 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCram Less to Fit More: Training Data Pruning Improves Memorization of Facts
Apr 09, 2026Large language models (LLMs) can struggle to memorize factual knowledge in their parameters, often leading to hallucinations and poor performance on knowledge-intensive tasks. In this paper, we formalize fact memorization from an information-theoretic perspective and study how training data distributions affect fact accuracy. We show that fact accuracy is suboptimal (below the capacity limit) whenever the amount of information contained in the training data facts exceeds model capacity. This is further exacerbated when the fact frequency distribution is skewed (e.g. a power law). We propose data selection schemes based on the training loss alone that aim to limit the number of facts in the training data and flatten their frequency distribution. On semi-synthetic datasets containing high-entropy facts, our selection method effectively boosts fact accuracy to the capacity limit. When pretraining language models from scratch on an annotated Wikipedia corpus, our selection method enables a GPT2-Small model (110m parameters) to memorize 1.3X more entity facts compared to standard training, matching the performance of a 10X larger model (1.3B parameters) pretrained on the full dataset.
The Importance of Being Smoothly Calibrated
Mar 16, 2026Recent work has highlighted the centrality of smooth calibration [Kakade and Foster, 2008] as a robust measure of calibration error. We generalize, unify, and extend previous results on smooth calibration, both as a robust calibration measure, and as a step towards omniprediction, which enables predictions with low regret for downstream decision makers seeking to optimize some proper loss unknown to the predictor. We present a new omniprediction guarantee for smoothly calibrated predictors, for the class of all bounded proper losses. We smooth the predictor by adding some noise to it, and compete against smoothed versions of any benchmark predictor on the space, where we add some noise to the predictor and then post-process it arbitrarily. The omniprediction error is bounded by the smooth calibration error of the predictor and the earth mover's distance from the benchmark. We exhibit instances showing that this dependence cannot, in general, be improved. We show how this unifies and extends prior results [Foster and Vohra, 1998; Hartline, Wu, and Yang, 2025] on omniprediction from smooth calibration. We present a crisp new characterization of smooth calibration in terms of the earth mover's distance to the closest perfectly calibrated joint distribution of predictions and labels. This also yields a simpler proof of the relation to the lower distance to calibration from [Blasiok, Gopalan, Hu, and Nakkiran, 2023]. We use this to show that the upper distance to calibration cannot be estimated within a quadratic factor with sample complexity independent of the support size of the predictions. This is in contrast to the distance to calibration, where the corresponding problem was known to be information-theoretically impossible: no finite number of samples suffice [Blasiok, Gopalan, Hu, and Nakkiran, 2023].
Efficient Calibration for Decision Making
Nov 17, 2025A decision-theoretic characterization of perfect calibration is that an agent seeking to minimize a proper loss in expectation cannot improve their outcome by post-processing a perfectly calibrated predictor. Hu and Wu (FOCS'24) use this to define an approximate calibration measure called calibration decision loss ($\mathsf{CDL}$), which measures the maximal improvement achievable by any post-processing over any proper loss. Unfortunately, $\mathsf{CDL}$ turns out to be intractable to even weakly approximate in the offline setting, given black-box access to the predictions and labels. We suggest circumventing this by restricting attention to structured families of post-processing functions $K$. We define the calibration decision loss relative to $K$, denoted $\mathsf{CDL}_K$ where we consider all proper losses but restrict post-processings to a structured family $K$. We develop a comprehensive theory of when $\mathsf{CDL}_K$ is information-theoretically and computationally tractable, and use it to prove both upper and lower bounds for natural classes $K$. In addition to introducing new definitions and algorithmic techniques to the theory of calibration for decision making, our results give rigorous guarantees for some widely used recalibration procedures in machine learning.
Instance-Optimality for Private KL Distribution Estimation
May 29, 2025We study the fundamental problem of estimating an unknown discrete distribution $p$ over $d$ symbols, given $n$ i.i.d. samples from the distribution. We are interested in minimizing the KL divergence between the true distribution and the algorithm's estimate. We first construct minimax optimal private estimators. Minimax optimality however fails to shed light on an algorithm's performance on individual (non-worst-case) instances $p$ and simple minimax-optimal DP estimators can have poor empirical performance on real distributions. We then study this problem from an instance-optimality viewpoint, where the algorithm's error on $p$ is compared to the minimum achievable estimation error over a small local neighborhood of $p$. Under natural notions of local neighborhood, we propose algorithms that achieve instance-optimality up to constant factors, with and without a differential privacy constraint. Our upper bounds rely on (private) variants of the Good-Turing estimator. Our lower bounds use additive local neighborhoods that more precisely captures the hardness of distribution estimation in KL divergence, compared to ones considered in prior works.
Faster Rates for Private Adversarial Bandits
May 27, 2025


We design new differentially private algorithms for the problems of adversarial bandits and bandits with expert advice. For adversarial bandits, we give a simple and efficient conversion of any non-private bandit algorithm to a private bandit algorithm. Instantiating our conversion with existing non-private bandit algorithms gives a regret upper bound of $O\left(\frac{\sqrt{KT}}{\sqrt{\epsilon}}\right)$, improving upon the existing upper bound $O\left(\frac{\sqrt{KT \log(KT)}}{\epsilon}\right)$ for all $\epsilon \leq 1$. In particular, our algorithms allow for sublinear expected regret even when $\epsilon \leq \frac{1}{\sqrt{T}}$, establishing the first known separation between central and local differential privacy for this problem. For bandits with expert advice, we give the first differentially private algorithms, with expected regret $O\left(\frac{\sqrt{NT}}{\sqrt{\epsilon}}\right), O\left(\frac{\sqrt{KT\log(N)}\log(KT)}{\epsilon}\right)$, and $\tilde{O}\left(\frac{N^{1/6}K^{1/2}T^{2/3}\log(NT)}{\epsilon ^{1/3}} + \frac{N^{1/2}\log(NT)}{\epsilon}\right)$, where $K$ and $N$ are the number of actions and experts respectively. These rates allow us to get sublinear regret for different combinations of small and large $K, N$ and $\epsilon.$
On Privately Estimating a Single Parameter
Mar 21, 2025



We investigate differentially private estimators for individual parameters within larger parametric models. While generic private estimators exist, the estimators we provide repose on new local notions of estimand stability, and these notions allow procedures that provide private certificates of their own stability. By leveraging these private certificates, we provide computationally and statistical efficient mechanisms that release private statistics that are, at least asymptotically in the sample size, essentially unimprovable: they achieve instance optimal bounds. Additionally, we investigate the practicality of the algorithms both in simulated data and in real-world data from the American Community Survey and US Census, highlighting scenarios in which the new procedures are successful and identifying areas for future work.
PREAMBLE: Private and Efficient Aggregation of Block Sparse Vectors and Applications
Mar 14, 2025



We revisit the problem of secure aggregation of high-dimensional vectors in a two-server system such as Prio. These systems are typically used to aggregate vectors such as gradients in private federated learning, where the aggregate itself is protected via noise addition to ensure differential privacy. Existing approaches require communication scaling with the dimensionality, and thus limit the dimensionality of vectors one can efficiently process in this setup. We propose PREAMBLE: Private Efficient Aggregation Mechanism for BLock-sparse Euclidean Vectors. PREAMBLE is a novel extension of distributed point functions that enables communication- and computation-efficient aggregation of block-sparse vectors, which are sparse vectors where the non-zero entries occur in a small number of clusters of consecutive coordinates. We then show that PREAMBLE can be combined with random sampling and privacy amplification by sampling results, to allow asymptotically optimal privacy-utility trade-offs for vector aggregation, at a fraction of the communication cost. When coupled with recent advances in numerical privacy accounting, our approach incurs a negligible overhead in noise variance, compared to the Gaussian mechanism used with Prio.
Local Pan-Privacy for Federated Analytics
Mar 14, 2025Pan-privacy was proposed by Dwork et al. as an approach to designing a private analytics system that retains its privacy properties in the face of intrusions that expose the system's internal state. Motivated by federated telemetry applications, we study local pan-privacy, where privacy should be retained under repeated unannounced intrusions on the local state. We consider the problem of monitoring the count of an event in a federated system, where event occurrences on a local device should be hidden even from an intruder on that device. We show that under reasonable constraints, the goal of providing information-theoretic differential privacy under intrusion is incompatible with collecting telemetry information. We then show that this problem can be solved in a scalable way using standard cryptographic primitives.
Fingerprinting Codes Meet Geometry: Improved Lower Bounds for Private Query Release and Adaptive Data Analysis
Dec 18, 2024
Fingerprinting codes are a crucial tool for proving lower bounds in differential privacy. They have been used to prove tight lower bounds for several fundamental questions, especially in the ``low accuracy'' regime. Unlike reconstruction/discrepancy approaches however, they are more suited for query sets that arise naturally from the fingerprinting codes construction. In this work, we propose a general framework for proving fingerprinting type lower bounds, that allows us to tailor the technique to the geometry of the query set. Our approach allows us to prove several new results, including the following. First, we show that any (sample- and population-)accurate algorithm for answering $Q$ arbitrary adaptive counting queries over a universe $\mathcal{X}$ to accuracy $\alpha$ needs $\Omega(\frac{\sqrt{\log |\mathcal{X}|}\cdot \log Q}{\alpha^3})$ samples, matching known upper bounds. This shows that the approaches based on differential privacy are optimal for this question, and improves significantly on the previously known lower bounds of $\frac{\log Q}{\alpha^2}$ and $\min(\sqrt{Q}, \sqrt{\log |\mathcal{X}|})/\alpha^2$. Second, we show that any $(\varepsilon,\delta)$-DP algorithm for answering $Q$ counting queries to accuracy $\alpha$ needs $\Omega(\frac{\sqrt{ \log|\mathcal{X}| \log(1/\delta)} \log Q}{\varepsilon\alpha^2})$ samples, matching known upper bounds up to constants. Our framework allows for proving this bound via a direct correlation analysis and improves the prior bound of [BUV'14] by $\sqrt{\log(1/\delta)}$. Third, we characterize the sample complexity of answering a set of random $0$-$1$ queries under approximate differential privacy. We give new upper and lower bounds in different regimes. By combining them with known results, we can complete the whole picture.
Privacy-Computation trade-offs in Private Repetition and Metaselection
Oct 22, 2024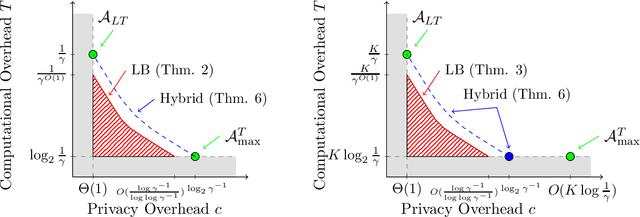
A Private Repetition algorithm takes as input a differentially private algorithm with constant success probability and boosts it to one that succeeds with high probability. These algorithms are closely related to private metaselection algorithms that compete with the best of many private algorithms, and private hyperparameter tuning algorithms that compete with the best hyperparameter settings for a private learning algorithm. Existing algorithms for these tasks pay either a large overhead in privacy cost, or a large overhead in computational cost. In this work, we show strong lower bounds for problems of this kind, showing in particular that for any algorithm that preserves the privacy cost up to a constant factor, the failure probability can only fall polynomially in the computational overhead. This is in stark contrast with the non-private setting, where the failure probability falls exponentially in the computational overhead. By carefully combining existing algorithms for metaselection, we prove computation-privacy tradeoffs that nearly match our lower bounds.