 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^2$: Dual-Memory Augmentation for Long-Horizon Web Agents via Trajectory Summarization and Insight Retrieval
Feb 28, 2026Multimodal Large Language Models (MLLMs) based agents have demonstrated remarkable potential in autonomous web navigation. However, handling long-horizon tasks remains a critical bottleneck. Prevailing strategies often rely heavily on extensive data collection and model training, yet still struggle with high computational costs and insufficient reasoning capabilities when facing complex, long-horizon scenarios. To address this, we propose M$^2$, a training-free, memory-augmented framework designed to optimize context efficiency and decision-making robustness. Our approach incorporates a dual-tier memory mechanism that synergizes Dynamic Trajectory Summarization (Internal Memory) to compress verbose interaction history into concise state updates, and Insight Retrieval Augmentation (External Memory) to guide the agent with actionable guidelines retrieved from an offline insight bank. Extensive evaluations across WebVoyager and OnlineMind2Web demonstrate that M$^2$ consistently surpasses baselines, yielding up to a 19.6% success rate increase and 58.7% token reduction for Qwen3-VL-32B, while proprietary models like Claude achieve accuracy gains up to 12.5% alongside significantly lower computational overhead.
PIO-FVLM: Rethinking Training-Free Visual Token Reduction for VLM Acceleration from an Inference-Objective Perspective
Feb 05, 2026Recently, reducing redundant visual tokens in vision-language models (VLMs) to accelerate VLM inference has emerged as a hot topic. However, most existing methods rely on heuristics constructed based on inter-visual-token similarity or cross-modal visual-text similarity, which gives rise to certain limitations in compression performance and practical deployment. In contrast, we propose PIO-FVLM from the perspective of inference objectives, which transforms visual token compression into preserving output result invariance and selects tokens primarily by their importance to this goal. Specially, vision tokens are reordered with the guidance of token-level gradient saliency generated by our designed layer-local proxy loss, a coarse constraint from the current layer to the final result. Then the most valuable vision tokens are selected following the non-maximum suppression (NMS) principle. The proposed PIO-FVLM is training-free and compatible with FlashAttention, friendly to practical application and deployment. It can be deployed independently as an encoder-free method, or combined with encoder compression approaches like VisionZip for use as an encoder-involved method. On LLaVA-Next-7B, PIO-FVLM retains just 11.1% of visual tokens but maintains 97.2% of the original performance, with a 2.67$\times$ prefill speedup, 2.11$\times$ inference speedup, 6.22$\times$ lower FLOPs, and 6.05$\times$ reduced KV Cache overhead. Our code is available at https://github.com/ocy1/PIO-FVLM.
UVLM: Benchmarking Video Language Model for Underwater World Understanding
Jul 03, 2025Recently, the remarkable success of large language models (LLMs) has achieved a profound impact on the field of artificial intelligence. Numerous advanced works based on LLMs have been proposed and applied in various scenarios. Among them, video language models (VidLMs) are particularly widely used. However, existing works primarily focus on terrestrial scenarios, overlooking the highly demanding application needs of underwater observation. To overcome this gap, we introduce UVLM, an under water observation benchmark which is build through a collaborative approach combining human expertise and AI models. To ensure data quality, we have conducted in-depth considerations from multiple perspectives. First, to address the unique challenges of underwater environments, we selected videos that represent typical underwater challenges including light variations, water turbidity, and diverse viewing angles to construct the dataset. Second, to ensure data diversity, the dataset covers a wide range of frame rates, resolutions, 419 classes of marine animals, and various static plants and terrains. Next, for task diversity, we adopted a structured design where observation targets are categorized into two major classes: biological and environmental. Each category includes content observation and change/action observation, totaling 20 distinct task types. Finally, we designed several challenging evaluation metrics to enable quantitative comparison and analysis of different methods. Experiments on two representative VidLMs demonstrate that fine-tuning VidLMs on UVLM significantly improves underwater world understanding while also showing potential for slight improvements on existing in-air VidLM benchmarks, such as VideoMME and Perception text. The dataset and prompt engineering will be released publicly.
RINN: One Sample Radio Frequency Imaging based on Physics Informed Neural Network
Apr 19, 2025



Due to its ability to work in non-line-of-sight and low-light environments, radio frequency (RF) imaging technology is expected to bring new possibilities for embodied intelligence and multimodal sensing. However, widely used RF devices (such as Wi-Fi) often struggle to provide high-precision electromagnetic measurements and large-scale datasets, hindering the application of RF imaging technology. In this paper, we combine the ideas of PINN to design the RINN network, using physical constraints instead of true value comparison constraints and adapting it with the characteristics of ubiquitous RF signals, allowing the RINN network to achieve RF imaging using only one sample without phase and with amplitude noise. Our numerical evaluation results show that compared with 5 classic algorithms based on phase data for imaging results, RINN's imaging results based on phaseless data are good, with indicators such as RRMSE (0.11) performing similarly well. RINN provides new possibilities for the universal development of radio frequency imaging technology.
The Field-based Model: A New Perspective on RF-based Material Sensing
Dec 07, 2024



This paper introduces the design and implementation of WiField, a WiFi sensing system deployed on COTS devices that can simultaneously identify multiple wavelength-level targets placed flexibly. Unlike traditional RF sensing schemes that focus on specific targets and RF links, WiField focuses on all media in the sensing area for the entire electric field. In this perspective, WiField provides a unified framework to finely characterize the diffraction, scattering, and other effects of targets at different positions, materials, and numbers on signals. The combination of targets in different positions, numbers, and sizes is just a special case. WiField proposed a scheme that utilizes phaseless data to complete the inverse mapping from electric field to material distribution, thereby achieving the simultaneous identification of multiple wavelength-level targets at any position and having the potential for deployment on a wide range of low-cost COTS devices. Our evaluation results show that it has an average identification accuracy of over 97% for 1-3 targets (5 cm * 10 cm in size) with different materials randomly placed within a 1.05 m * 1.05 m area.
TG-LLaVA: Text Guided LLaVA via Learnable Latent Embeddings
Sep 15, 2024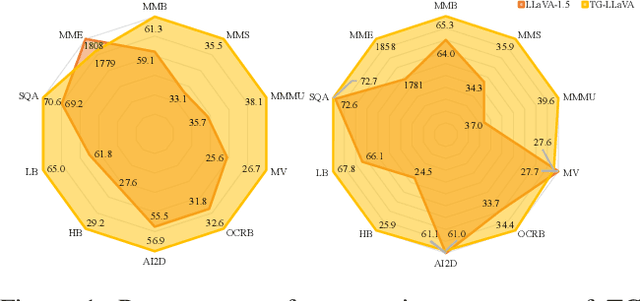
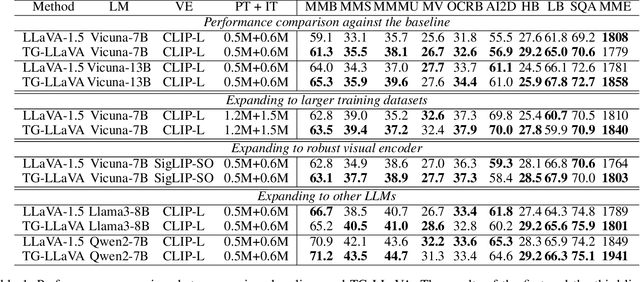
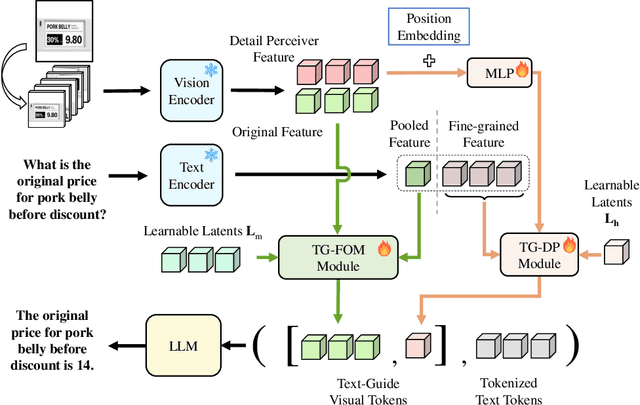

Currently, inspired by the success of vision-language models (VLMs), an increasing number of researchers are focusing on improving VLMs and have achieved promising results. However, most existing methods concentrate on optimizing the connector and enhancing the language model component, while neglecting improvements to the vision encoder itself. In contrast, we propose Text Guided LLaVA (TG-LLaVA) in this paper, which optimizes VLMs by guiding the vision encoder with text, offering a new and orthogonal optimization direction. Specifically, inspired by the purpose-driven logic inherent in human behavior, we use learnable latent embeddings as a bridge to analyze textual instruction and add the analysis results to the vision encoder as guidance, refining it. Subsequently, another set of latent embeddings extracts additional detailed text-guided information from high-resolution local patches as auxiliary information. Finally, with the guidance of text, the vision encoder can extract text-related features, similar to how humans focus on the most relevant parts of an image when considering a question. This results in generating better answers. Experiments on various datasets validate the effectiveness of the proposed method. Remarkably, without the need for additional training data, our propsoed method can bring more benefits to the baseline (LLaVA-1.5) compared with other concurrent methods. Furthermore, the proposed method consistently brings improvement in different settings.
Low-Rank Rescaled Vision Transformer Fine-Tuning: A Residual Design Approach
Mar 28, 2024



Parameter-efficient fine-tuning for pre-trained Vision Transformers aims to adeptly tailor a model to downstream tasks by learning a minimal set of new adaptation parameters while preserving the frozen majority of pre-trained parameters. Striking a balance between retaining the generalizable representation capacity of the pre-trained model and acquiring task-specific features poses a key challenge. Currently, there is a lack of focus on guiding this delicate trade-off. In this study, we approach the problem from the perspective of Singular Value Decomposition (SVD) of pre-trained parameter matrices, providing insights into the tuning dynamics of existing methods. Building upon this understanding, we propose a Residual-based Low-Rank Rescaling (RLRR) fine-tuning strategy. This strategy not only enhances flexibility in parameter tuning but also ensures that new parameters do not deviate excessively from the pre-trained model through a residual design. Extensive experiments demonstrate that our method achieves competitive performance across various downstream image classification tasks, all while maintaining comparable new parameters. We believe this work takes a step forward in offering a unified perspective for interpreting existing methods and serves as motivation for the development of new approaches that move closer to effectively considering the crucial trade-off mentioned above. Our code is available at \href{https://github.com/zstarN70/RLRR.git}{https://github.com/zstarN70/RLRR.git}.
Efficient Adaptation of Large Vision Transformer via Adapter Re-Composing
Oct 10, 2023The advent of high-capacity pre-trained models has revolutionized problem-solving in computer vision, shifting the focus from training task-specific models to adapting pre-trained models. Consequently, effectively adapting large pre-trained models to downstream tasks in an efficient manner has become a prominent research area. Existing solutions primarily concentrate on designing lightweight adapters and their interaction with pre-trained models, with the goal of minimizing the number of parameters requiring updates. In this study, we propose a novel Adapter Re-Composing (ARC) strategy that addresses efficient pre-trained model adaptation from a fresh perspective. Our approach considers the reusability of adaptation parameters and introduces a parameter-sharing scheme. Specifically, we leverage symmetric down-/up-projections to construct bottleneck operations, which are shared across layers. By learning low-dimensional re-scaling coefficients, we can effectively re-compose layer-adaptive adapters. This parameter-sharing strategy in adapter design allows us to significantly reduce the number of new parameters while maintaining satisfactory performance, thereby offering a promising approach to compress the adaptation cost. We conduct experiments on 24 downstream image classification tasks using various Vision Transformer variants to evaluate our method. The results demonstrate that our approach achieves compelling transfer learning performance with a reduced parameter count. Our code is available at \href{https://github.com/DavidYanAnDe/ARC}{https://github.com/DavidYanAnDe/ARC}.
Self-Supervised Node Representation Learning via Node-to-Neighbourhood Alignment
Feb 10, 2023Self-supervised node representation learning aims to learn node representations from unlabelled graphs that rival the supervised counterparts. The key towards learning informative node representations lies in how to effectively gain contextual information from the graph structure. In this work, we present simple-yet-effective self-supervised node representation learning via aligning the hidden representations of nodes and their neighbourhood. Our first idea achieves such node-to-neighbourhood alignment by directly maximizing the mutual information between their representations, which, we prove theoretically, plays the role of graph smoothing. Our framework is optimized via a surrogate contrastive loss and a Topology-Aware Positive Sampling (TAPS) strategy is proposed to sample positives by considering the structural dependencies between nodes, which enables offline positive selection. Considering the excessive memory overheads of contrastive learning, we further propose a negative-free solution, where the main contribution is a Graph Signal Decorrelation (GSD) constraint to avoid representation collapse and over-smoothing. The GSD constraint unifies some of the existing constraints and can be used to derive new implementations to combat representation collapse. By applying our methods on top of simple MLP-based node representation encoders, we learn node representations that achieve promising node classification performance on a set of graph-structured datasets from small- to large-scale.
Learning Pixel-Adaptive Weights for Portrait Photo Retouching
Dec 07, 2021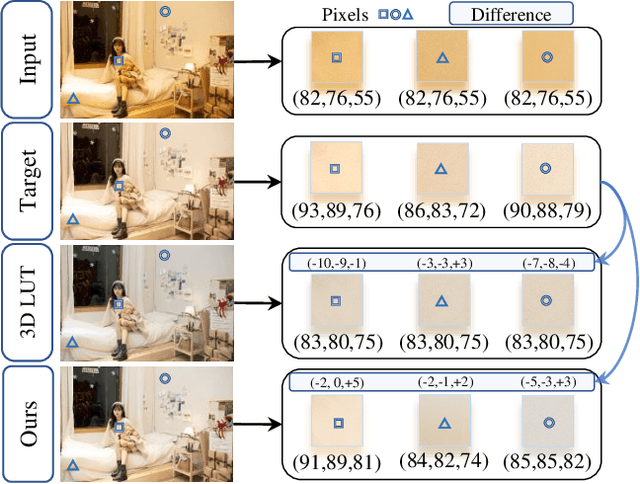
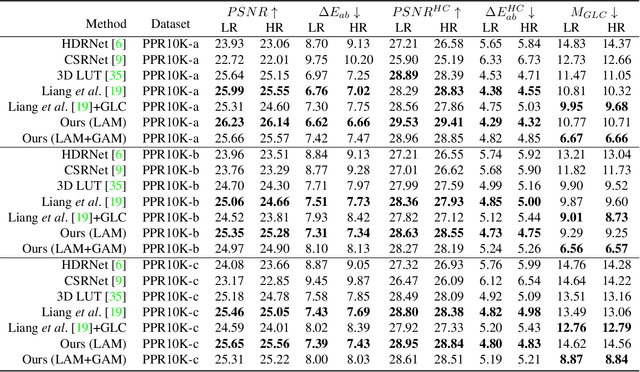
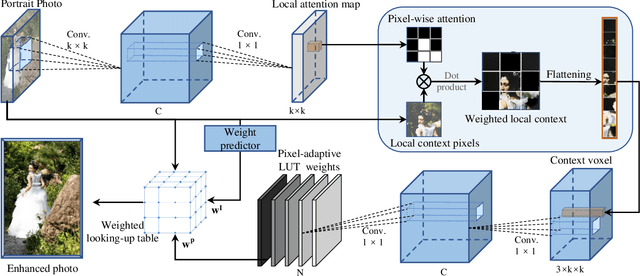

Portrait photo retouching is a photo retouching task that emphasizes human-region priority and group-level consistency. The lookup table-based method achieves promising retouching performance by learning image-adaptive weights to combine 3-dimensional lookup tables (3D LUTs) and conducting pixel-to-pixel color transformation. However, this paradigm ignores the local context cues and applies the same transformation to portrait pixels and background pixels when they exhibit the same raw RGB values. In contrast, an expert usually conducts different operations to adjust the color temperatures and tones of portrait regions and background regions. This inspires us to model local context cues to improve the retouching quality explicitly. Firstly, we consider an image patch and predict pixel-adaptive lookup table weights to precisely retouch the center pixel. Secondly, as neighboring pixels exhibit different affinities to the center pixel, we estimate a local attention mask to modulate the influence of neighboring pixels. Thirdly, the quality of the local attention mask can be further improved by applying supervision, which is based on the affinity map calculated by the groundtruth portrait mask. As for group-level consistency, we propose to directly constrain the variance of mean color components in the Lab space. Extensive experiments on PPR10K dataset verify the effectiveness of our method, e.g. on high-resolution photos, the PSNR metric receives over 0.5 gains while the group-level consistency metric obtains at least 2.1 decreases.