 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinePhys: Fine-grained Human Action Generation by Explicitly Incorporating Physical Laws for Effective Skeletal Guidance
May 19, 2025Despite significant advances in video generation, synthesizing physically plausible human actions remains a persistent challenge, particularly in modeling fine-grained semantics and complex temporal dynamics. For instance, generating gymnastics routines such as "switch leap with 0.5 turn" poses substantial difficulties for current methods, often yielding unsatisfactory results. To bridge this gap, we propose FinePhys, a Fine-grained human action generation framework that incorporates Physics to obtain effective skeletal guidance. Specifically, FinePhys first estimates 2D poses in an online manner and then performs 2D-to-3D dimension lifting via in-context learning. To mitigate the instability and limited interpretability of purely data-driven 3D poses, we further introduce a physics-based motion re-estimation module governed by Euler-Lagrange equations, calculating joint accelerations via bidirectional temporal updating. The physically predicted 3D poses are then fused with data-driven ones, offering multi-scale 2D heatmap guidance for the diffusion process. Evaluated on three fine-grained action subsets from FineGym (FX-JUMP, FX-TURN, and FX-SALTO), FinePhys significantly outperforms competitive baselines. Comprehensive qualitative results further demonstrate FinePhys's ability to generate more natural and plausible fine-grained human actions.
Multimodal Large Models Are Effective Action Anticipators
Jan 01, 2025



The task of long-term action anticipation demands solutions that can effectively model temporal dynamics over extended periods while deeply understanding the inherent semantics of actions. Traditional approaches, which primarily rely on recurrent units or Transformer layers to capture long-term dependencies, often fall short in addressing these challenges. Large Language Models (LLMs), with their robust sequential modeling capabilities and extensive commonsense knowledge, present new opportunities for long-term action anticipation. In this work, we introduce the ActionLLM framework, a novel approach that treats video sequences as successive tokens, leveraging LLMs to anticipate future actions. Our baseline model simplifies the LLM architecture by setting future tokens, incorporating an action tuning module, and reducing the textual decoder layer to a linear layer, enabling straightforward action prediction without the need for complex instructions or redundant descriptions. To further harness the commonsense reasoning of LLMs, we predict action categories for observed frames and use sequential textual clues to guide semantic understanding. In addition, we introduce a Cross-Modality Interaction Block, designed to explore the specificity within each modality and capture interactions between vision and textual modalities, thereby enhancing multimodal tuning. Extensive experiments on benchmark datasets demonstrate the superiority of the proposed ActionLLM framework, encouraging a promising direction to explore LLMs in the context of action anticipation. Code is available at https://github.com/2tianyao1/ActionLLM.git.
Boosting Gaze Object Prediction via Pixel-level Supervision from Vision Foundation Model
Aug 02, 2024Gaze object prediction (GOP) aims to predict the category and location of the object that a human is looking at. Previous methods utilized box-level supervision to identify the object that a person is looking at, but struggled with semantic ambiguity, ie, a single box may contain several items since objects are close together. The Vision foundation model (VFM) has improved in object segmentation using box prompts, which can reduce confusion by more precisely locating objects, offering advantages for fine-grained prediction of gaze objects. This paper presents a more challenging gaze object segmentation (GOS) task, which involves inferring the pixel-level mask corresponding to the object captured by human gaze behavior. In particular, we propose that the pixel-level supervision provided by VFM can be integrated into gaze object prediction to mitigate semantic ambiguity. This leads to our gaze object detection and segmentation framework that enables accurate pixel-level predictions. Different from previous methods that require additional head input or ignore head features, we propose to automatically obtain head features from scene features to ensure the model's inference efficiency and flexibility in the real world. Moreover, rather than directly fuse features to predict gaze heatmap as in existing methods, which may overlook spatial location and subtle details of the object, we develop a space-to-object gaze regression method to facilitate human-object gaze interaction. Specifically, it first constructs an initial human-object spatial connection, then refines this connection by interacting with semantically clear features in the segmentation branch, ultimately predicting a gaze heatmap for precise localization. Extensive experiments on GOO-Synth and GOO-Real datasets demonstrate the effectiveness of our method.
Vision-based Wearable Steering Assistance for People with Impaired Vision in Jogging
Aug 01, 2024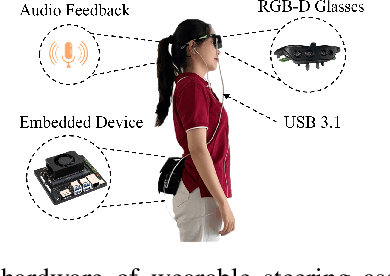



Outdoor sports pose a challenge for people with impaired vision. The demand for higher-speed mobility inspired us to develop a vision-based wearable steering assistance. To ensure broad applicability, we focused on a representative sports environment, the athletics track. Our efforts centered on improving the speed and accuracy of perception, enhancing planning adaptability for the real world, and providing swift and safe assistance for people with impaired vision. In perception, we engineered a lightweight multitask network capable of simultaneously detecting track lines and obstacles. Additionally, due to the limitations of existing datasets for supporting multi-task detection in athletics tracks, we diligently collected and annotated a new dataset (MAT) containing 1000 images. In planning, we integrated the methods of sampling and spline curves, addressing the planning challenges of curves. Meanwhile, we utilized the positions of the track lines and obstacles as constraints to guide people with impaired vision safely along the current track. Our system is deployed on an embedded device, Jetson Orin NX. Through outdoor experiments, it demonstrated adaptability in different sports scenarios, assisting users in achieving free movement of 400-meter at an average speed of 1.34 m/s, meeting the level of normal people in jogging. Our MAT dataset is publicly available from https://github.com/snoopy-l/MAT
Explainable Bayesian Recurrent Neural Smoother to Capture Global State Evolutionary Correlations
Jun 17, 2024Through integrating the evolutionary correlations across global states in the bidirectional recursion, an explainable Bayesian recurrent neural smoother (EBRNS) is proposed for offline data-assisted fixed-interval state smoothing. At first, the proposed model, containing global states in the evolutionary interval, is transformed into an equivalent model with bidirectional memory. This transformation incorporates crucial global state information with support for bi-directional recursive computation. For the transformed model, the joint state-memory-trend Bayesian filtering and smoothing frameworks are derived by introducing the bidirectional memory iteration mechanism and offline data into Bayesian estimation theory. The derived frameworks are implemented using the Gaussian approximation to ensure analytical properties and computational efficiency. Finally, the neural network modules within EBRNS and its two-stage training scheme are designed. Unlike most existing approaches that artificially combine deep learning and model-based estimation, the bidirectional recursion and internal gated structures of EBRNS are naturally derived from Bayesian estimation theory, explainably integrating prior model knowledge, online measurement, and offline data. Experiments on representative real-world datasets demonstrate that the high smoothing accuracy of EBRNS is accompanied by data efficiency and a lightweight parameter scale.
TransGOP: Transformer-Based Gaze Object Prediction
Feb 21, 2024

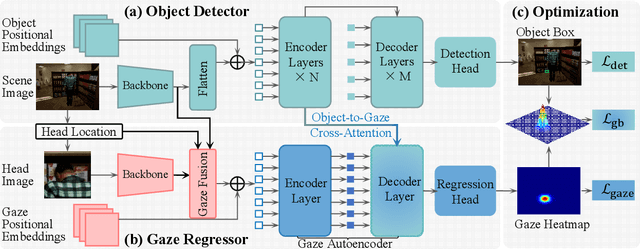
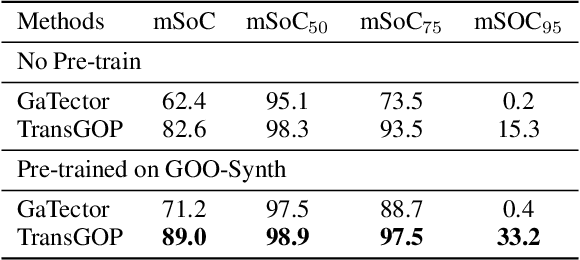
Gaze object prediction aims to predict the location and category of the object that is watched by a human. Previous gaze object prediction works use CNN-based object detectors to predict the object's location. However, we find that Transformer-based object detectors can predict more accurate object location for dense objects in retail scenarios. Moreover, the long-distance modeling capability of the Transformer can help to build relationships between the human head and the gaze object, which is important for the GOP task. To this end, this paper introduces Transformer into the fields of gaze object prediction and proposes an end-to-end Transformer-based gaze object prediction method named TransGOP. Specifically, TransGOP uses an off-the-shelf Transformer-based object detector to detect the location of objects and designs a Transformer-based gaze autoencoder in the gaze regressor to establish long-distance gaze relationships. Moreover, to improve gaze heatmap regression, we propose an object-to-gaze cross-attention mechanism to let the queries of the gaze autoencoder learn the global-memory position knowledge from the object detector. Finally, to make the whole framework end-to-end trained, we propose a Gaze Box loss to jointly optimize the object detector and gaze regressor by enhancing the gaze heatmap energy in the box of the gaze object. Extensive experiments on the GOO-Synth and GOO-Real datasets demonstrate that our TransGOP achieves state-of-the-art performance on all tracks, i.e., object detection, gaze estimation, and gaze object prediction. Our code will be available at https://github.com/chenxi-Guo/TransGOP.git.
PneumoLLM: Harnessing the Power of Large Language Model for Pneumoconiosis Diagnosis
Dec 08, 2023The conventional pretraining-and-finetuning paradigm, while effective for common diseases with ample data, faces challenges in diagnosing data-scarce occupational diseases like pneumoconiosis. Recently, large language models (LLMs) have exhibits unprecedented ability when conducting multiple tasks in dialogue, bringing opportunities to diagnosis. A common strategy might involve using adapter layers for vision-language alignment and diagnosis in a dialogic manner. Yet, this approach often requires optimization of extensive learnable parameters in the text branch and the dialogue head, potentially diminishing the LLMs' efficacy, especially with limited training data. In our work, we innovate by eliminating the text branch and substituting the dialogue head with a classification head. This approach presents a more effective method for harnessing LLMs in diagnosis with fewer learnable parameters. Furthermore, to balance the retention of detailed image information with progression towards accurate diagnosis, we introduce the contextual multi-token engine. This engine is specialized in adaptively generating diagnostic tokens. Additionally, we propose the information emitter module, which unidirectionally emits information from image tokens to diagnosis tokens. Comprehensive experiments validate the superiority of our methods and the effectiveness of proposed modules. Our codes can be found at https://github.com/CodeMonsterPHD/PneumoLLM/tree/main.
Multi-level Gated Bayesian Recurrent Neural Network for State Estimation
Oct 26, 2023The optimality of Bayesian filtering relies on the completeness of prior models, while deep learning holds a distinct advantage in learning models from offline data. Nevertheless, the current fusion of these two methodologies remains largely ad hoc, lacking a theoretical foundation. This paper presents a novel solution, namely a multi-level gated Bayesian recurrent neural network specifically designed to state estimation under model mismatches. Firstly, we transform the non-Markov state-space model into an equivalent first-order Markov model with memory. It is a generalized transformation that overcomes the limitations of the first-order Markov property and enables recursive filtering. Secondly, by deriving a data-assisted joint state-memory-mismatch Bayesian filtering, we design a Bayesian multi-level gated framework that includes a memory update gate for capturing the temporal regularities in state evolution, a state prediction gate with the evolution mismatch compensation, and a state update gate with the observation mismatch compensation. The Gaussian approximation implementation of the filtering process within the gated framework is derived, taking into account the computational efficiency. Finally, the corresponding internal neural network structures and end-to-end training methods are designed. The Bayesian filtering theory enhances the interpretability of the proposed gated network, enabling the effective integration of offline data and prior models within functionally explicit gated units. In comprehensive experiments, including simulations and real-world datasets, the proposed gated network demonstrates superior estimation performance compared to benchmark filters and state-of-the-art deep learning filtering methods.
Multi-granularity Backprojection Transformer for Remote Sensing Image Super-Resolution
Oct 19, 2023Backprojection networks have achieved promising super-resolution performance for nature images but not well be explored in the remote sensing image super-resolution (RSISR) field due to the high computation costs. In this paper, we propose a Multi-granularity Backprojection Transformer termed MBT for RSISR. MBT incorporates the backprojection learning strategy into a Transformer framework. It consists of Scale-aware Backprojection-based Transformer Layers (SPTLs) for scale-aware low-resolution feature learning and Context-aware Backprojection-based Transformer Blocks (CPTBs) for hierarchical feature learning. A backprojection-based reconstruction module (PRM) is also introduced to enhance the hierarchical features for image reconstruction. MBT stands out by efficiently learning low-resolution features without excessive modules for high-resolution processing, resulting in lower computational resources. Experiment results on UCMerced and AID datasets demonstrate that MBT obtains state-of-the-art results compared to other leading methods.
Can large language models provide useful feedback on research papers? A large-scale empirical analysis
Oct 03, 2023



Expert feedback lays the foundation of rigorous research. However, the rapid growth of scholarly production and intricate knowledge specialization challenge the conventional scientific feedback mechanisms. High-quality peer reviews are increasingly difficult to obtain. Researchers who are more junior or from under-resourced settings have especially hard times getting timely feedback. With the breakthrough of large language models (LLM) such as GPT-4, there is growing interest in using LLMs to generate scientific feedback on research manuscripts. However, the utility of LLM-generated feedback has not been systematically studied. To address this gap, we created an automated pipeline using GPT-4 to provide comments on the full PDFs of scientific papers. We evaluated the quality of GPT-4's feedback through two large-scale studies. We first quantitatively compared GPT-4's generated feedback with human peer reviewer feedback in 15 Nature family journals (3,096 papers in total) and the ICLR machine learning conference (1,709 papers). The overlap in the points raised by GPT-4 and by human reviewers (average overlap 30.85% for Nature journals, 39.23% for ICLR) is comparable to the overlap between two human reviewers (average overlap 28.58% for Nature journals, 35.25% for ICLR). The overlap between GPT-4 and human reviewers is larger for the weaker papers. We then conducted a prospective user study with 308 researchers from 110 US institutions in the field of AI and computational biology to understand how researchers perceive feedback generated by our GPT-4 system on their own papers. Overall, more than half (57.4%) of the users found GPT-4 generated feedback helpful/very helpful and 82.4% found it more beneficial than feedback from at least some human reviewers. While our findings show that LLM-generated feedback can help researchers, we also identify several limitations.