 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Non-Markovian Rewards
Dec 05, 2019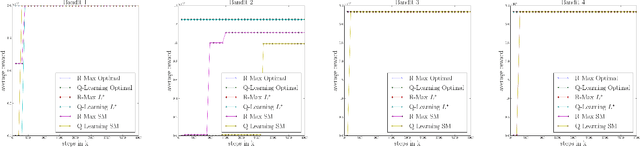
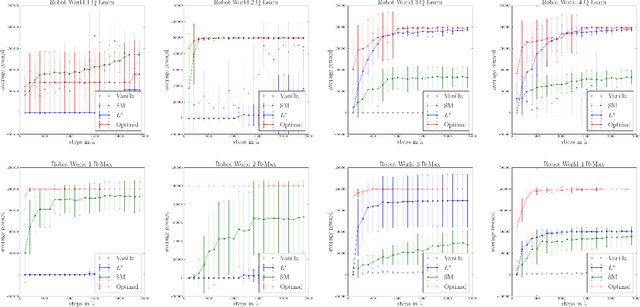
The standard RL world model is that of a Markov Decision Process (MDP). A basic premise of MDPs is that the rewards depend on the last state and action only. Yet, many real-world rewards are non-Markovian. For example, a reward for bringing coffee only if requested earlier and not yet served, is non-Markovian if the state only records current requests and deliveries. Past work considered the problem of modeling and solving MDPs with non-Markovian rewards (NMR), but we know of no principled approaches for RL with NMR. Here, we address the problem of policy learning from experience with such rewards. We describe and evaluate empirically four combinations of the classical RL algorithm Q-learning and R-max with automata learning algorithms to obtain new RL algorithms for domains with NMR. We also prove that some of these variants converge to an optimal policy in the limit.