 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI Agents Synthesize Scientific Conclusions?
Jun 09, 2026Scientific AI agents increasingly retrieve evidence, reason across sources, and synthesize conclusions used in consequential decisions. Yet, their ability to do so in high-stakes domains such as health remains unclear. We introduce SciConBench, a large-scale live benchmark of 9.11K questions and expert-written conclusions from systematic reviews to evaluate open-domain scientific conclusion synthesis. The benchmark draws on an expert-validated automated evaluation pipeline that decomposes conclusions into atomic facts and measures correctness and comprehensiveness via factual precision and recall. To mitigate data leakage, we further introduce SciConHarness, a clean-room evaluation harness that equips agents with controlled web interaction to ensure valid measurement. Evaluating 8 frontier models and deep research agents, we find that factual quality remains low: under clean-room settings, the best agent achieves only a factual F1 of 0.337. Our clean-room setting consistently reduces performance relative to unconstrained evaluation, suggesting that leakage inflates estimates of models' true synthesis capabilities. Finally, we audit consumer-facing agents (e.g., Google AI Overview, OpenEvidence) and find they frequently generate incomplete and sometimes contradictory conclusions, even when the ground-truth answer is available. Overall, our results show that reliable synthesis of scientific conclusions remains an open challenge, and that clean-room evaluation is essential for assessing open-domain AI agents.
WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark
Jun 04, 2026In real-world applications, models are expected to perform reliably across diverse settings. Yet, many existing multimodal benchmarks expand task types without capturing the visual diversity needed to handle open-ended visual inputs. We present WorldBench, a challenging and visually diverse reasoning benchmark to evaluate Multimodal Large Language Models (MLLMs). We build a taxonomy of thousands of visual concepts across multiple domains (e.g., living things). Guided by this taxonomy, we curate a broad collection of images from search engines and existing datasets to comprehensively represent the visual world. Through structured trial-and-error, we manually design challenging questions that frontier MLLMs fail to answer. On quantitative and human evaluations, WorldBench achieves higher visual diversity than any existing diverse benchmark. Evaluating 15 MLLMs on WorldBench reveals weaknesses in visual understanding: even the strongest model reaches only 64.0% accuracy, while some models perform marginally above chance-level. We hope our work highlights the importance of visual diversity in building multimodal benchmarks.
The Geometry of Alignment Collapse: When Fine-Tuning Breaks Safety
Feb 17, 2026Fine-tuning aligned language models on benign tasks unpredictably degrades safety guardrails, even when training data contains no harmful content and developers have no adversarial intent. We show that the prevailing explanation, that fine-tuning updates should be orthogonal to safety-critical directions in high-dimensional parameter space, offers false reassurance: we show this orthogonality is structurally unstable and collapses under the dynamics of gradient descent. We then resolve this through a novel geometric analysis, proving that alignment concentrates in low-dimensional subspaces with sharp curvature, creating a brittle structure that first-order methods cannot detect or defend. While initial fine-tuning updates may indeed avoid these subspaces, the curvature of the fine-tuning loss generates second-order acceleration that systematically steers trajectories into alignment-sensitive regions. We formalize this mechanism through the Alignment Instability Condition, three geometric properties that, when jointly satisfied, lead to safety degradation. Our main result establishes a quartic scaling law: alignment loss grows with the fourth power of training time, governed by the sharpness of alignment geometry and the strength of curvature coupling between the fine-tuning task and safety-critical parameters. These results expose a structural blind spot in the current safety paradigm. The dominant approaches to safe fine-tuning address only the initial snapshot of a fundamentally dynamic problem. Alignment fragility is not a bug to be patched; it is an intrinsic geometric property of gradient descent on curved manifolds. Our results motivate the development of curvature-aware methods, and we hope will further enable a shift in alignment safety analysis from reactive red-teaming to predictive diagnostics for open-weight model deployment.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?
Jun 13, 2025Recent reports claim that large language models (LLMs) now outperform elite humans in competitive programming. Drawing on knowledge from a group of medalists in international algorithmic contests, we revisit this claim, examining how LLMs differ from human experts and where limitations still remain. We introduce LiveCodeBench Pro, a benchmark composed of problems from Codeforces, ICPC, and IOI that are continuously updated to reduce the likelihood of data contamination. A team of Olympiad medalists annotates every problem for algorithmic categories and conducts a line-by-line analysis of failed model-generated submissions. Using this new data and benchmark, we find that frontier models still have significant limitations: without external tools, the best model achieves only 53% pass@1 on medium-difficulty problems and 0% on hard problems, domains where expert humans still excel. We also find that LLMs succeed at implementation-heavy problems but struggle with nuanced algorithmic reasoning and complex case analysis, often generating confidently incorrect justifications. High performance appears largely driven by implementation precision and tool augmentation, not superior reasoning. LiveCodeBench Pro thus highlights the significant gap to human grandmaster levels, while offering fine-grained diagnostics to steer future improvements in code-centric LLM reasoning.
Multi-Selection for Recommendation Systems
Apr 10, 2025We present the construction of a multi-selection model to answer differentially private queries in the context of recommendation systems. The server sends back multiple recommendations and a ``local model'' to the user, which the user can run locally on its device to select the item that best fits its private features. We study a setup where the server uses a deep neural network (trained on the Movielens 25M dataset as the ground truth for movie recommendation. In the multi-selection paradigm, the average recommendation utility is approximately 97\% of the optimal utility (as determined by the ground truth neural network) while maintaining a local differential privacy guarantee with $\epsilon$ ranging around 1 with respect to feature vectors of neighboring users. This is in comparison to an average recommendation utility of 91\% in the non-multi-selection regime under the same constraints.
Why am I Still Seeing This: Measuring the Effectiveness Of Ad Controls and Explanations in AI-Mediated Ad Targeting Systems
Aug 21, 2024Recently, Meta has shifted towards AI-mediated ad targeting mechanisms that do not require advertisers to provide detailed targeting criteria, likely driven by excitement over AI capabilities as well as new data privacy policies and targeting changes agreed upon in civil rights settlements. At the same time, Meta has touted their ad preference controls as an effective mechanism for users to control the ads they see. Furthermore, Meta markets their targeting explanations as a transparency tool that allows users to understand why they saw certain ads and inform actions to control future ads. Our study evaluates the effectiveness of Meta's "See less" ad control and the actionability of ad targeting explanations following the shift to AI-mediated targeting. We conduct a large-scale study, randomly assigning participants to mark "See less" to Body Weight Control or Parenting topics, and collecting the ads and targeting explanations Meta shows to participants before and after the intervention. We find that utilizing the "See less" ad control for the topics we study does not significantly reduce the number of ads shown by Meta on these topics, and that the control is less effective for some users whose demographics are correlated with the topic. Furthermore, we find that the majority of ad targeting explanations for local ads made no reference to location-specific targeting criteria, and did not inform users why ads related to the topics they marked to "See less" of continued to be delivered. We hypothesize that the poor effectiveness of controls and lack of actionability in explanations are the result of the shift to AI-mediated targeting, for which explainability and transparency tools have not yet been developed. Our work thus provides evidence for the need of new methods for transparency and user control, suitable and reflective of increasingly complex AI-mediated ad delivery systems.
Stability and Multigroup Fairness in Ranking with Uncertain Predictions
Feb 14, 2024

Rankings are ubiquitous across many applications, from search engines to hiring committees. In practice, many rankings are derived from the output of predictors. However, when predictors trained for classification tasks have intrinsic uncertainty, it is not obvious how this uncertainty should be represented in the derived rankings. Our work considers ranking functions: maps from individual predictions for a classification task to distributions over rankings. We focus on two aspects of ranking functions: stability to perturbations in predictions and fairness towards both individuals and subgroups. Not only is stability an important requirement for its own sake, but -- as we show -- it composes harmoniously with individual fairness in the sense of Dwork et al. (2012). While deterministic ranking functions cannot be stable aside from trivial scenarios, we show that the recently proposed uncertainty aware (UA) ranking functions of Singh et al. (2021) are stable. Our main result is that UA rankings also achieve multigroup fairness through successful composition with multiaccurate or multicalibrated predictors. Our work demonstrates that UA rankings naturally interpolate between group and individual level fairness guarantees, while simultaneously satisfying stability guarantees important whenever machine-learned predictions are used.
Fairness in Matching under Uncertainty
Feb 08, 2023
The prevalence and importance of algorithmic two-sided marketplaces has drawn attention to the issue of fairness in such settings. Algorithmic decisions are used in assigning students to schools, users to advertisers, and applicants to job interviews. These decisions should heed the preferences of individuals, and simultaneously be fair with respect to their merits (synonymous with fit, future performance, or need). Merits conditioned on observable features are always uncertain, a fact that is exacerbated by the widespread use of machine learning algorithms to infer merit from the observables. As our key contribution, we carefully axiomatize a notion of individual fairness in the two-sided marketplace setting which respects the uncertainty in the merits; indeed, it simultaneously recognizes uncertainty as the primary potential cause of unfairness and an approach to address it. We design a linear programming framework to find fair utility-maximizing distributions over allocations, and we show that the linear program is robust to perturbations in the estimated parameters of the uncertain merit distributions, a key property in combining the approach with machine learning techniques.
"You Can't Fix What You Can't Measure": Privately Measuring Demographic Performance Disparities in Federated Learning
Jun 24, 2022
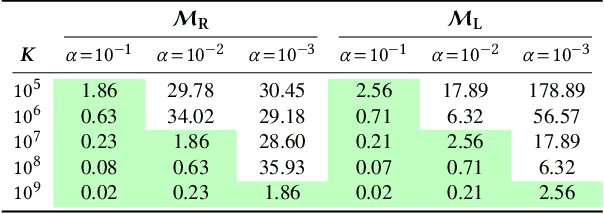
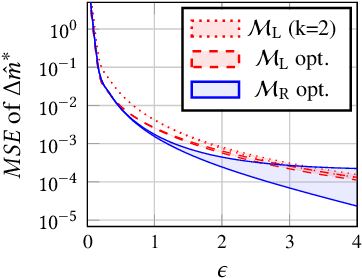

Federated learning allows many devices to collaborate in the training of machine learning models. As in traditional machine learning, there is a growing concern that models trained with federated learning may exhibit disparate performance for different demographic groups. Existing solutions to measure and ensure equal model performance across groups require access to information about group membership, but this access is not always available or desirable, especially under the privacy aspirations of federated learning. We study the feasibility of measuring such performance disparities while protecting the privacy of the user's group membership and the federated model's performance on the user's data. Protecting both is essential for privacy, because they may be correlated, and thus learning one may reveal the other. On the other hand, from the utility perspective, the privacy-preserved data should maintain the correlation to ensure the ability to perform accurate measurements of the performance disparity. We achieve both of these goals by developing locally differentially private mechanisms that preserve the correlations between group membership and model performance. To analyze the effectiveness of the mechanisms, we bound their error in estimating the disparity when optimized for a given privacy budget, and validate these bounds on synthetic data. Our results show that the error rapidly decreases for realistic numbers of participating clients, demonstrating that, contrary to what prior work suggested, protecting the privacy of protected attributes is not necessarily in conflict with identifying disparities in the performance of federated models.