 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Round Complexity of the Shuffle Model
Sep 28, 2020



The shuffle model of differential privacy was proposed as a viable model for performing distributed differentially private computations. Informally, the model consists of an untrusted analyzer that receives messages sent by participating parties via a shuffle functionality, the latter potentially disassociates messages from their senders. Prior work focused on one-round differentially private shuffle model protocols, demonstrating that functionalities such as addition and histograms can be performed in this model with accuracy levels similar to that of the curator model of differential privacy, where the computation is performed by a fully trusted party. Focusing on the round complexity of the shuffle model, we ask in this work what can be computed in the shuffle model of differential privacy with two rounds. Ishai et al. [FOCS 2006] showed how to use one round of the shuffle to establish secret keys between every two parties. Using this primitive to simulate a general secure multi-party protocol increases its round complexity by one. We show how two parties can use one round of the shuffle to send secret messages without having to first establish a secret key, hence retaining round complexity. Combining this primitive with the two-round semi-honest protocol of Applebaun et al. [TCC 2018], we obtain that every randomized functionality can be computed in the shuffle model with an honest majority, in merely two rounds. This includes any differentially private computation. We then move to examine differentially private computations in the shuffle model that (i) do not require the assumption of an honest majority, or (ii) do not admit one-round protocols, even with an honest majority. For that, we introduce two computational tasks: the common-element problem and the nested-common-element problem, for which we show separations between one-round and two-round protocols.
Closure Properties for Private Classification and Online Prediction
Mar 11, 2020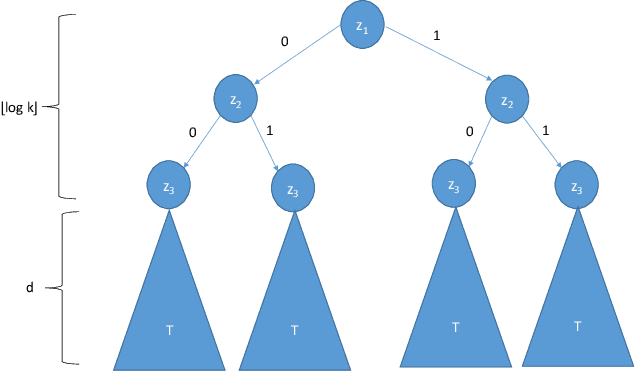
Let H be a class of boolean functions and consider acomposed class H' that is derived from H using some arbitrary aggregation rule (for example, H' may be the class of all 3-wise majority votes of functions in H). We upper bound the Littlestone dimension of H' in terms of that of H. The bounds are proved using combinatorial arguments that exploit a connection between the Littlestone dimension and Thresholds. As a corollary, we derive closure properties for online learning and private PAC learning. The derived bounds on the Littlestone dimension exhibit an undesirable super-exponential dependence. For private learning, we prove close to optimal bounds that circumvents this suboptimal dependency. The improved bounds on the sample complexity of private learning are derived algorithmically via transforming a private learner for the original class H to a private learner for the composed class H'. Using the same ideas we show that any (proper or improper) private algorithm that learns a class of functions H in the realizable case (i.e., when the examples are labeled by some function in the class) can be transformed to a private algorithm that learns the class H in the agnostic case.
The power of synergy in differential privacy: Combining a small curator with local randomizers
Dec 20, 2019
Motivated by the desire to bridge the utility gap between local and trusted curator models of differential privacy for practical applications, we initiate the theoretical study of a hybrid model introduced by "Blender" [Avent et al.,\ USENIX Security '17], in which differentially private protocols of n agents that work in the local-model are assisted by a differentially private curator that has access to the data of m additional users. We focus on the regime where m << n and study the new capabilities of this (m,n)-hybrid model. We show that, despite the fact that the hybrid model adds no significant new capabilities for the basic task of simple hypothesis-testing, there are many other tasks (under a wide range of parameters) that can be solved in the hybrid model yet cannot be solved either by the curator or by the local-users separately. Moreover, we exhibit additional tasks where at least one round of interaction between the curator and the local-users is necessary -- namely, no hybrid model protocol without such interaction can solve these tasks. Taken together, our results show that the combination of the local model with a small curator can become part of a promising toolkit for designing and implementing differential privacy.
Private Center Points and Learning of Halfspaces
Feb 27, 2019

We present a private learner for halfspaces over an arbitrary finite domain $X\subset \mathbb{R}^d$ with sample complexity $mathrm{poly}(d,2^{\log^*|X|})$. The building block for this learner is a differentially private algorithm for locating an approximate center point of $m>\mathrm{poly}(d,2^{\log^*|X|})$ points -- a high dimensional generalization of the median function. Our construction establishes a relationship between these two problems that is reminiscent of the relation between the median and learning one-dimensional thresholds [Bun et al.\ FOCS '15]. This relationship suggests that the problem of privately locating a center point may have further applications in the design of differentially private algorithms. We also provide a lower bound on the sample complexity for privately finding a point in the convex hull. For approximate differential privacy, we show a lower bound of $m=\Omega(d+\log^*|X|)$, whereas for pure differential privacy $m=\Omega(d\log|X|)$.
Privacy Preserving Multi-Agent Planning with Provable Guarantees
Nov 01, 2018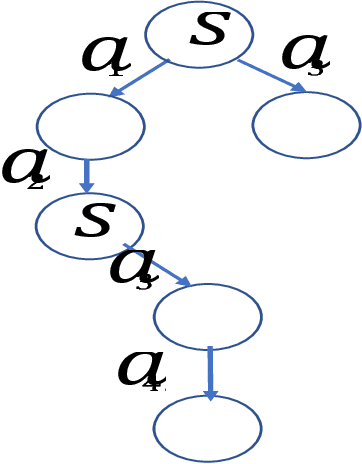
In privacy-preserving multi-agent planning, a group of agents attempt to cooperatively solve a multi-agent planning problem while maintaining private their data and actions. Although much work was carried out in this area in past years, its theoretical foundations have not been fully worked out. Specifically, although algorithms with precise privacy guarantees exist, even their most efficient implementations are not fast enough on realistic instances, whereas for practical algorithms no meaningful privacy guarantees exist. Secure-MAFS, a variant of the multi-agent forward search algorithm (MAFS) is the only practical algorithm to attempt to offer more precise guarantees, but only in very limited settings and with proof sketches only. In this paper we formulate a precise notion of secure computation for search-based algorithms and prove that Secure MAFS has this property in all domains.
Learning Privately with Labeled and Unlabeled Examples
Jul 01, 2015

A private learner is an algorithm that given a sample of labeled individual examples outputs a generalizing hypothesis while preserving the privacy of each individual. In 2008, Kasiviswanathan et al. (FOCS 2008) gave a generic construction of private learners, in which the sample complexity is (generally) higher than what is needed for non-private learners. This gap in the sample complexity was then further studied in several followup papers, showing that (at least in some cases) this gap is unavoidable. Moreover, those papers considered ways to overcome the gap, by relaxing either the privacy or the learning guarantees of the learner. We suggest an alternative approach, inspired by the (non-private) models of semi-supervised learning and active-learning, where the focus is on the sample complexity of labeled examples whereas unlabeled examples are of a significantly lower cost. We consider private semi-supervised learners that operate on a random sample, where only a (hopefully small) portion of this sample is labeled. The learners have no control over which of the sample elements are labeled. Our main result is that the labeled sample complexity of private learners is characterized by the VC dimension. We present two generic constructions of private semi-supervised learners. The first construction is of learners where the labeled sample complexity is proportional to the VC dimension of the concept class, however, the unlabeled sample complexity of the algorithm is as big as the representation length of domain elements. Our second construction presents a new technique for decreasing the labeled sample complexity of a given private learner, while roughly maintaining its unlabeled sample complexity. In addition, we show that in some settings the labeled sample complexity does not depend on the privacy parameters of the learner.
Private Learning and Sanitization: Pure vs. Approximate Differential Privacy
Jul 10, 2014
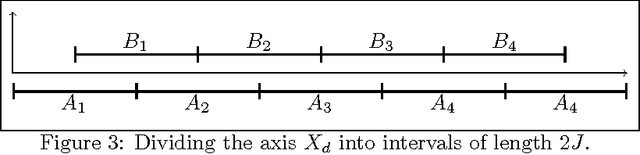
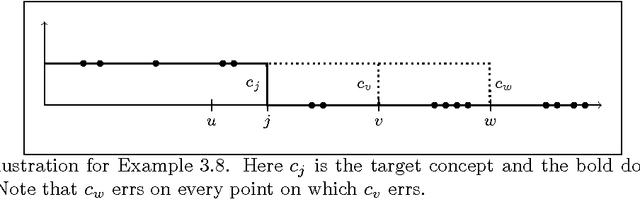
We compare the sample complexity of private learning [Kasiviswanathan et al. 2008] and sanitization~[Blum et al. 2008] under pure $\epsilon$-differential privacy [Dwork et al. TCC 2006] and approximate $(\epsilon,\delta)$-differential privacy [Dwork et al. Eurocrypt 2006]. We show that the sample complexity of these tasks under approximate differential privacy can be significantly lower than that under pure differential privacy. We define a family of optimization problems, which we call Quasi-Concave Promise Problems, that generalizes some of our considered tasks. We observe that a quasi-concave promise problem can be privately approximated using a solution to a smaller instance of a quasi-concave promise problem. This allows us to construct an efficient recursive algorithm solving such problems privately. Specifically, we construct private learners for point functions, threshold functions, and axis-aligned rectangles in high dimension. Similarly, we construct sanitizers for point functions and threshold functions. We also examine the sample complexity of label-private learners, a relaxation of private learning where the learner is required to only protect the privacy of the labels in the sample. We show that the VC dimension completely characterizes the sample complexity of such learners, that is, the sample complexity of learning with label privacy is equal (up to constants) to learning without privacy.
Characterizing the Sample Complexity of Private Learners
Feb 10, 2014In 2008, Kasiviswanathan et al. defined private learning as a combination of PAC learning and differential privacy. Informally, a private learner is applied to a collection of labeled individual information and outputs a hypothesis while preserving the privacy of each individual. Kasiviswanathan et al. gave a generic construction of private learners for (finite) concept classes, with sample complexity logarithmic in the size of the concept class. This sample complexity is higher than what is needed for non-private learners, hence leaving open the possibility that the sample complexity of private learning may be sometimes significantly higher than that of non-private learning. We give a combinatorial characterization of the sample size sufficient and necessary to privately learn a class of concepts. This characterization is analogous to the well known characterization of the sample complexity of non-private learning in terms of the VC dimension of the concept class. We introduce the notion of probabilistic representation of a concept class, and our new complexity measure RepDim corresponds to the size of the smallest probabilistic representation of the concept class. We show that any private learning algorithm for a concept class C with sample complexity m implies RepDim(C)=O(m), and that there exists a private learning algorithm with sample complexity m=O(RepDim(C)). We further demonstrate that a similar characterization holds for the database size needed for privately computing a large class of optimization problems and also for the well studied problem of private data release.