 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Replication to Redesign: Exploring Pairwise Comparisons for LLM-Based Peer Review
Jun 12, 2025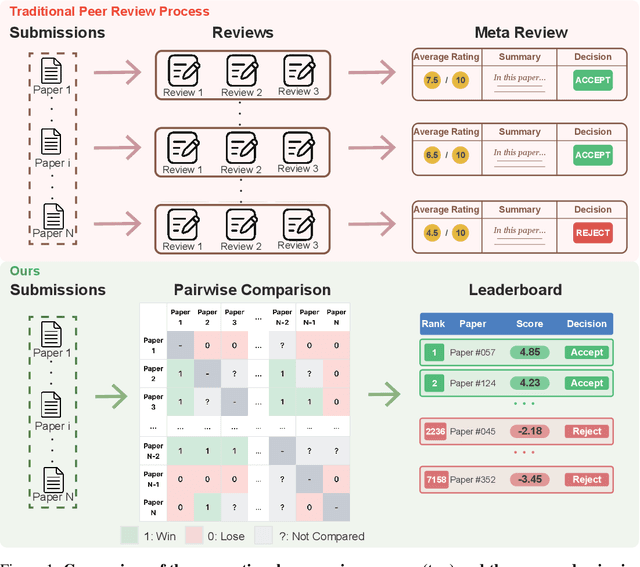
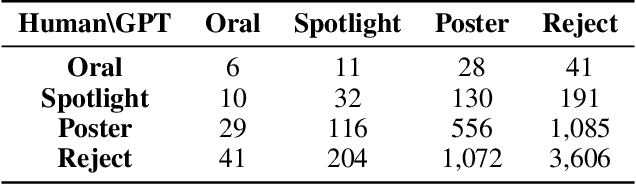
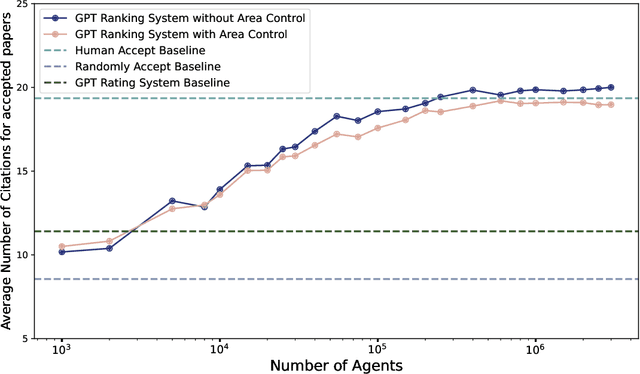
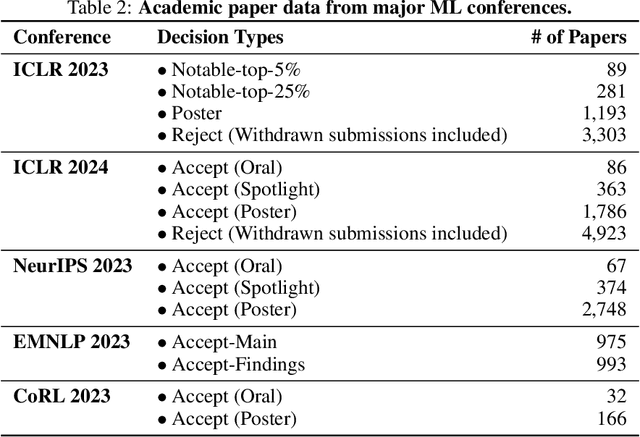
The advent of large language models (LLMs) offers unprecedented opportunities to reimagine peer review beyond the constraints of traditional workflows. Despite these opportunities, prior efforts have largely focused on replicating traditional review workflows with LLMs serving as direct substitutes for human reviewers, while limited attention has been given to exploring new paradigms that fundamentally rethink how LLMs can participate in the academic review process. In this paper, we introduce and explore a novel mechanism that employs LLM agents to perform pairwise comparisons among manuscripts instead of individual scoring. By aggregating outcomes from substantial pairwise evaluations, this approach enables a more accurate and robust measure of relative manuscript quality. Our experiments demonstrate that this comparative approach significantly outperforms traditional rating-based methods in identifying high-impact papers. However, our analysis also reveals emergent biases in the selection process, notably a reduced novelty in research topics and an increased institutional imbalance. These findings highlight both the transformative potential of rethinking peer review with LLMs and critical challenges that future systems must address to ensure equity and diversity.
Weak-for-Strong: Training Weak Meta-Agent to Harness Strong Executors
Apr 07, 2025Efficiently leveraging of the capabilities of contemporary large language models (LLMs) is increasingly challenging, particularly when direct fine-tuning is expensive and often impractical. Existing training-free methods, including manually or automated designed workflows, typically demand substantial human effort or yield suboptimal results. This paper proposes Weak-for-Strong Harnessing (W4S), a novel framework that customizes smaller, cost-efficient language models to design and optimize workflows for harnessing stronger models. W4S formulates workflow design as a multi-turn markov decision process and introduces reinforcement learning for agentic workflow optimization (RLAO) to train a weak meta-agent. Through iterative interaction with the environment, the meta-agent learns to design increasingly effective workflows without manual intervention. Empirical results demonstrate the superiority of W4S that our 7B meta-agent, trained with just one GPU hour, outperforms the strongest baseline by 2.9% ~ 24.6% across eleven benchmarks, successfully elevating the performance of state-of-the-art models such as GPT-3.5-Turbo and GPT-4o. Notably, W4S exhibits strong generalization capabilities across both seen and unseen tasks, offering an efficient, high-performing alternative to directly fine-tuning strong models.
Adaptive Self-improvement LLM Agentic System for ML Library Development
Feb 04, 2025ML libraries, often written in architecture-specific programming languages (ASPLs) that target domain-specific architectures, are key to efficient ML systems. However, writing these high-performance ML libraries is challenging because it requires expert knowledge of ML algorithms and the ASPL. Large language models (LLMs), on the other hand, have shown general coding capabilities. However, challenges remain when using LLMs for generating ML libraries using ASPLs because 1) this task is complicated even for experienced human programmers and 2) there are limited code examples because of the esoteric and evolving nature of ASPLs. Therefore, LLMs need complex reasoning with limited data in order to complete this task. To address these challenges, we introduce an adaptive self-improvement agentic system. In order to evaluate the effectiveness of our system, we construct a benchmark of a typical ML library and generate ASPL code with both open and closed-source LLMs on this benchmark. Our results show improvements of up to $3.9\times$ over a baseline single LLM.
Mixture-of-Mamba: Enhancing Multi-Modal State-Space Models with Modality-Aware Sparsity
Jan 27, 2025



State Space Models (SSMs) have emerged as efficient alternatives to Transformers for sequential modeling, but their inability to leverage modality-specific features limits their performance in multi-modal pretraining. Here, we propose Mixture-of-Mamba, a novel SSM architecture that introduces modality-aware sparsity through modality-specific parameterization of the Mamba block. Building on Mixture-of-Transformers (W. Liang et al. arXiv:2411.04996; 2024), we extend the benefits of modality-aware sparsity to SSMs while preserving their computational efficiency. We evaluate Mixture-of-Mamba across three multi-modal pretraining settings: Transfusion (interleaved text and continuous image tokens with diffusion loss), Chameleon (interleaved text and discrete image tokens), and an extended three-modality framework incorporating speech. Mixture-of-Mamba consistently reaches the same loss values at earlier training steps with significantly reduced computational costs. In the Transfusion setting, Mixture-of-Mamba achieves equivalent image loss using only 34.76% of the training FLOPs at the 1.4B scale. In the Chameleon setting, Mixture-of-Mamba reaches similar image loss with just 42.50% of the FLOPs at the 1.4B scale, and similar text loss with just 65.40% of the FLOPs. In the three-modality setting, MoM matches speech loss at 24.80% of the FLOPs at the 1.4B scale. Our ablation study highlights the synergistic effects of decoupling projection components, where joint decoupling yields greater gains than individual modifications. These results establish modality-aware sparsity as a versatile and effective design principle, extending its impact from Transformers to SSMs and setting new benchmarks in multi-modal pretraining. Our code can be accessed at https://github.com/Weixin-Liang/Mixture-of-Mamba
LMFusion: Adapting Pretrained Language Models for Multimodal Generation
Dec 26, 2024



We present LMFusion, a framework for empowering pretrained text-only large language models (LLMs) with multimodal generative capabilities, enabling them to understand and generate both text and images in arbitrary sequences. LMFusion leverages existing Llama-3's weights for processing texts autoregressively while introducing additional and parallel transformer modules for processing images with diffusion. During training, the data from each modality is routed to its dedicated modules: modality-specific feedforward layers, query-key-value projections, and normalization layers process each modality independently, while the shared self-attention layers allow interactions across text and image features. By freezing the text-specific modules and only training the image-specific modules, LMFusion preserves the language capabilities of text-only LLMs while developing strong visual understanding and generation abilities. Compared to methods that pretrain multimodal generative models from scratch, our experiments demonstrate that, LMFusion improves image understanding by 20% and image generation by 3.6% using only 50% of the FLOPs while maintaining Llama-3's language capabilities. We also demonstrate that this framework can adapt existing vision-language models with multimodal generation ability. Overall, this framework not only leverages existing computational investments in text-only LLMs but also enables the parallel development of language and vision capabilities, presenting a promising direction for efficient multimodal model development.
LlamaFusion: Adapting Pretrained Language Models for Multimodal Generation
Dec 19, 2024We present LlamaFusion, a framework for empowering pretrained text-only large language models (LLMs) with multimodal generative capabilities, enabling them to understand and generate both text and images in arbitrary sequences. LlamaFusion leverages existing Llama-3's weights for processing texts autoregressively while introducing additional and parallel transformer modules for processing images with diffusion. During training, the data from each modality is routed to its dedicated modules: modality-specific feedforward layers, query-key-value projections, and normalization layers process each modality independently, while the shared self-attention layers allow interactions across text and image features. By freezing the text-specific modules and only training the image-specific modules, LlamaFusion preserves the language capabilities of text-only LLMs while developing strong visual understanding and generation abilities. Compared to methods that pretrain multimodal generative models from scratch, our experiments demonstrate that, LlamaFusion improves image understanding by 20% and image generation by 3.6% using only 50% of the FLOPs while maintaining Llama-3's language capabilities. We also demonstrate that this framework can adapt existing vision-language models with multimodal generation ability. Overall, this framework not only leverages existing computational investments in text-only LLMs but also enables the parallel development of language and vision capabilities, presenting a promising direction for efficient multimodal model development.
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
Nov 07, 2024

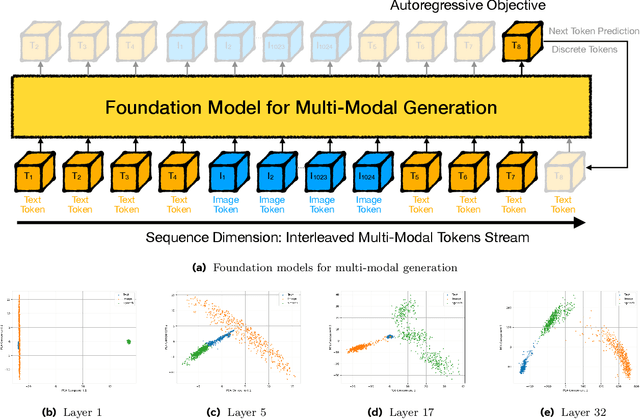

The development of large language models (LLMs) has expanded to multi-modal systems capable of processing text, images, and speech within a unified framework. Training these models demands significantly larger datasets and computational resources compared to text-only LLMs. To address the scaling challenges, we introduce Mixture-of-Transformers (MoT), a sparse multi-modal transformer architecture that significantly reduces pretraining computational costs. MoT decouples non-embedding parameters of the model by modality -- including feed-forward networks, attention matrices, and layer normalization -- enabling modality-specific processing with global self-attention over the full input sequence. We evaluate MoT across multiple settings and model scales. In the Chameleon 7B setting (autoregressive text-and-image generation), MoT matches the dense baseline's performance using only 55.8\% of the FLOPs. When extended to include speech, MoT reaches speech performance comparable to the dense baseline with only 37.2\% of the FLOPs. In the Transfusion setting, where text and image are trained with different objectives, a 7B MoT model matches the image modality performance of the dense baseline with one third of the FLOPs, and a 760M MoT model outperforms a 1.4B dense baseline across key image generation metrics. System profiling further highlights MoT's practical benefits, achieving dense baseline image quality in 47.2\% of the wall-clock time and text quality in 75.6\% of the wall-clock time (measured on AWS p4de.24xlarge instances with NVIDIA A100 GPUs).
Mapping the Increasing Use of LLMs in Scientific Papers
Apr 01, 2024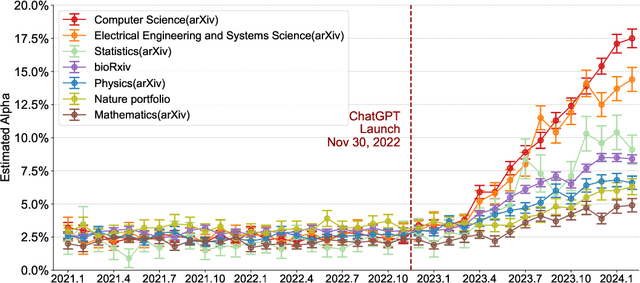
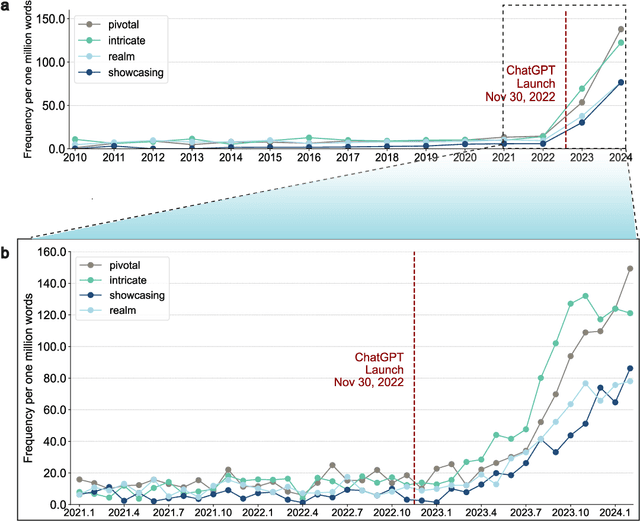
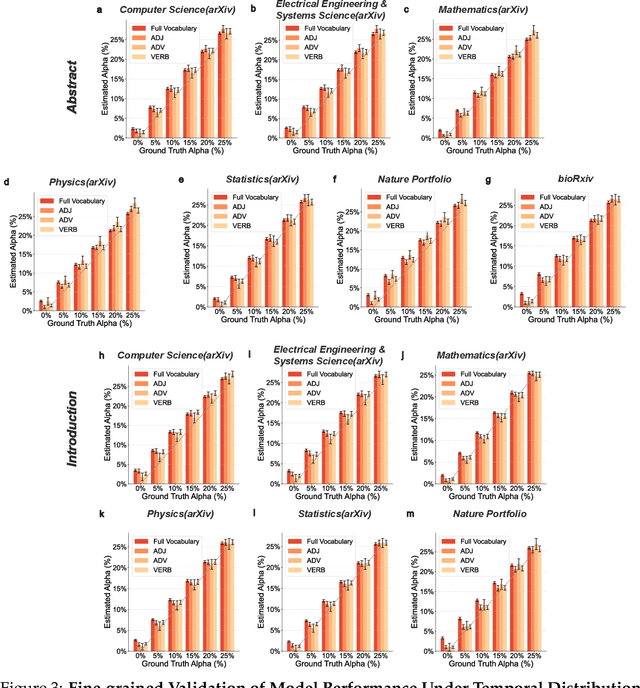
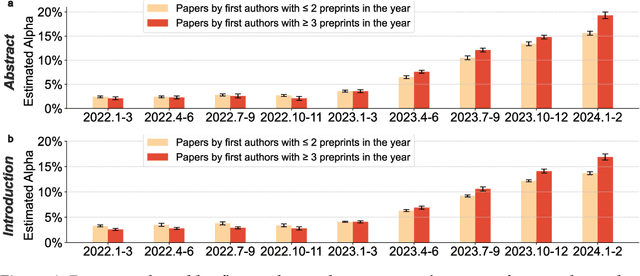
Scientific publishing lays the foundation of science by disseminating research findings, fostering collaboration, encouraging reproducibility, and ensuring that scientific knowledge is accessible, verifiable, and built upon over time. Recently, there has been immense speculation about how many people are using large language models (LLMs) like ChatGPT in their academic writing, and to what extent this tool might have an effect on global scientific practices. However, we lack a precise measure of the proportion of academic writing substantially modified or produced by LLMs. To address this gap, we conduct the first systematic, large-scale analysis across 950,965 papers published between January 2020 and February 2024 on the arXiv, bioRxiv, and Nature portfolio journals, using a population-level statistical framework to measure the prevalence of LLM-modified content over time. Our statistical estimation operates on the corpus level and is more robust than inference on individual instances. Our findings reveal a steady increase in LLM usage, with the largest and fastest growth observed in Computer Science papers (up to 17.5%). In comparison, Mathematics papers and the Nature portfolio showed the least LLM modification (up to 6.3%). Moreover, at an aggregate level, our analysis reveals that higher levels of LLM-modification are associated with papers whose first authors post preprints more frequently, papers in more crowded research areas, and papers of shorter lengths. Our findings suggests that LLMs are being broadly used in scientific writings.
Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews
Mar 11, 2024



We present an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM). Our maximum likelihood model leverages expert-written and AI-generated reference texts to accurately and efficiently examine real-world LLM-use at the corpus level. We apply this approach to a case study of scientific peer review in AI conferences that took place after the release of ChatGPT: ICLR 2024, NeurIPS 2023, CoRL 2023 and EMNLP 2023. Our results suggest that between 6.5% and 16.9% of text submitted as peer reviews to these conferences could have been substantially modified by LLMs, i.e. beyond spell-checking or minor writing updates. The circumstances in which generated text occurs offer insight into user behavior: the estimated fraction of LLM-generated text is higher in reviews which report lower confidence, were submitted close to the deadline, and from reviewers who are less likely to respond to author rebuttals. We also observe corpus-level trends in generated text which may be too subtle to detect at the individual level, and discuss the implications of such trends on peer review. We call for future interdisciplinary work to examine how LLM use is changing our information and knowledge practices.
What's documented in AI? Systematic Analysis of 32K AI Model Cards
Feb 07, 2024The rapid proliferation of AI models has underscored the importance of thorough documentation, as it enables users to understand, trust, and effectively utilize these models in various applications. Although developers are encouraged to produce model cards, it's not clear how much information or what information these cards contain. In this study, we conduct a comprehensive analysis of 32,111 AI model documentations on Hugging Face, a leading platform for distributing and deploying AI models. Our investigation sheds light on the prevailing model card documentation practices. Most of the AI models with substantial downloads provide model cards, though the cards have uneven informativeness. We find that sections addressing environmental impact, limitations, and evaluation exhibit the lowest filled-out rates, while the training section is the most consistently filled-out. We analyze the content of each section to characterize practitioners' priorities. Interestingly, there are substantial discussions of data, sometimes with equal or even greater emphasis than the model itself. To evaluate the impact of model cards, we conducted an intervention study by adding detailed model cards to 42 popular models which had no or sparse model cards previously. We find that adding model cards is moderately correlated with an increase weekly download rates. Our study opens up a new perspective for analyzing community norms and practices for model documentation through large-scale data science and linguistics analysis.