 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impossibility of Separating Intelligence from Judgment: The Computational Intractability of Filtering for AI Alignment
Jul 09, 2025With the increased deployment of large language models (LLMs), one concern is their potential misuse for generating harmful content. Our work studies the alignment challenge, with a focus on filters to prevent the generation of unsafe information. Two natural points of intervention are the filtering of the input prompt before it reaches the model, and filtering the output after generation. Our main results demonstrate computational challenges in filtering both prompts and outputs. First, we show that there exist LLMs for which there are no efficient prompt filters: adversarial prompts that elicit harmful behavior can be easily constructed, which are computationally indistinguishable from benign prompts for any efficient filter. Our second main result identifies a natural setting in which output filtering is computationally intractable. All of our separation results are under cryptographic hardness assumptions. In addition to these core findings, we also formalize and study relaxed mitigation approaches, demonstrating further computational barriers. We conclude that safety cannot be achieved by designing filters external to the LLM internals (architecture and weights); in particular, black-box access to the LLM will not suffice. Based on our technical results, we argue that an aligned AI system's intelligence cannot be separated from its judgment.
Accuracy vs. Accuracy: Computational Tradeoffs Between Classification Rates and Utility
May 22, 2025We revisit the foundations of fairness and its interplay with utility and efficiency in settings where the training data contain richer labels, such as individual types, rankings, or risk estimates, rather than just binary outcomes. In this context, we propose algorithms that achieve stronger notions of evidence-based fairness than are possible in standard supervised learning. Our methods support classification and ranking techniques that preserve accurate subpopulation classification rates, as suggested by the underlying data distributions, across a broad class of classification rules and downstream applications. Furthermore, our predictors enable loss minimization, whether aimed at maximizing utility or in the service of fair treatment. Complementing our algorithmic contributions, we present impossibility results demonstrating that simultaneously achieving accurate classification rates and optimal loss minimization is, in some cases, computationally infeasible. Unlike prior impossibility results, our notions are not inherently in conflict and are simultaneously satisfied by the Bayes-optimal predictor. Furthermore, we show that each notion can be satisfied individually via efficient learning. Our separation thus stems from the computational hardness of learning a sufficiently good approximation of the Bayes-optimal predictor. These computational impossibilities present a choice between two natural and attainable notions of accuracy that could both be motivated by fairness.
Local Pan-Privacy for Federated Analytics
Mar 14, 2025Pan-privacy was proposed by Dwork et al. as an approach to designing a private analytics system that retains its privacy properties in the face of intrusions that expose the system's internal state. Motivated by federated telemetry applications, we study local pan-privacy, where privacy should be retained under repeated unannounced intrusions on the local state. We consider the problem of monitoring the count of an event in a federated system, where event occurrences on a local device should be hidden even from an intruder on that device. We show that under reasonable constraints, the goal of providing information-theoretic differential privacy under intrusion is incompatible with collecting telemetry information. We then show that this problem can be solved in a scalable way using standard cryptographic primitives.
PREAMBLE: Private and Efficient Aggregation of Block Sparse Vectors and Applications
Mar 14, 2025



We revisit the problem of secure aggregation of high-dimensional vectors in a two-server system such as Prio. These systems are typically used to aggregate vectors such as gradients in private federated learning, where the aggregate itself is protected via noise addition to ensure differential privacy. Existing approaches require communication scaling with the dimensionality, and thus limit the dimensionality of vectors one can efficiently process in this setup. We propose PREAMBLE: Private Efficient Aggregation Mechanism for BLock-sparse Euclidean Vectors. PREAMBLE is a novel extension of distributed point functions that enables communication- and computation-efficient aggregation of block-sparse vectors, which are sparse vectors where the non-zero entries occur in a small number of clusters of consecutive coordinates. We then show that PREAMBLE can be combined with random sampling and privacy amplification by sampling results, to allow asymptotically optimal privacy-utility trade-offs for vector aggregation, at a fraction of the communication cost. When coupled with recent advances in numerical privacy accounting, our approach incurs a negligible overhead in noise variance, compared to the Gaussian mechanism used with Prio.
On Computationally Efficient Multi-Class Calibration
Feb 12, 2024Consider a multi-class labelling problem, where the labels can take values in $[k]$, and a predictor predicts a distribution over the labels. In this work, we study the following foundational question: Are there notions of multi-class calibration that give strong guarantees of meaningful predictions and can be achieved in time and sample complexities polynomial in $k$? Prior notions of calibration exhibit a tradeoff between computational efficiency and expressivity: they either suffer from having sample complexity exponential in $k$, or needing to solve computationally intractable problems, or give rather weak guarantees. Our main contribution is a notion of calibration that achieves all these desiderata: we formulate a robust notion of projected smooth calibration for multi-class predictions, and give new recalibration algorithms for efficiently calibrating predictors under this definition with complexity polynomial in $k$. Projected smooth calibration gives strong guarantees for all downstream decision makers who want to use the predictor for binary classification problems of the form: does the label belong to a subset $T \subseteq [k]$: e.g. is this an image of an animal? It ensures that the probabilities predicted by summing the probabilities assigned to labels in $T$ are close to some perfectly calibrated binary predictor for that task. We also show that natural strengthenings of our definition are computationally hard to achieve: they run into information theoretic barriers or computational intractability. Underlying both our upper and lower bounds is a tight connection that we prove between multi-class calibration and the well-studied problem of agnostic learning in the (standard) binary prediction setting.
Decision-Making under Miscalibration
Mar 18, 2022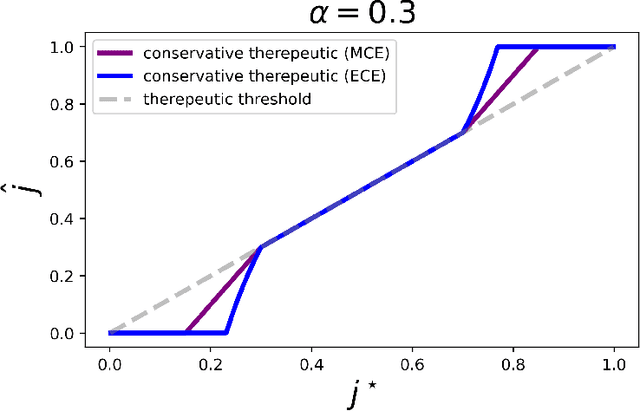
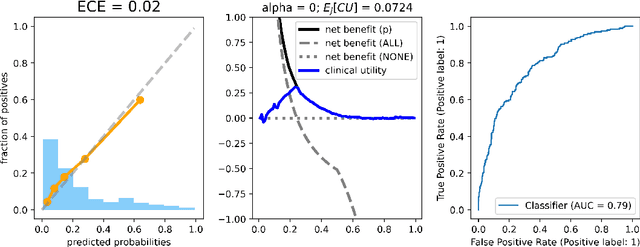
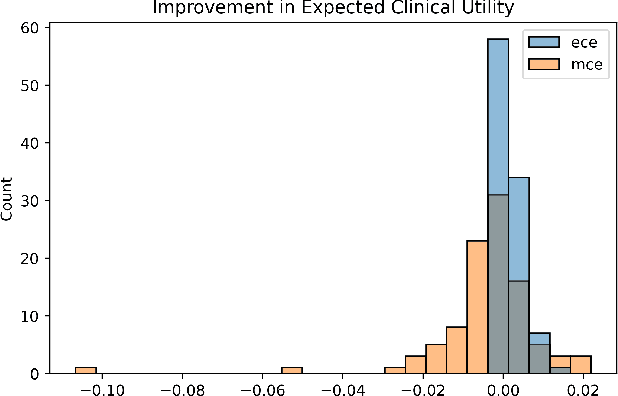
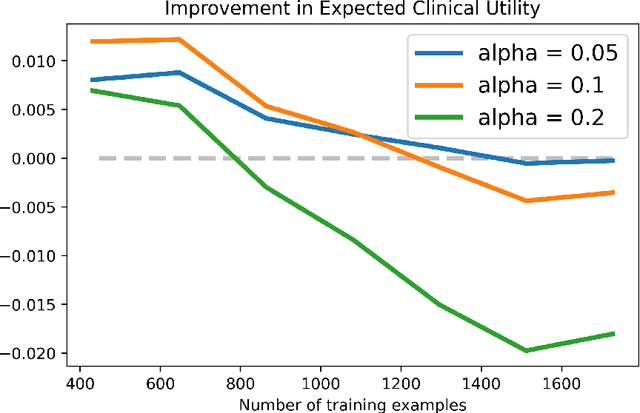
ML-based predictions are used to inform consequential decisions about individuals. How should we use predictions (e.g., risk of heart attack) to inform downstream binary classification decisions (e.g., undergoing a medical procedure)? When the risk estimates are perfectly calibrated, the answer is well understood: a classification problem's cost structure induces an optimal treatment threshold $j^{\star}$. In practice, however, some amount of miscalibration is unavoidable, raising a fundamental question: how should one use potentially miscalibrated predictions to inform binary decisions? We formalize a natural (distribution-free) solution concept: given anticipated miscalibration of $\alpha$, we propose using the threshold $j$ that minimizes the worst-case regret over all $\alpha$-miscalibrated predictors, where the regret is the difference in clinical utility between using the threshold in question and using the optimal threshold in hindsight. We provide closed form expressions for $j$ when miscalibration is measured using both expected and maximum calibration error, which reveal that it indeed differs from $j^{\star}$ (the optimal threshold under perfect calibration). We validate our theoretical findings on real data, demonstrating that there are natural cases in which making decisions using $j$ improves the clinical utility.
Consider the Alternatives: Navigating Fairness-Accuracy Tradeoffs via Disqualification
Oct 02, 2021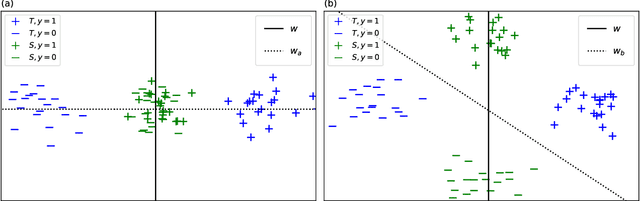

In many machine learning settings there is an inherent tension between fairness and accuracy desiderata. How should one proceed in light of such trade-offs? In this work we introduce and study $\gamma$-disqualification, a new framework for reasoning about fairness-accuracy tradeoffs w.r.t a benchmark class $H$ in the context of supervised learning. Our requirement stipulates that a classifier should be disqualified if it is possible to improve its fairness by switching to another classifier from $H$ without paying "too much" in accuracy. The notion of "too much" is quantified via a parameter $\gamma$ that serves as a vehicle for specifying acceptable tradeoffs between accuracy and fairness, in a way that is independent from the specific metrics used to quantify fairness and accuracy in a given task. Towards this objective, we establish principled translations between units of accuracy and units of (un)fairness for different accuracy measures. We show $\gamma$-disqualification can be used to easily compare different learning strategies in terms of how they trade-off fairness and accuracy, and we give an efficient reduction from the problem of finding the optimal classifier that satisfies our requirement to the problem of approximating the Pareto frontier of $H$.
Outcome Indistinguishability
Nov 26, 2020Prediction algorithms assign numbers to individuals that are popularly understood as individual "probabilities" -- what is the probability of 5-year survival after cancer diagnosis? -- and which increasingly form the basis for life-altering decisions. Drawing on an understanding of computational indistinguishability developed in complexity theory and cryptography, we introduce Outcome Indistinguishability. Predictors that are Outcome Indistinguishable yield a generative model for outcomes that cannot be efficiently refuted on the basis of the real-life observations produced by Nature. We investigate a hierarchy of Outcome Indistinguishability definitions, whose stringency increases with the degree to which distinguishers may access the predictor in question. Our findings reveal that Outcome Indistinguishability behaves qualitatively differently than previously studied notions of indistinguishability. First, we provide constructions at all levels of the hierarchy. Then, leveraging recently-developed machinery for proving average-case fine-grained hardness, we obtain lower bounds on the complexity of the more stringent forms of Outcome Indistinguishability. This hardness result provides the first scientific grounds for the political argument that, when inspecting algorithmic risk prediction instruments, auditors should be granted oracle access to the algorithm, not simply historical predictions.
Abstracting Fairness: Oracles, Metrics, and Interpretability
Apr 04, 2020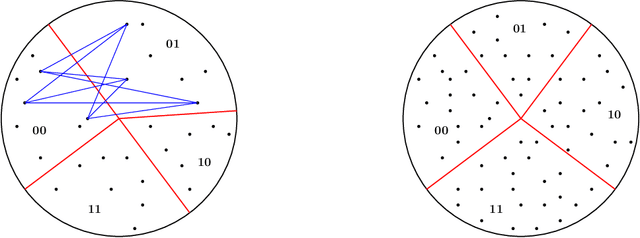
It is well understood that classification algorithms, for example, for deciding on loan applications, cannot be evaluated for fairness without taking context into account. We examine what can be learned from a fairness oracle equipped with an underlying understanding of ``true'' fairness. The oracle takes as input a (context, classifier) pair satisfying an arbitrary fairness definition, and accepts or rejects the pair according to whether the classifier satisfies the underlying fairness truth. Our principal conceptual result is an extraction procedure that learns the underlying truth; moreover, the procedure can learn an approximation to this truth given access to a weak form of the oracle. Since every ``truly fair'' classifier induces a coarse metric, in which those receiving the same decision are at distance zero from one another and those receiving different decisions are at distance one, this extraction process provides the basis for ensuring a rough form of metric fairness, also known as individual fairness. Our principal technical result is a higher fidelity extractor under a mild technical constraint on the weak oracle's conception of fairness. Our framework permits the scenario in which many classifiers, with differing outcomes, may all be considered fair. Our results have implications for interpretablity -- a highly desired but poorly defined property of classification systems that endeavors to permit a human arbiter to reject classifiers deemed to be ``unfair'' or illegitimately derived.
Preference-Informed Fairness
Apr 03, 2019As algorithms are increasingly used to make important decisions pertaining to individuals, algorithmic discrimination is becoming a prominent concern. The seminal work of Dwork et al. [ITCS 2012] introduced the notion of individual fairness (IF): given a task-specific similarity metric, every pair of similar individuals should receive similar outcomes. In this work, we study fairness when individuals have diverse preferences over the possible outcomes. We show that in such settings, individual fairness can be too restrictive: requiring individual fairness can lead to less-preferred outcomes for the very individuals that IF aims to protect (e.g. a protected minority group). We introduce and study a new notion of preference-informed individual fairness (PIIF), a relaxation of individual fairness that allows for outcomes that deviate from IF, provided the deviations are in line with individuals' preferences. We show that PIIF can allow for solutions that are considerably more beneficial to individuals than the best IF solution. We further show how to efficiently optimize any convex objective over the outcomes subject to PIIF, for a rich class of individual preferences. Motivated by fairness concerns in targeted advertising, we apply this new fairness notion to the multiple-task setting introduced by Dwork and Ilvento [ITCS 2019]. We show that, in this setting too, PIIF can allow for considerably more beneficial solutions, and we extend our efficient optimization algorithm to this setting.