 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning with Low-Rank Structure for Data Selection
Jun 14, 2026In the data selection problem, the objective is to choose a small, representative subset of data that can be used to efficiently train a machine learning model. Sener and Savarese [ICLR 2018] showed that, given an embedding representation of the data and suitable geometric assumptions, heuristics based on $k$-center clustering can be used to perform data selection. This perspective was further explored by Axiotis et. al. [ICML 2024], who proposed a data selection approach based on $k$-means clustering and sensitivity sampling. However, these methods rely on the assumption that the dataset exhibits intrinsic geometric structure that can be effectively captured by clustering, whereas many modern datasets instead possess global algebraic structure that is better exploited by low-rank approximation or principal component analysis. In this paper, we introduce a new data selection framework based on low-rank approximation and residual-based sampling, formulated through the lens of row subset selection and loss-preserving coreset construction. Given an embedding representation of the data satisfying mild regularity conditions, which can be interpreted as algebraic or angular notions of Lipschitz continuity, we show that it is possible to select a weighted subset of $\tilde{O}\left(k + \frac{1}{\varepsilon^2}\right)$ data points whose average loss approximates the average loss over the full dataset within a $(1+\varepsilon)$ relative error, up to an additive $\varepsilon Φ_k$ term, where $Φ_k$ denotes the optimal rank-$k$ approximation cost of the embedding matrix. We complement these theoretical guarantees with empirical evaluations, demonstrating that on a range of real-world datasets, our data selection approach achieves improved performance over prior strategies based on uniform sampling or clustering-based sensitivity sampling.
Online Learning with Recency: Algorithms for Sliding-window Streaming Multi-armed Bandits
Jun 08, 2026Motivated by the recency effect in online learning, we study algorithms for single-pass *sliding-window streaming multi-armed bandits (MABs)* in this paper. In this setting, we are given $n$ arms with unknown sub-Gaussian reward distributions and a parameter $W$. The arms arrive in a single-pass stream, and only the most recent $W$ arms are considered valid. The algorithm is required to perform pure exploration and regret minimization with limited memory, defined as the number of stored arms. The model is a natural extension of the streaming multi-armed bandits model (without the sliding window) that has been extensively studied in recent years. We provide a comprehensive analysis of both the pure exploration and regret minimization problems with the model. For pure exploration, we prove that finding the best arm is hard with sublinear memory while finding an approximate best arm admits an efficient algorithm. For regret minimization, we explore a new notion of regret and give sharp memory-regret trade-offs for any single-pass algorithm. We complement our theoretical results with experiments, demonstrating the trade-offs between sample, regret, and memory.
Better Bounds for the Distributed Experts Problem
Mar 10, 2026In this paper, we study the distributed experts problem, where $n$ experts are distributed across $s$ servers for $T$ timesteps. The loss of each expert at each time $t$ is the $\ell_p$ norm of the vector that consists of the losses of the expert at each of the $s$ servers at time $t$. The goal is to minimize the regret $R$, i.e., the loss of the distributed protocol compared to the loss of the best expert, amortized over the all $T$ times, while using the minimum amount of communication. We give a protocol that achieves regret roughly $R\gtrsim\frac{1}{\sqrt{T}\cdot\text{poly}\log(nsT)}$, using $\mathcal{O}\left(\frac{n}{R^2}+\frac{s}{R^2}\right)\cdot\max(s^{1-2/p},1)\cdot\text{poly}\log(nsT)$ bits of communication, which improves on previous work.
Learning-Augmented Moment Estimation on Time-Decay Models
Mar 03, 2026Motivated by the prevalence and success of machine learning, a line of recent work has studied learning-augmented algorithms in the streaming model. These results have shown that for natural and practical oracles implemented with machine learning models, we can obtain streaming algorithms with improved space efficiency that are otherwise provably impossible. On the other hand, our understanding is much more limited when items are weighted unequally, for example, in the sliding-window model, where older data must be expunged from the dataset, e.g., by privacy regulation laws. In this paper, we utilize an oracle for the heavy-hitters of datasets to give learning-augmented algorithms for a number of fundamental problems, such as norm/moment estimation, frequency estimation, cascaded norms, and rectangular moment estimation, in the time-decay setting. We complement our theoretical results with a number of empirical evaluations that demonstrate the practical efficiency of our algorithms on real and synthetic datasets.
Accelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
Online Learning with Limited Information in the Sliding Window Model
Jan 07, 2026Motivated by recent work on the experts problem in the streaming model, we consider the experts problem in the sliding window model. The sliding window model is a well-studied model that captures applications such as traffic monitoring, epidemic tracking, and automated trading, where recent information is more valuable than older data. Formally, we have $n$ experts, $T$ days, the ability to query the predictions of $q$ experts on each day, a limited amount of memory, and should achieve the (near-)optimal regret $\sqrt{nW}\text{polylog}(nT)$ regret over any window of the last $W$ days. While it is impossible to achieve such regret with $1$ query, we show that with $2$ queries we can achieve such regret and with only $\text{polylog}(nT)$ bits of memory. Not only are our algorithms optimal for sliding windows, but we also show for every interval $\mathcal{I}$ of days that we achieve $\sqrt{n|\mathcal{I}|}\text{polylog}(nT)$ regret with $2$ queries and only $\text{polylog}(nT)$ bits of memory, providing an exponential improvement on the memory of previous interval regret algorithms. Building upon these techniques, we address the bandit problem in data streams, where $q=1$, achieving $n T^{2/3}\text{polylog}(T)$ regret with $\text{polylog}(nT)$ memory, which is the first sublinear regret in the streaming model in the bandit setting with polylogarithmic memory; this can be further improved to the optimal $\mathcal{O}(\sqrt{nT})$ regret if the best expert's losses are in a random order.
Learning-Augmented Hierarchical Clustering
Jun 05, 2025



Hierarchical clustering (HC) is an important data analysis technique in which the goal is to recursively partition a dataset into a tree-like structure while grouping together similar data points at each level of granularity. Unfortunately, for many of the proposed HC objectives, there exist strong barriers to approximation algorithms with the hardness of approximation. Thus, we consider the problem of hierarchical clustering given auxiliary information from natural oracles. Specifically, we focus on a *splitting oracle* which, when provided with a triplet of vertices $(u,v,w)$, answers (possibly erroneously) the pairs of vertices whose lowest common ancestor includes all three vertices in an optimal tree, i.e., identifying which vertex ``splits away'' from the others. Using such an oracle, we obtain the following results: - A polynomial-time algorithm that outputs a hierarchical clustering tree with $O(1)$-approximation to the Dasgupta objective (Dasgupta [STOC'16]). - A near-linear time algorithm that outputs a hierarchical clustering tree with $(1-o(1))$-approximation to the Moseley-Wang objective (Moseley and Wang [NeurIPS'17]). Under the plausible Small Set Expansion Hypothesis, no polynomial-time algorithm can achieve any constant approximation for Dasgupta's objective or $(1-C)$-approximation for the Moseley-Wang objective for some constant $C>0$. As such, our results demonstrate that the splitting oracle enables algorithms to outperform standard HC approaches and overcome hardness constraints. Furthermore, our approaches extend to sublinear settings, in which we show new streaming and PRAM algorithms for HC with improved guarantees.
On the Price of Differential Privacy for Hierarchical Clustering
Apr 22, 2025



Hierarchical clustering is a fundamental unsupervised machine learning task with the aim of organizing data into a hierarchy of clusters. Many applications of hierarchical clustering involve sensitive user information, therefore motivating recent studies on differentially private hierarchical clustering under the rigorous framework of Dasgupta's objective. However, it has been shown that any privacy-preserving algorithm under edge-level differential privacy necessarily suffers a large error. To capture practical applications of this problem, we focus on the weight privacy model, where each edge of the input graph is at least unit weight. We present a novel algorithm in the weight privacy model that shows significantly better approximation than known impossibility results in the edge-level DP setting. In particular, our algorithm achieves $O(\log^{1.5}n/\varepsilon)$ multiplicative error for $\varepsilon$-DP and runs in polynomial time, where $n$ is the size of the input graph, and the cost is never worse than the optimal additive error in existing work. We complement our algorithm by showing if the unit-weight constraint does not apply, the lower bound for weight-level DP hierarchical clustering is essentially the same as the edge-level DP, i.e. $\Omega(n^2/\varepsilon)$ additive error. As a result, we also obtain a new lower bound of $\tilde{\Omega}(1/\varepsilon)$ additive error for balanced sparsest cuts in the weight-level DP model, which may be of independent interest. Finally, we evaluate our algorithm on synthetic and real-world datasets. Our experimental results show that our algorithm performs well in terms of extra cost and has good scalability to large graphs.
On Socially Fair Low-Rank Approximation and Column Subset Selection
Dec 08, 2024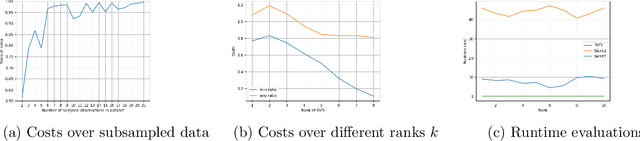
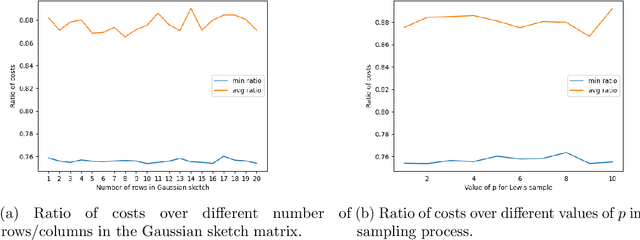
Low-rank approximation and column subset selection are two fundamental and related problems that are applied across a wealth of machine learning applications. In this paper, we study the question of socially fair low-rank approximation and socially fair column subset selection, where the goal is to minimize the loss over all sub-populations of the data. We show that surprisingly, even constant-factor approximation to fair low-rank approximation requires exponential time under certain standard complexity hypotheses. On the positive side, we give an algorithm for fair low-rank approximation that, for a constant number of groups and constant-factor accuracy, runs in $2^{\text{poly}(k)}$ time rather than the na\"{i}ve $n^{\text{poly}(k)}$, which is a substantial improvement when the dataset has a large number $n$ of observations. We then show that there exist bicriteria approximation algorithms for fair low-rank approximation and fair column subset selection that run in polynomial time.
On Approximability of $\ell_2^2$ Min-Sum Clustering
Dec 04, 2024



The $\ell_2^2$ min-sum $k$-clustering problem is to partition an input set into clusters $C_1,\ldots,C_k$ to minimize $\sum_{i=1}^k\sum_{p,q\in C_i}\|p-q\|_2^2$. Although $\ell_2^2$ min-sum $k$-clustering is NP-hard, it is not known whether it is NP-hard to approximate $\ell_2^2$ min-sum $k$-clustering beyond a certain factor. In this paper, we give the first hardness-of-approximation result for the $\ell_2^2$ min-sum $k$-clustering problem. We show that it is NP-hard to approximate the objective to a factor better than $1.056$ and moreover, assuming a balanced variant of the Johnson Coverage Hypothesis, it is NP-hard to approximate the objective to a factor better than 1.327. We then complement our hardness result by giving the first $(1+\varepsilon)$-coreset construction for $\ell_2^2$ min-sum $k$-clustering. Our coreset uses $\mathcal{O}\left(k^{\varepsilon^{-4}}\right)$ space and can be leveraged to achieve a polynomial-time approximation scheme with runtime $nd\cdot f(k,\varepsilon^{-1})$, where $d$ is the underlying dimension of the input dataset and $f$ is a fixed function. Finally, we consider a learning-augmented setting, where the algorithm has access to an oracle that outputs a label $i\in[k]$ for input point, thereby implicitly partitioning the input dataset into $k$ clusters that induce an approximately optimal solution, up to some amount of adversarial error $\alpha\in\left[0,\frac{1}{2}\right)$. We give a polynomial-time algorithm that outputs a $\frac{1+\gamma\alpha}{(1-\alpha)^2}$-approximation to $\ell_2^2$ min-sum $k$-clustering, for a fixed constant $\gamma>0$.