 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubgroup Discovery with the Cox Model
Dec 23, 2025



We study the problem of subgroup discovery for survival analysis, where the goal is to find an interpretable subset of the data on which a Cox model is highly accurate. Our work is the first to study this particular subgroup problem, for which we make several contributions. Subgroup discovery methods generally require a "quality function" in order to sift through and select the most advantageous subgroups. We first examine why existing natural choices for quality functions are insufficient to solve the subgroup discovery problem for the Cox model. To address the shortcomings of existing metrics, we introduce two technical innovations: the *expected prediction entropy (EPE)*, a novel metric for evaluating survival models which predict a hazard function; and the *conditional rank statistics (CRS)*, a statistical object which quantifies the deviation of an individual point to the distribution of survival times in an existing subgroup. We study the EPE and CRS theoretically and show that they can solve many of the problems with existing metrics. We introduce a total of eight algorithms for the Cox subgroup discovery problem. The main algorithm is able to take advantage of both the EPE and the CRS, allowing us to give theoretical correctness results for this algorithm in a well-specified setting. We evaluate all of the proposed methods empirically on both synthetic and real data. The experiments confirm our theory, showing that our contributions allow for the recovery of a ground-truth subgroup in well-specified cases, as well as leading to better model fit compared to naively fitting the Cox model to the whole dataset in practical settings. Lastly, we conduct a case study on jet engine simulation data from NASA. The discovered subgroups uncover known nonlinearities/homogeneity in the data, and which suggest design choices which have been mirrored in practice.
Quantitative Bounds for Length Generalization in Transformers
Oct 30, 2025We study the problem of length generalization (LG) in transformers: the ability of a model trained on shorter sequences to maintain performance when evaluated on much longer, previously unseen inputs. Prior work by Huang et al. (2025) established that transformers eventually achieve length generalization once the training sequence length exceeds some finite threshold, but left open the question of how large it must be. In this work, we provide the first quantitative bounds on the required training length for length generalization to occur. Motivated by previous empirical and theoretical work, we analyze LG in several distinct problem settings: $\ell_\infty$ error control vs. average error control over an input distribution, infinite-precision softmax attention vs. finite-precision attention (which reduces to an argmax) in the transformer, and one- vs. two-layer transformers. In all scenarios, we prove that LG occurs when the internal behavior of the transformer on longer sequences can be "simulated" by its behavior on shorter sequences seen during training. Our bounds give qualitative estimates for the length of training data required for a transformer to generalize, and we verify these insights empirically. These results sharpen our theoretical understanding of the mechanisms underlying extrapolation in transformers, and formalize the intuition that richer training data is required for generalization on more complex tasks.
Solving Inverse Problems via Diffusion-Based Priors: An Approximation-Free Ensemble Sampling Approach
Jun 05, 2025Diffusion models (DMs) have proven to be effective in modeling high-dimensional distributions, leading to their widespread adoption for representing complex priors in Bayesian inverse problems (BIPs). However, current DM-based posterior sampling methods proposed for solving common BIPs rely on heuristic approximations to the generative process. To exploit the generative capability of DMs and avoid the usage of such approximations, we propose an ensemble-based algorithm that performs posterior sampling without the use of heuristic approximations. Our algorithm is motivated by existing works that combine DM-based methods with the sequential Monte Carlo (SMC) method. By examining how the prior evolves through the diffusion process encoded by the pre-trained score function, we derive a modified partial differential equation (PDE) governing the evolution of the corresponding posterior distribution. This PDE includes a modified diffusion term and a reweighting term, which can be simulated via stochastic weighted particle methods. Theoretically, we prove that the error between the true posterior distribution can be bounded in terms of the training error of the pre-trained score function and the number of particles in the ensemble. Empirically, we validate our algorithm on several inverse problems in imaging to show that our method gives more accurate reconstructions compared to existing DM-based methods.
Domain-Guided Weight Modulation for Semi-Supervised Domain Generalization
Sep 04, 2024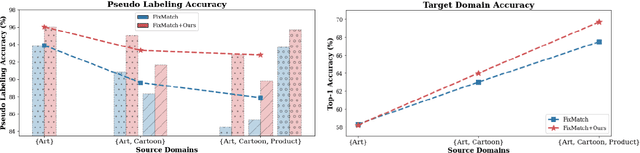
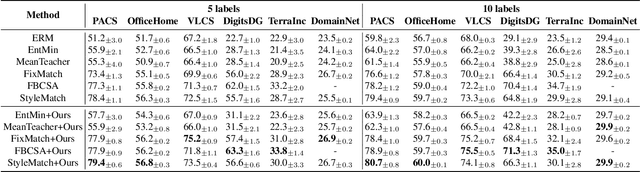
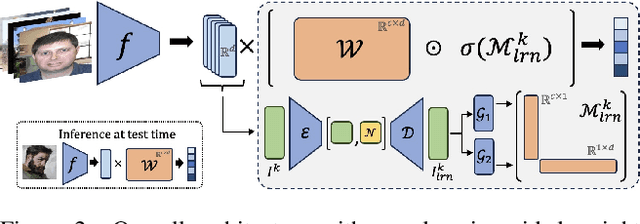

Unarguably, deep learning models capable of generalizing to unseen domain data while leveraging a few labels are of great practical significance due to low developmental costs. In search of this endeavor, we study the challenging problem of semi-supervised domain generalization (SSDG), where the goal is to learn a domain-generalizable model while using only a small fraction of labeled data and a relatively large fraction of unlabeled data. Domain generalization (DG) methods show subpar performance under the SSDG setting, whereas semi-supervised learning (SSL) methods demonstrate relatively better performance, however, they are considerably poor compared to the fully-supervised DG methods. Towards handling this new, but challenging problem of SSDG, we propose a novel method that can facilitate the generation of accurate pseudo-labels under various domain shifts. This is accomplished by retaining the domain-level specialism in the classifier during training corresponding to each source domain. Specifically, we first create domain-level information vectors on the fly which are then utilized to learn a domain-aware mask for modulating the classifier's weights. We provide a mathematical interpretation for the effect of this modulation procedure on both pseudo-labeling and model training. Our method is plug-and-play and can be readily applied to different SSL baselines for SSDG. Extensive experiments on six challenging datasets in two different SSDG settings show that our method provides visible gains over the various strong SSL-based SSDG baselines.
Monitoring AI-Modified Content at Scale: A Case Study on the Impact of ChatGPT on AI Conference Peer Reviews
Mar 11, 2024



We present an approach for estimating the fraction of text in a large corpus which is likely to be substantially modified or produced by a large language model (LLM). Our maximum likelihood model leverages expert-written and AI-generated reference texts to accurately and efficiently examine real-world LLM-use at the corpus level. We apply this approach to a case study of scientific peer review in AI conferences that took place after the release of ChatGPT: ICLR 2024, NeurIPS 2023, CoRL 2023 and EMNLP 2023. Our results suggest that between 6.5% and 16.9% of text submitted as peer reviews to these conferences could have been substantially modified by LLMs, i.e. beyond spell-checking or minor writing updates. The circumstances in which generated text occurs offer insight into user behavior: the estimated fraction of LLM-generated text is higher in reviews which report lower confidence, were submitted close to the deadline, and from reviewers who are less likely to respond to author rebuttals. We also observe corpus-level trends in generated text which may be too subtle to detect at the individual level, and discuss the implications of such trends on peer review. We call for future interdisciplinary work to examine how LLM use is changing our information and knowledge practices.
Data-Driven Subgroup Identification for Linear Regression
Apr 29, 2023Medical studies frequently require to extract the relationship between each covariate and the outcome with statistical confidence measures. To do this, simple parametric models are frequently used (e.g. coefficients of linear regression) but usually fitted on the whole dataset. However, it is common that the covariates may not have a uniform effect over the whole population and thus a unified simple model can miss the heterogeneous signal. For example, a linear model may be able to explain a subset of the data but fail on the rest due to the nonlinearity and heterogeneity in the data. In this paper, we propose DDGroup (data-driven group discovery), a data-driven method to effectively identify subgroups in the data with a uniform linear relationship between the features and the label. DDGroup outputs an interpretable region in which the linear model is expected to hold. It is simple to implement and computationally tractable for use. We show theoretically that, given a large enough sample, DDGroup recovers a region where a single linear model with low variance is well-specified (if one exists), and experiments on real-world medical datasets confirm that it can discover regions where a local linear model has improved performance. Our experiments also show that DDGroup can uncover subgroups with qualitatively different relationships which are missed by simply applying parametric approaches to the whole dataset.
Provable Membership Inference Privacy
Nov 12, 2022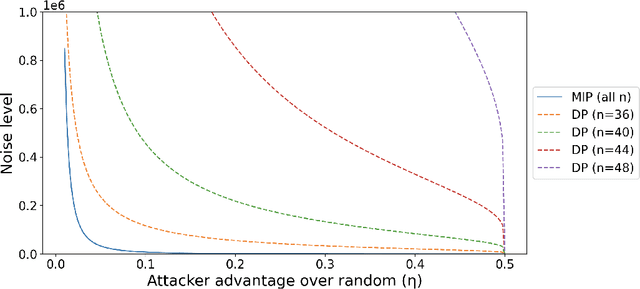
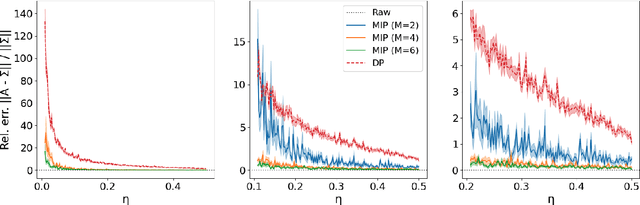
In applications involving sensitive data, such as finance and healthcare, the necessity for preserving data privacy can be a significant barrier to machine learning model development. Differential privacy (DP) has emerged as one canonical standard for provable privacy. However, DP's strong theoretical guarantees often come at the cost of a large drop in its utility for machine learning, and DP guarantees themselves can be difficult to interpret. In this work, we propose a novel privacy notion, membership inference privacy (MIP), to address these challenges. We give a precise characterization of the relationship between MIP and DP, and show that MIP can be achieved using less amount of randomness compared to the amount required for guaranteeing DP, leading to a smaller drop in utility. MIP guarantees are also easily interpretable in terms of the success rate of membership inference attacks. Our theoretical results also give rise to a simple algorithm for guaranteeing MIP which can be used as a wrapper around any algorithm with a continuous output, including parametric model training.
Importance Tempering: Group Robustness for Overparameterized Models
Sep 27, 2022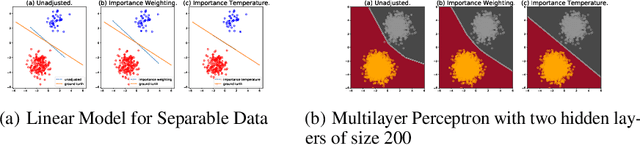

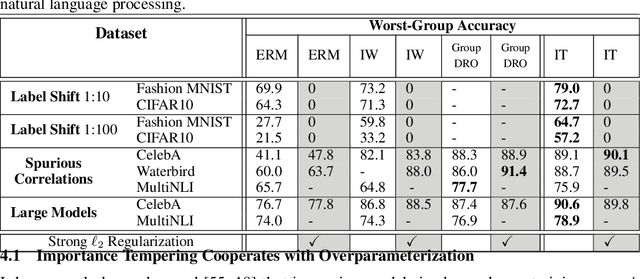

Although overparameterized models have shown their success on many machine learning tasks, the accuracy could drop on the testing distribution that is different from the training one. This accuracy drop still limits applying machine learning in the wild. At the same time, importance weighting, a traditional technique to handle distribution shifts, has been demonstrated to have less or even no effect on overparameterized models both empirically and theoretically. In this paper, we propose importance tempering to improve the decision boundary and achieve consistently better results for overparameterized models. Theoretically, we justify that the selection of group temperature can be different under label shift and spurious correlation setting. At the same time, we also prove that properly selected temperatures can extricate the minority collapse for imbalanced classification. Empirically, we achieve state-of-the-art results on worst group classification tasks using importance tempering.
How to Learn when Data Gradually Reacts to Your Model
Dec 13, 2021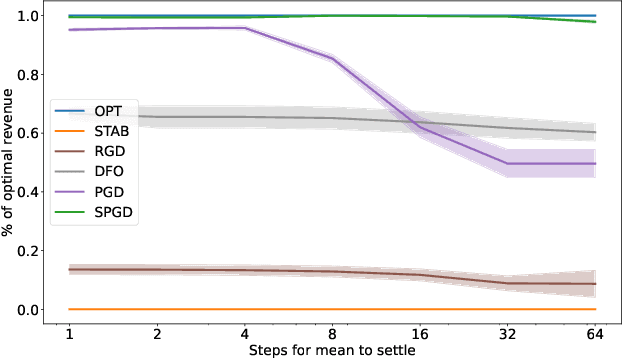
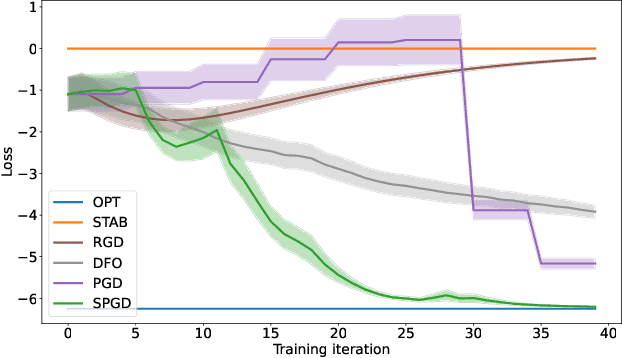
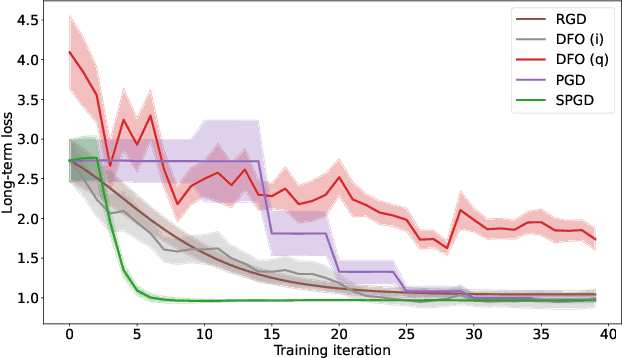
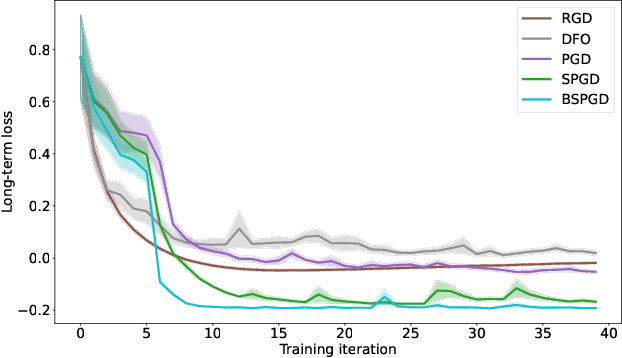
A recent line of work has focused on training machine learning (ML) models in the performative setting, i.e. when the data distribution reacts to the deployed model. The goal in this setting is to learn a model which both induces a favorable data distribution and performs well on the induced distribution, thereby minimizing the test loss. Previous work on finding an optimal model assumes that the data distribution immediately adapts to the deployed model. In practice, however, this may not be the case, as the population may take time to adapt to the model. In many applications, the data distribution depends on both the currently deployed ML model and on the "state" that the population was in before the model was deployed. In this work, we propose a new algorithm, Stateful Performative Gradient Descent (Stateful PerfGD), for minimizing the performative loss even in the presence of these effects. We provide theoretical guarantees for the convergence of Stateful PerfGD. Our experiments confirm that Stateful PerfGD substantially outperforms previous state-of-the-art methods.
Dimensionality Reduction for Wasserstein Barycenter
Oct 19, 2021
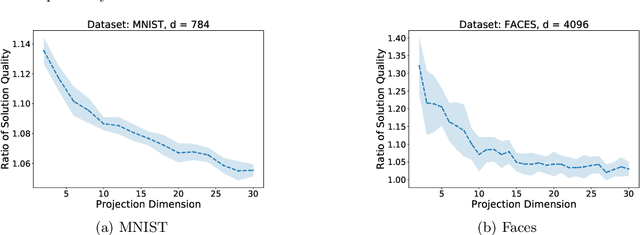

The Wasserstein barycenter is a geometric construct which captures the notion of centrality among probability distributions, and which has found many applications in machine learning. However, most algorithms for finding even an approximate barycenter suffer an exponential dependence on the dimension $d$ of the underlying space of the distributions. In order to cope with this "curse of dimensionality," we study dimensionality reduction techniques for the Wasserstein barycenter problem. When the barycenter is restricted to support of size $n$, we show that randomized dimensionality reduction can be used to map the problem to a space of dimension $O(\log n)$ independent of both $d$ and $k$, and that \emph{any} solution found in the reduced dimension will have its cost preserved up to arbitrary small error in the original space. We provide matching upper and lower bounds on the size of the reduced dimension, showing that our methods are optimal up to constant factors. We also provide a coreset construction for the Wasserstein barycenter problem that significantly decreases the number of input distributions. The coresets can be used in conjunction with random projections and thus further improve computation time. Lastly, our experimental results validate the speedup provided by dimensionality reduction while maintaining solution quality.