 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Vector Mean Estimation in the Shuffle Model: Optimal Rates Require Many Messages
Apr 16, 2024We study the problem of private vector mean estimation in the shuffle model of privacy where $n$ users each have a unit vector $v^{(i)} \in\mathbb{R}^d$. We propose a new multi-message protocol that achieves the optimal error using $\tilde{\mathcal{O}}\left(\min(n\varepsilon^2,d)\right)$ messages per user. Moreover, we show that any (unbiased) protocol that achieves optimal error requires each user to send $\Omega(\min(n\varepsilon^2,d)/\log(n))$ messages, demonstrating the optimality of our message complexity up to logarithmic factors. Additionally, we study the single-message setting and design a protocol that achieves mean squared error $\mathcal{O}(dn^{d/(d+2)}\varepsilon^{-4/(d+2)})$. Moreover, we show that any single-message protocol must incur mean squared error $\Omega(dn^{d/(d+2)})$, showing that our protocol is optimal in the standard setting where $\varepsilon = \Theta(1)$. Finally, we study robustness to malicious users and show that malicious users can incur large additive error with a single shuffler.
Lower Bounds for Differential Privacy Under Continual Observation and Online Threshold Queries
Feb 28, 2024One of the most basic problems for studying the "price of privacy over time" is the so called private counter problem, introduced by Dwork et al. (2010) and Chan et al. (2010). In this problem, we aim to track the number of events that occur over time, while hiding the existence of every single event. More specifically, in every time step $t\in[T]$ we learn (in an online fashion) that $\Delta_t\geq 0$ new events have occurred, and must respond with an estimate $n_t\approx\sum_{j=1}^t \Delta_j$. The privacy requirement is that all of the outputs together, across all time steps, satisfy event level differential privacy. The main question here is how our error needs to depend on the total number of time steps $T$ and the total number of events $n$. Dwork et al. (2015) showed an upper bound of $O\left(\log(T)+\log^2(n)\right)$, and Henzinger et al. (2023) showed a lower bound of $\Omega\left(\min\{\log n, \log T\}\right)$. We show a new lower bound of $\Omega\left(\min\{n,\log T\}\right)$, which is tight w.r.t. the dependence on $T$, and is tight in the sparse case where $\log^2 n=O(\log T)$. Our lower bound has the following implications: $\bullet$ We show that our lower bound extends to the "online thresholds problem", where the goal is to privately answer many "quantile queries" when these queries are presented one-by-one. This resolves an open question of Bun et al. (2017). $\bullet$ Our lower bound implies, for the first time, a separation between the number of mistakes obtainable by a private online learner and a non-private online learner. This partially resolves a COLT'22 open question published by Sanyal and Ramponi. $\bullet$ Our lower bound also yields the first separation between the standard model of private online learning and a recently proposed relaxed variant of it, called private online prediction.
Hot PATE: Private Aggregation of Distributions for Diverse Task
Dec 04, 2023The Private Aggregation of Teacher Ensembles (PATE) framework~\cite{PapernotAEGT:ICLR2017} is a versatile approach to privacy-preserving machine learning. In PATE, teacher models are trained on distinct portions of sensitive data, and their predictions are privately aggregated to label new training examples for a student model. Until now, PATE has primarily been explored with classification-like tasks, where each example possesses a ground-truth label, and knowledge is transferred to the student by labeling public examples. Generative AI models, however, excel in open ended \emph{diverse} tasks with multiple valid responses and scenarios that may not align with traditional labeled examples. Furthermore, the knowledge of models is often encapsulated in the response distribution itself and may be transferred from teachers to student in a more fluid way. We propose \emph{hot PATE}, tailored for the diverse setting. In hot PATE, each teacher model produces a response distribution and the aggregation method must preserve both privacy and diversity of responses. We demonstrate, analytically and empirically, that hot PATE achieves privacy-utility tradeoffs that are comparable to, and in diverse settings, significantly surpass, the baseline ``cold'' PATE.
Fast Optimal Locally Private Mean Estimation via Random Projections
Jun 26, 2023We study the problem of locally private mean estimation of high-dimensional vectors in the Euclidean ball. Existing algorithms for this problem either incur sub-optimal error or have high communication and/or run-time complexity. We propose a new algorithmic framework, ProjUnit, for private mean estimation that yields algorithms that are computationally efficient, have low communication complexity, and incur optimal error up to a $1+o(1)$-factor. Our framework is deceptively simple: each randomizer projects its input to a random low-dimensional subspace, normalizes the result, and then runs an optimal algorithm such as PrivUnitG in the lower-dimensional space. In addition, we show that, by appropriately correlating the random projection matrices across devices, we can achieve fast server run-time. We mathematically analyze the error of the algorithm in terms of properties of the random projections, and study two instantiations. Lastly, our experiments for private mean estimation and private federated learning demonstrate that our algorithms empirically obtain nearly the same utility as optimal ones while having significantly lower communication and computational cost.
Sparse Dimensionality Reduction Revisited
Feb 13, 2023The sparse Johnson-Lindenstrauss transform is one of the central techniques in dimensionality reduction. It supports embedding a set of $n$ points in $\mathbb{R}^d$ into $m=O(\varepsilon^{-2} \lg n)$ dimensions while preserving all pairwise distances to within $1 \pm \varepsilon$. Each input point $x$ is embedded to $Ax$, where $A$ is an $m \times d$ matrix having $s$ non-zeros per column, allowing for an embedding time of $O(s \|x\|_0)$. Since the sparsity of $A$ governs the embedding time, much work has gone into improving the sparsity $s$. The current state-of-the-art by Kane and Nelson (JACM'14) shows that $s = O(\varepsilon ^{-1} \lg n)$ suffices. This is almost matched by a lower bound of $s = \Omega(\varepsilon ^{-1} \lg n/\lg(1/\varepsilon))$ by Nelson and Nguyen (STOC'13). Previous work thus suggests that we have near-optimal embeddings. In this work, we revisit sparse embeddings and identify a loophole in the lower bound. Concretely, it requires $d \geq n$, which in many applications is unrealistic. We exploit this loophole to give a sparser embedding when $d = o(n)$, achieving $s = O(\varepsilon^{-1}(\lg n/\lg(1/\varepsilon)+\lg^{2/3}n \lg^{1/3} d))$. We also complement our analysis by strengthening the lower bound of Nelson and Nguyen to hold also when $d \ll n$, thereby matching the first term in our new sparsity upper bound. Finally, we also improve the sparsity of the best oblivious subspace embeddings for optimal embedding dimensionality.
Õptimal Differentially Private Learning of Thresholds and Quasi-Concave Optimization
Nov 11, 2022The problem of learning threshold functions is a fundamental one in machine learning. Classical learning theory implies sample complexity of $O(\xi^{-1} \log(1/\beta))$ (for generalization error $\xi$ with confidence $1-\beta$). The private version of the problem, however, is more challenging and in particular, the sample complexity must depend on the size $|X|$ of the domain. Progress on quantifying this dependence, via lower and upper bounds, was made in a line of works over the past decade. In this paper, we finally close the gap for approximate-DP and provide a nearly tight upper bound of $\tilde{O}(\log^* |X|)$, which matches a lower bound by Alon et al (that applies even with improper learning) and improves over a prior upper bound of $\tilde{O}((\log^* |X|)^{1.5})$ by Kaplan et al. We also provide matching upper and lower bounds of $\tilde{\Theta}(2^{\log^*|X|})$ for the additive error of private quasi-concave optimization (a related and more general problem). Our improvement is achieved via the novel Reorder-Slice-Compute paradigm for private data analysis which we believe will have further applications.
Tricking the Hashing Trick: A Tight Lower Bound on the Robustness of CountSketch to Adaptive Inputs
Jul 03, 2022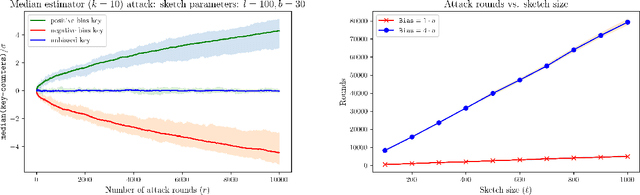
CountSketch and Feature Hashing (the "hashing trick") are popular randomized dimensionality reduction methods that support recovery of $\ell_2$-heavy hitters (keys $i$ where $v_i^2 > \epsilon \|\boldsymbol{v}\|_2^2$) and approximate inner products. When the inputs are {\em not adaptive} (do not depend on prior outputs), classic estimators applied to a sketch of size $O(\ell/\epsilon)$ are accurate for a number of queries that is exponential in $\ell$. When inputs are adaptive, however, an adversarial input can be constructed after $O(\ell)$ queries with the classic estimator and the best known robust estimator only supports $\tilde{O}(\ell^2)$ queries. In this work we show that this quadratic dependence is in a sense inherent: We design an attack that after $O(\ell^2)$ queries produces an adversarial input vector whose sketch is highly biased. Our attack uses "natural" non-adaptive inputs (only the final adversarial input is chosen adaptively) and universally applies with any correct estimator, including one that is unknown to the attacker. In that, we expose inherent vulnerability of this fundamental method.
Estimation of Entropy in Constant Space with Improved Sample Complexity
May 19, 2022
Recent work of Acharya et al. (NeurIPS 2019) showed how to estimate the entropy of a distribution $\mathcal D$ over an alphabet of size $k$ up to $\pm\epsilon$ additive error by streaming over $(k/\epsilon^3) \cdot \text{polylog}(1/\epsilon)$ i.i.d. samples and using only $O(1)$ words of memory. In this work, we give a new constant memory scheme that reduces the sample complexity to $(k/\epsilon^2)\cdot \text{polylog}(1/\epsilon)$. We conjecture that this is optimal up to $\text{polylog}(1/\epsilon)$ factors.
Uniform Approximations for Randomized Hadamard Transforms with Applications
Mar 03, 2022Randomized Hadamard Transforms (RHTs) have emerged as a computationally efficient alternative to the use of dense unstructured random matrices across a range of domains in computer science and machine learning. For several applications such as dimensionality reduction and compressed sensing, the theoretical guarantees for methods based on RHTs are comparable to approaches using dense random matrices with i.i.d.\ entries. However, several such applications are in the low-dimensional regime where the number of rows sampled from the matrix is rather small. Prior arguments are not applicable to the high-dimensional regime often found in machine learning applications like kernel approximation. Given an ensemble of RHTs with Gaussian diagonals, $\{M^i\}_{i = 1}^m$, and any $1$-Lipschitz function, $f: \mathbb{R} \to \mathbb{R}$, we prove that the average of $f$ over the entries of $\{M^i v\}_{i = 1}^m$ converges to its expectation uniformly over $\| v \| \leq 1$ at a rate comparable to that obtained from using truly Gaussian matrices. We use our inequality to then derive improved guarantees for two applications in the high-dimensional regime: 1) kernel approximation and 2) distance estimation. For kernel approximation, we prove the first \emph{uniform} approximation guarantees for random features constructed through RHTs lending theoretical justification to their empirical success while for distance estimation, our convergence result implies data structures with improved runtime guarantees over previous work by the authors. We believe our general inequality is likely to find use in other applications.
Private Frequency Estimation via Projective Geometry
Mar 01, 2022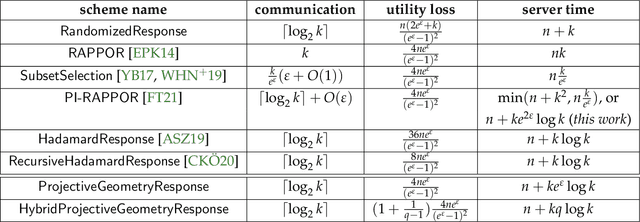
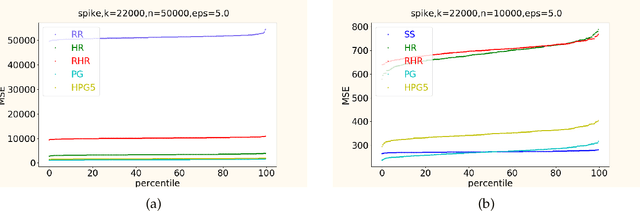
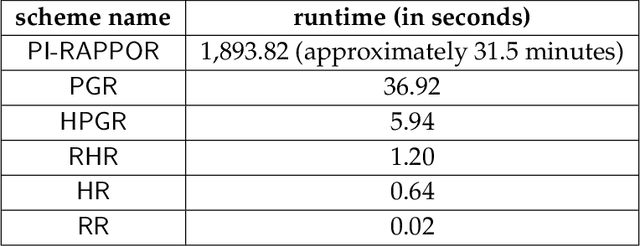
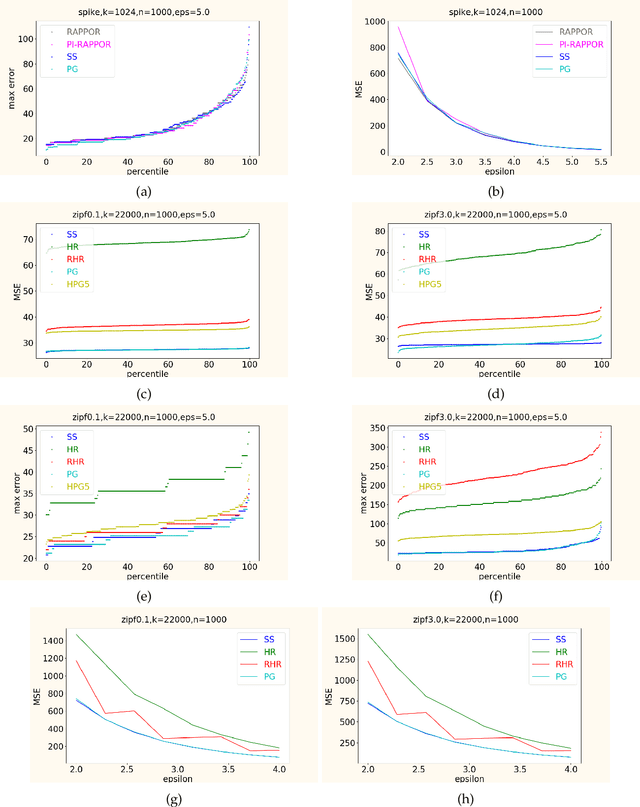
In this work, we propose a new algorithm ProjectiveGeometryResponse (PGR) for locally differentially private (LDP) frequency estimation. For a universe size of $k$ and with $n$ users, our $\varepsilon$-LDP algorithm has communication cost $\lceil\log_2k\rceil$ bits in the private coin setting and $\varepsilon\log_2 e + O(1)$ in the public coin setting, and has computation cost $O(n + k\exp(\varepsilon) \log k)$ for the server to approximately reconstruct the frequency histogram, while achieving the state-of-the-art privacy-utility tradeoff. In many parameter settings used in practice this is a significant improvement over the $ O(n+k^2)$ computation cost that is achieved by the recent PI-RAPPOR algorithm (Feldman and Talwar; 2021). Our empirical evaluation shows a speedup of over 50x over PI-RAPPOR while using approximately 75x less memory for practically relevant parameter settings. In addition, the running time of our algorithm is within an order of magnitude of HadamardResponse (Acharya, Sun, and Zhang; 2019) and RecursiveHadamardResponse (Chen, Kairouz, and Ozgur; 2020) which have significantly worse reconstruction error. The error of our algorithm essentially matches that of the communication- and time-inefficient but utility-optimal SubsetSelection (SS) algorithm (Ye and Barg; 2017). Our new algorithm is based on using Projective Planes over a finite field to define a small collection of sets that are close to being pairwise independent and a dynamic programming algorithm for approximate histogram reconstruction on the server side. We also give an extension of PGR, which we call HybridProjectiveGeometryResponse, that allows trading off computation time with utility smoothly.