 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled MPPI-Based Multi-Arm Motion Planning
Feb 10, 2026Recent advances in sampling-based motion planning algorithms for high DOF arms leverage GPUs to provide SOTA performance. These algorithms can be used to control multiple arms jointly, but this approach scales poorly. To address this, we extend STORM, a sampling-based model-predictive-control (MPC) motion planning algorithm, to handle multiple robots in a distributed fashion. First, we modify STORM to handle dynamic obstacles. Then, we let each arm compute its own motion plan prefix, which it shares with the other arms, which treat it as a dynamic obstacle. Finally, we add a dynamic priority scheme. The new algorithm, MR-STORM, demonstrates clear empirical advantages over SOTA algorithms when operating with both static and dynamic obstacles.
Model-Based AI planning and Execution Systems for Robotics
May 07, 2025
Model-based planning and execution systems offer a principled approach to building flexible autonomous robots that can perform diverse tasks by automatically combining a host of basic skills. This idea is almost as old as modern robotics. Yet, while diverse general-purpose reasoning architectures have been proposed since, general-purpose systems that are integrated with modern robotic platforms have emerged only recently, starting with the influential ROSPlan system. Since then, a growing number of model-based systems for robot task-level control have emerged. In this paper, we consider the diverse design choices and issues existing systems attempt to address, the different solutions proposed so far, and suggest avenues for future development.
Bridging the Gap: Regularized Reinforcement Learning for Improved Classical Motion Planning with Safety Modules
Mar 27, 2024Classical navigation planners can provide safe navigation, albeit often suboptimally and with hindered human norm compliance. ML-based, contemporary autonomous navigation algorithms can imitate more natural and humancompliant navigation, but usually require large and realistic datasets and do not always provide safety guarantees. We present an approach that leverages a classical algorithm to guide reinforcement learning. This greatly improves the results and convergence rate of the underlying RL algorithm and requires no human-expert demonstrations to jump-start the process. Additionally, we incorporate a practical fallback system that can switch back to a classical planner to ensure safety. The outcome is a sample efficient ML approach for mobile navigation that builds on classical algorithms, improves them to ensure human compliance, and guarantees safety.
Towards Plug'n Play Task-Level Autonomy for Robotics Using POMDPs and Generative Models
Jul 20, 2022
To enable robots to achieve high level objectives, engineers typically write scripts that apply existing specialized skills, such as navigation, object detection and manipulation to achieve these goals. Writing good scripts is challenging since they must intelligently balance the inherent stochasticity of a physical robot's actions and sensors, and the limited information it has. In principle, AI planning can be used to address this challenge and generate good behavior policies automatically. But this requires passing three hurdles. First, the AI must understand each skill's impact on the world. Second, we must bridge the gap between the more abstract level at which we understand what a skill does and the low-level state variables used within its code. Third, much integration effort is required to tie together all components. We describe an approach for integrating robot skills into a working autonomous robot controller that schedules its skills to achieve a specified task and carries four key advantages. 1) Our Generative Skill Documentation Language (GSDL) makes code documentation simpler, compact, and more expressive using ideas from probabilistic programming languages. 2) An expressive abstraction mapping (AM) bridges the gap between low-level robot code and the abstract AI planning model. 3) Any properly documented skill can be used by the controller without any additional programming effort, providing a Plug'n Play experience. 4) A POMDP solver schedules skill execution while properly balancing partial observability, stochastic behavior, and noisy sensing.
* In Proceedings AREA 2022, arXiv:2207.09058
Learning and Solving Regular Decision Processes
Mar 02, 2020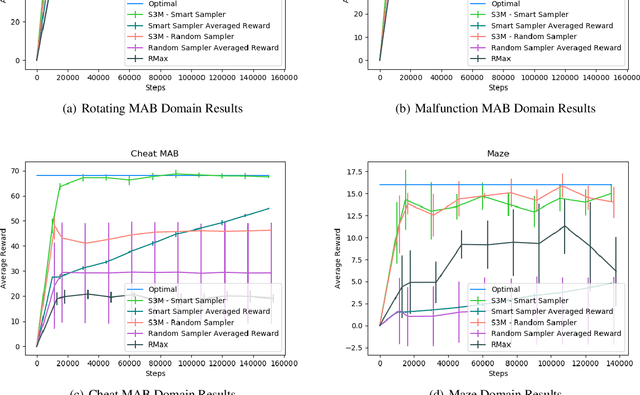
Regular Decision Processes (RDPs) are a recently introduced model that extends MDPs with non-Markovian dynamics and rewards. The non-Markovian behavior is restricted to depend on regular properties of the history. These can be specified using regular expressions or formulas in linear dynamic logic over finite traces. Fully specified RDPs can be solved by compiling them into an appropriate MDP. Learning RDPs from data is a challenging problem that has yet to be addressed, on which we focus in this paper. Our approach rests on a new representation for RDPs using Mealy Machines that emit a distribution and an expected reward for each state-action pair. Building on this representation, we combine automata learning techniques with history clustering to learn such a Mealy machine and solve it by adapting MCTS to it. We empirically evaluate this approach, demonstrating its feasibility.
Reinforcement Learning with Non-Markovian Rewards
Dec 05, 2019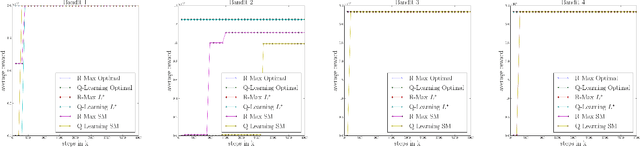
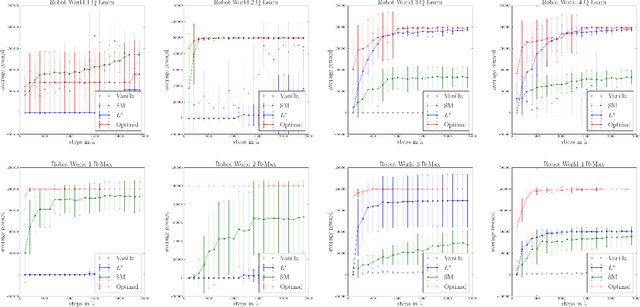
The standard RL world model is that of a Markov Decision Process (MDP). A basic premise of MDPs is that the rewards depend on the last state and action only. Yet, many real-world rewards are non-Markovian. For example, a reward for bringing coffee only if requested earlier and not yet served, is non-Markovian if the state only records current requests and deliveries. Past work considered the problem of modeling and solving MDPs with non-Markovian rewards (NMR), but we know of no principled approaches for RL with NMR. Here, we address the problem of policy learning from experience with such rewards. We describe and evaluate empirically four combinations of the classical RL algorithm Q-learning and R-max with automata learning algorithms to obtain new RL algorithms for domains with NMR. We also prove that some of these variants converge to an optimal policy in the limit.
Privacy Preserving Multi-Agent Planning with Provable Guarantees
Nov 01, 2018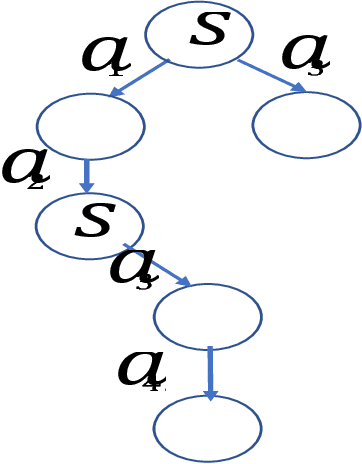
In privacy-preserving multi-agent planning, a group of agents attempt to cooperatively solve a multi-agent planning problem while maintaining private their data and actions. Although much work was carried out in this area in past years, its theoretical foundations have not been fully worked out. Specifically, although algorithms with precise privacy guarantees exist, even their most efficient implementations are not fast enough on realistic instances, whereas for practical algorithms no meaningful privacy guarantees exist. Secure-MAFS, a variant of the multi-agent forward search algorithm (MAFS) is the only practical algorithm to attempt to offer more precise guarantees, but only in very limited settings and with proof sketches only. In this paper we formulate a precise notion of secure computation for search-based algorithms and prove that Secure MAFS has this property in all domains.
A Planning Approach to Monitoring Behavior of Computer Programs
Sep 11, 2017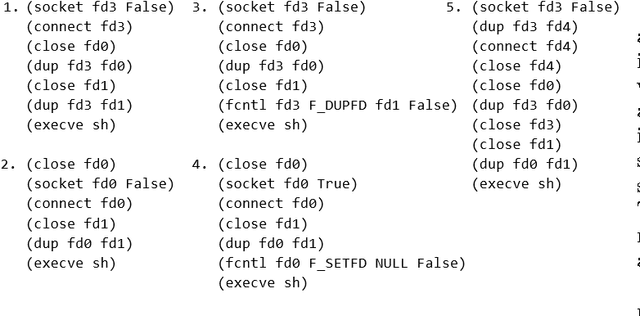

We describe a novel approach to monitoring high level behaviors using concepts from AI planning. Our goal is to understand what a program is doing based on its system call trace. This ability is particularly important for detecting malware. We approach this problem by building an abstract model of the operating system using the STRIPS planning language, casting system calls as planning operators. Given a system call trace, we simulate the corresponding operators on our model and by observing the properties of the state reached, we learn about the nature of the original program and its behavior. Thus, unlike most statistical detection methods that focus on syntactic features, our approach is semantic in nature. Therefore, it is more robust against obfuscation techniques used by malware that change the outward appearance of the trace but not its effect. We demonstrate the efficacy of our approach by evaluating it on actual system call traces.
An MDP-based Recommender System
May 16, 2015
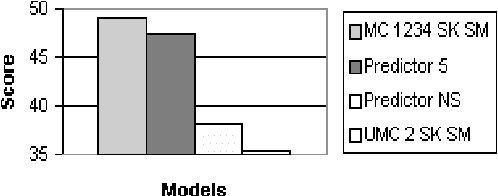

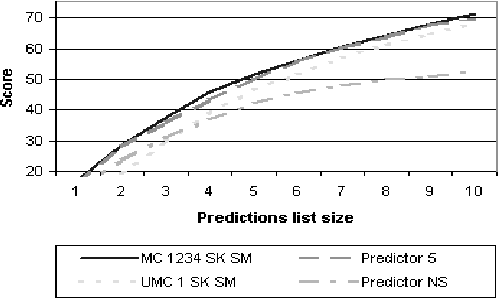
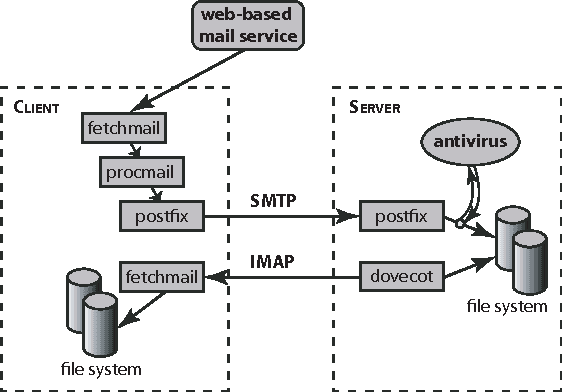
Typical Recommender systems adopt a static view of the recommendation process and treat it as a prediction problem. We argue that it is more appropriate to view the problem of generating recommendations as a sequential decision problem and, consequently, that Markov decision processes (MDP) provide a more appropriate model for Recommender systems. MDPs introduce two benefits: they take into account the long-term effects of each recommendation, and they take into account the expected value of each recommendation. To succeed in practice, an MDP-based Recommender system must employ a strong initial model; and the bulk of this paper is concerned with the generation of such a model. In particular, we suggest the use of an n-gram predictive model for generating the initial MDP. Our n-gram model induces a Markov-chain model of user behavior whose predictive accuracy is greater than that of existing predictive models. We describe our predictive model in detail and evaluate its performance on real data. In addition, we show how the model can be used in an MDP-based Recommender system.
Replanning in Domains with Partial Information and Sensing Actions
Jan 23, 2014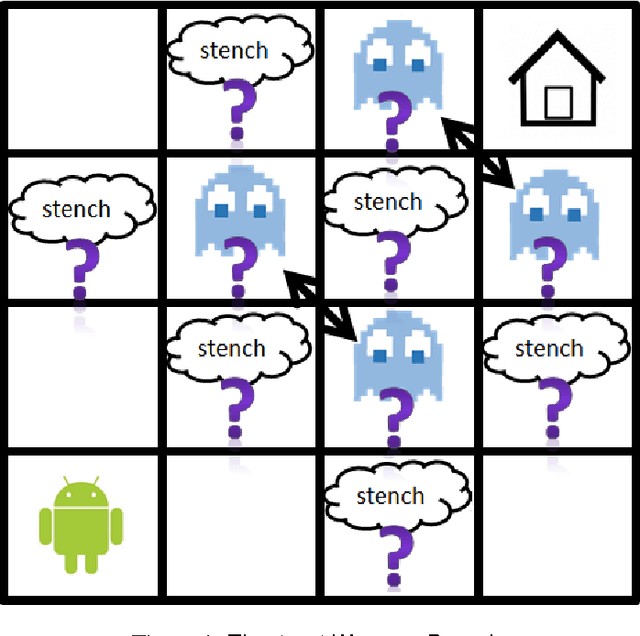


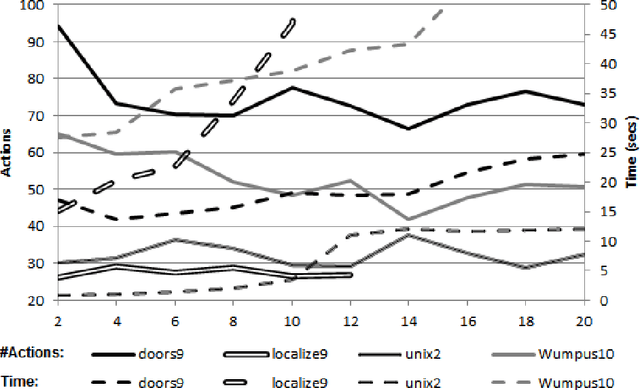
Replanning via determinization is a recent, popular approach for online planning in MDPs. In this paper we adapt this idea to classical, non-stochastic domains with partial information and sensing actions, presenting a new planner: SDR (Sample, Determinize, Replan). At each step we generate a solution plan to a classical planning problem induced by the original problem. We execute this plan as long as it is safe to do so. When this is no longer the case, we replan. The classical planning problem we generate is based on the translation-based approach for conformant planning introduced by Palacios and Geffner. The state of the classical planning problem generated in this approach captures the belief state of the agent in the original problem. Unfortunately, when this method is applied to planning problems with sensing, it yields a non-deterministic planning problem that is typically very large. Our main contribution is the introduction of state sampling techniques for overcoming these two problems. In addition, we introduce a novel, lazy, regression-based method for querying the agents belief state during run-time. We provide a comprehensive experimental evaluation of the planner, showing that it scales better than the state-of-the-art CLG planner on existing benchmark problems, but also highlighting its weaknesses with new domains. We also discuss its theoretical guarantees.