique properties of events, we then propose an EVent-centric spatiotemporal Video Anomaly Detection framework, namely EWAD, with three key innovations: an event density aware dynamic sampling strategy to select temporally informative segments; a density-modulated temporal modeling approach that captures contextual relations from sparse event streams; and an RGB-to-event knowledge distillation mechanism to enhance event-based representations under weak supervision. Extensive experiments on three benchmarks demonstrate that our EWAD achieves significant improvements over existing approaches, highlighting the potential and effectiveness of event-driven modeling for video anomaly detection. The benchmark datasets will be made publicly available.
PaAgent: Portrait-Aware Image Restoration Agent via Subjective-Objective Reinforcement Learning
Mar 17, 2026Image Restoration (IR) agents, leveraging multimodal large language models to perceive degradation and invoke restoration tools, have shown promise in automating IR tasks. However, existing IR agents typically lack an insight summarization mechanism for past interactions, which results in an exhaustive search for the optimal IR tool. To address this limitation, we propose a portrait-aware IR agent, dubbed PaAgent, which incorporates a self-evolving portrait bank for IR tools and Retrieval-Augmented Generation (RAG) to select a suitable IR tool for input. Specifically, to construct and evolve the portrait bank, the PaAgent continuously enriches it by summarizing the characteristics of various IR tools with restored images, selected IR tools, and degraded images. In addition, the RAG is employed to select the optimal IR tool for the input image by retrieving relevant insights from the portrait bank. Furthermore, to enhance PaAgent's ability to perceive degradation in complex scenes, we propose a subjective-objective reinforcement learning strategy that considers both image quality scores and semantic insights in reward generation, which accurately provides the degradation information even under partial and non-uniform degradation. Extensive experiments across 8 IR benchmarks, covering six single-degradation and eight mixed-degradation scenarios, validate PaAgent's superiority in addressing complex IR tasks. Our project page is \href{https://wyjgr.github.io/PaAgent.html}{PaAgent}.
DualTSR: Unified Dual-Diffusion Transformer for Scene Text Image Super-Resolution
Mar 15, 2026Scene Text Image Super-Resolution (STISR) aims to restore high-resolution details in low-resolution text images, which is crucial for both human readability and machine recognition. Existing methods, however, often depend on external Optical Character Recognition (OCR) models for textual priors or rely on complex multi-component architectures that are difficult to train and reproduce. In this paper, we introduce DualTSR, a unified end-to-end framework that addresses both issues. DualTSR employs a single multimodal transformer backbone trained with a dual diffusion objective. It simultaneously models the continuous distribution of high-resolution images via Conditional Flow Matching and the discrete distribution of textual content via discrete diffusion. This shared design enables visual and textual information to interact at every layer, allowing the model to infer text priors internally instead of relying on an external OCR module. Compared with prior multi-branch diffusion systems, DualTSR offers a simpler end-to-end formulation with fewer hand-crafted components. Experiments on synthetic Chinese benchmarks and a curated real-world evaluation protocol show that DualTSR achieves strong perceptual quality and text fidelity.
PIO-FVLM: Rethinking Training-Free Visual Token Reduction for VLM Acceleration from an Inference-Objective Perspective
Feb 05, 2026Recently, reducing redundant visual tokens in vision-language models (VLMs) to accelerate VLM inference has emerged as a hot topic. However, most existing methods rely on heuristics constructed based on inter-visual-token similarity or cross-modal visual-text similarity, which gives rise to certain limitations in compression performance and practical deployment. In contrast, we propose PIO-FVLM from the perspective of inference objectives, which transforms visual token compression into preserving output result invariance and selects tokens primarily by their importance to this goal. Specially, vision tokens are reordered with the guidance of token-level gradient saliency generated by our designed layer-local proxy loss, a coarse constraint from the current layer to the final result. Then the most valuable vision tokens are selected following the non-maximum suppression (NMS) principle. The proposed PIO-FVLM is training-free and compatible with FlashAttention, friendly to practical application and deployment. It can be deployed independently as an encoder-free method, or combined with encoder compression approaches like VisionZip for use as an encoder-involved method. On LLaVA-Next-7B, PIO-FVLM retains just 11.1% of visual tokens but maintains 97.2% of the original performance, with a 2.67$\times$ prefill speedup, 2.11$\times$ inference speedup, 6.22$\times$ lower FLOPs, and 6.05$\times$ reduced KV Cache overhead. Our code is available at https://github.com/ocy1/PIO-FVLM.
TPGDiff: Hierarchical Triple-Prior Guided Diffusion for Image Restoration
Jan 28, 2026All-in-one image restoration aims to address diverse degradation types using a single unified model. Existing methods typically rely on degradation priors to guide restoration, yet often struggle to reconstruct content in severely degraded regions. Although recent works leverage semantic information to facilitate content generation, integrating it into the shallow layers of diffusion models often disrupts spatial structures (\emph{e.g.}, blurring artifacts). To address this issue, we propose a Triple-Prior Guided Diffusion (TPGDiff) network for unified image restoration. TPGDiff incorporates degradation priors throughout the diffusion trajectory, while introducing structural priors into shallow layers and semantic priors into deep layers, enabling hierarchical and complementary prior guidance for image reconstruction. Specifically, we leverage multi-source structural cues as structural priors to capture fine-grained details and guide shallow layers representations. To complement this design, we further develop a distillation-driven semantic extractor that yields robust semantic priors, ensuring reliable high-level guidance at deep layers even under severe degradations. Furthermore, a degradation extractor is employed to learn degradation-aware priors, enabling stage-adaptive control of the diffusion process across all timesteps. Extensive experiments on both single- and multi-degradation benchmarks demonstrate that TPGDiff achieves superior performance and generalization across diverse restoration scenarios. Our project page is: https://leoyjtu.github.io/tpgdiff-project.
GMODiff: One-Step Gain Map Refinement with Diffusion Priors for HDR Reconstruction
Dec 18, 2025

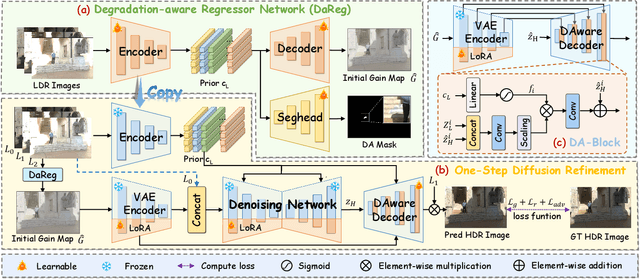

Pre-trained Latent Diffusion Models (LDMs) have recently shown strong perceptual priors for low-level vision tasks, making them a promising direction for multi-exposure High Dynamic Range (HDR) reconstruction. However, directly applying LDMs to HDR remains challenging due to: (1) limited dynamic-range representation caused by 8-bit latent compression, (2) high inference cost from multi-step denoising, and (3) content hallucination inherent to generative nature. To address these challenges, we introduce GMODiff, a gain map-driven one-step diffusion framework for multi-exposure HDR reconstruction. Instead of reconstructing full HDR content, we reformulate HDR reconstruction as a conditionally guided Gain Map (GM) estimation task, where the GM encodes the extended dynamic range while retaining the same bit depth as LDR images. We initialize the denoising process from an informative regression-based estimate rather than pure noise, enabling the model to generate high-quality GMs in a single denoising step. Furthermore, recognizing that regression-based models excel in content fidelity while LDMs favor perceptual quality, we leverage regression priors to guide both the denoising process and latent decoding of the LDM, suppressing hallucinations while preserving structural accuracy. Extensive experiments demonstrate that our GMODiff performs favorably against several state-of-the-art methods and is 100 faster than previous LDM-based methods.