 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Speedup Learning for Optimal Planning
Jan 23, 2014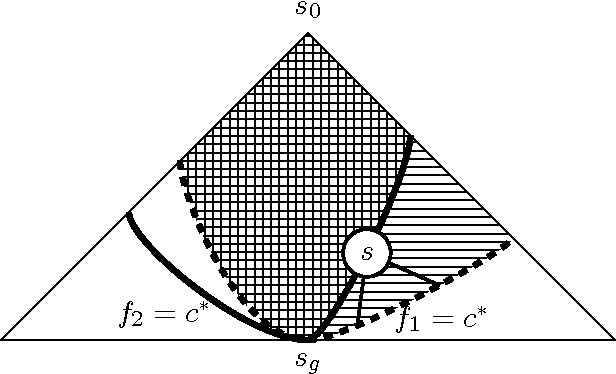
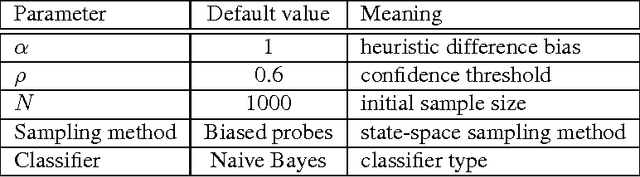
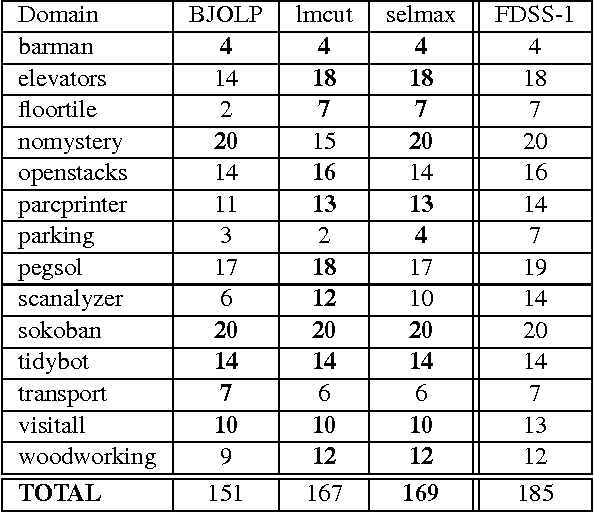
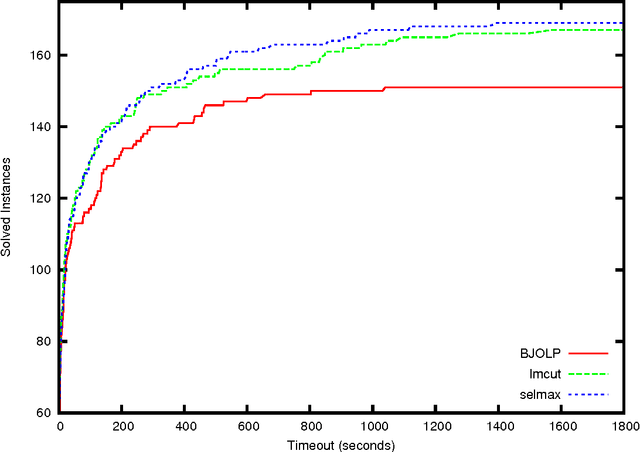
Domain-independent planning is one of the foundational areas in the field of Artificial Intelligence. A description of a planning task consists of an initial world state, a goal, and a set of actions for modifying the world state. The objective is to find a sequence of actions, that is, a plan, that transforms the initial world state into a goal state. In optimal planning, we are interested in finding not just a plan, but one of the cheapest plans. A prominent approach to optimal planning these days is heuristic state-space search, guided by admissible heuristic functions. Numerous admissible heuristics have been developed, each with its own strengths and weaknesses, and it is well known that there is no single "best heuristic for optimal planning in general. Thus, which heuristic to choose for a given planning task is a difficult question. This difficulty can be avoided by combining several heuristics, but that requires computing numerous heuristic estimates at each state, and the tradeoff between the time spent doing so and the time saved by the combined advantages of the different heuristics might be high. We present a novel method that reduces the cost of combining admissible heuristics for optimal planning, while maintaining its benefits. Using an idealized search space model, we formulate a decision rule for choosing the best heuristic to compute at each state. We then present an active online learning approach for learning a classifier with that decision rule as the target concept, and employ the learned classifier to decide which heuristic to compute at each state. We evaluate this technique empirically, and show that it substantially outperforms the standard method for combining several heuristics via their pointwise maximum.
Implicit Abstraction Heuristics
Jan 16, 2014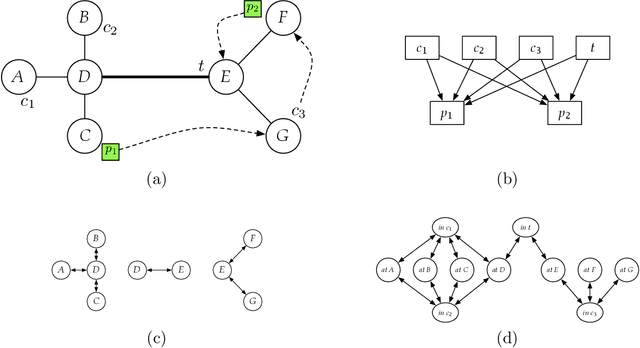
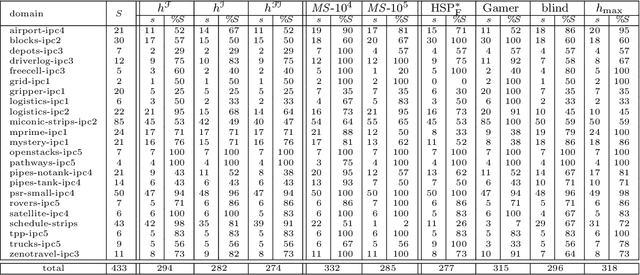
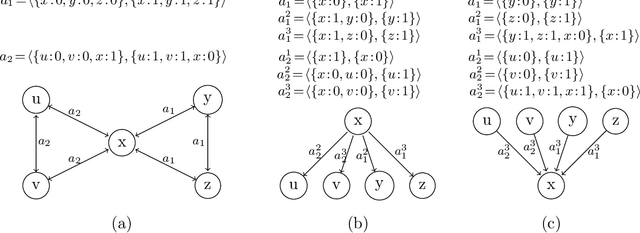
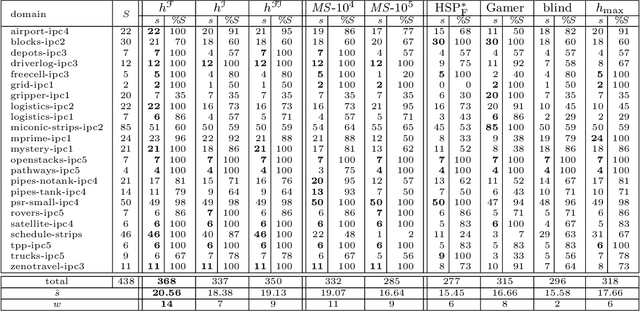
State-space search with explicit abstraction heuristics is at the state of the art of cost-optimal planning. These heuristics are inherently limited, nonetheless, because the size of the abstract space must be bounded by some, even if a very large, constant. Targeting this shortcoming, we introduce the notion of (additive) implicit abstractions, in which the planning task is abstracted by instances of tractable fragments of optimal planning. We then introduce a concrete setting of this framework, called fork-decomposition, that is based on two novel fragments of tractable cost-optimal planning. The induced admissible heuristics are then studied formally and empirically. This study testifies for the accuracy of the fork decomposition heuristics, yet our empirical evaluation also stresses the tradeoff between their accuracy and the runtime complexity of computing them. Indeed, some of the power of the explicit abstraction heuristics comes from precomputing the heuristic function offline and then determining h(s) for each evaluated state s by a very fast lookup in a database. By contrast, while fork-decomposition heuristics can be calculated in polynomial time, computing them is far from being fast. To address this problem, we show that the time-per-node complexity bottleneck of the fork-decomposition heuristics can be successfully overcome. We demonstrate that an equivalent of the explicit abstraction notion of a database exists for the fork-decomposition abstractions as well, despite their exponential-size abstract spaces. We then verify empirically that heuristic search with the databased" fork-decomposition heuristics favorably competes with the state of the art of cost-optimal planning.
Generic Preferences over Subsets of Structured Objects
Jan 15, 2014
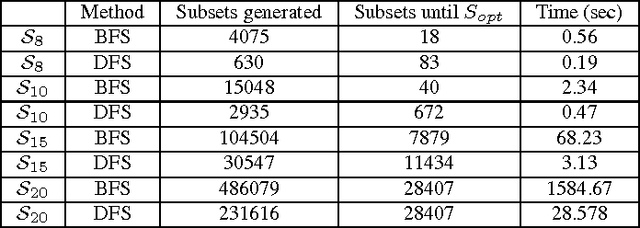
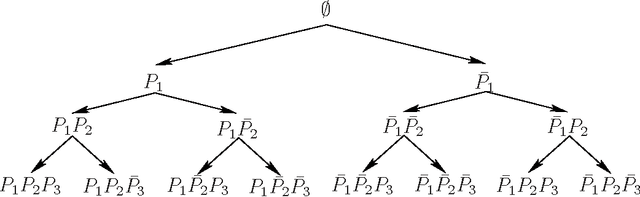
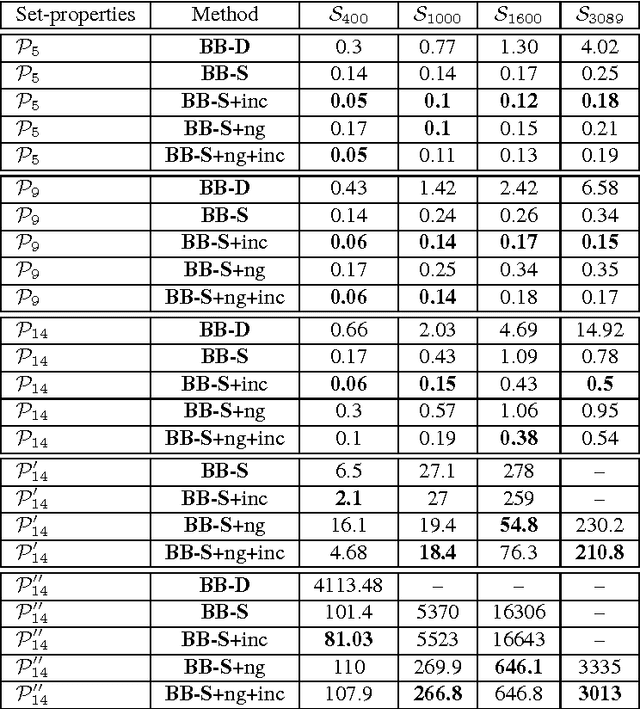
Various tasks in decision making and decision support systems require selecting a preferred subset of a given set of items. Here we focus on problems where the individual items are described using a set of characterizing attributes, and a generic preference specification is required, that is, a specification that can work with an arbitrary set of items. For example, preferences over the content of an online newspaper should have this form: At each viewing, the newspaper contains a subset of the set of articles currently available. Our preference specification over this subset should be provided offline, but we should be able to use it to select a subset of any currently available set of articles, e.g., based on their tags. We present a general approach for lifting formalisms for specifying preferences over objects with multiple attributes into ones that specify preferences over subsets of such objects. We also show how we can compute an optimal subset given such a specification in a relatively efficient manner. We provide an empirical evaluation of the approach as well as some worst-case complexity results.
Monte-Carlo Planning: Theoretically Fast Convergence Meets Practical Efficiency
Sep 26, 2013
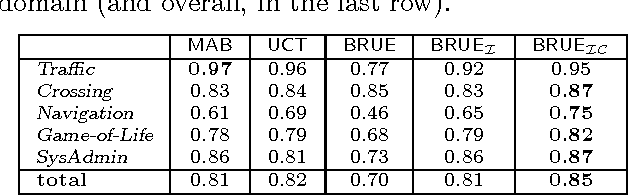

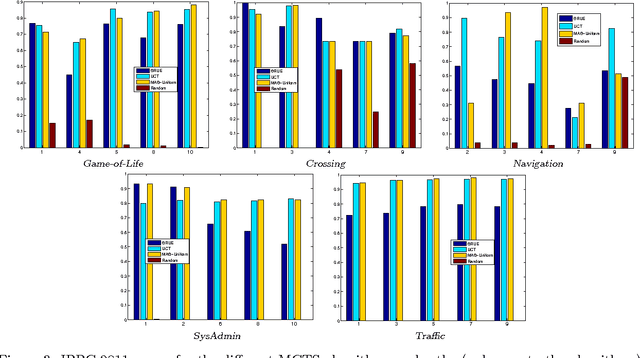
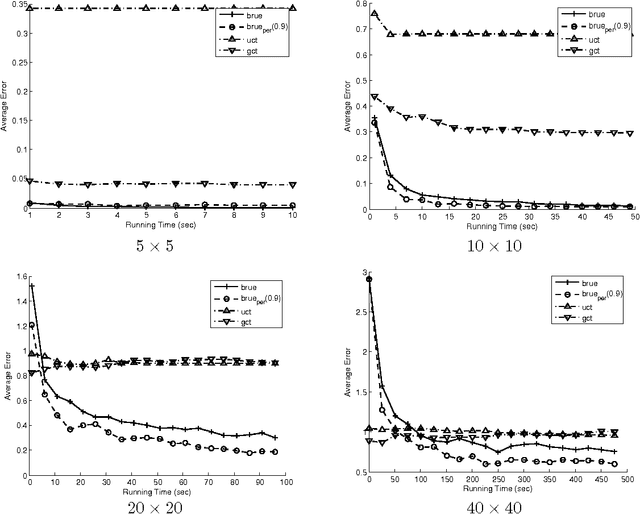
Popular Monte-Carlo tree search (MCTS) algorithms for online planning, such as epsilon-greedy tree search and UCT, aim at rapidly identifying a reasonably good action, but provide rather poor worst-case guarantees on performance improvement over time. In contrast, a recently introduced MCTS algorithm BRUE guarantees exponential-rate improvement over time, yet it is not geared towards identifying reasonably good choices right at the go. We take a stand on the individual strengths of these two classes of algorithms, and show how they can be effectively connected. We then rationalize a principle of "selective tree expansion", and suggest a concrete implementation of this principle within MCTS. The resulting algorithm,s favorably compete with other MCTS algorithms under short planning times, while preserving the attractive convergence properties of BRUE.
Cost-Sharing in Bayesian Knowledge Bases
Feb 06, 2013


Bayesian knowledge bases (BKBs) are a generalization of Bayes networks and weighted proof graphs (WAODAGs), that allow cycles in the causal graph. Reasoning in BKBs requires finding the most probable inferences consistent with the evidence. The cost-sharing heuristic for finding least-cost explanations in WAODAGs was presented and shown to be effective by Charniak and Husain. However, the cycles in BKBs would make the definition of cost-sharing cyclic as well, if applied directly to BKBs. By treating the defining equations of cost-sharing as a system of equations, one can properly define an admissible cost-sharing heuristic for BKBs. Empirical evaluation shows that cost-sharing improves performance significantly when applied to BKBs.
Simple Regret Optimization in Online Planning for Markov Decision Processes
Dec 19, 2012
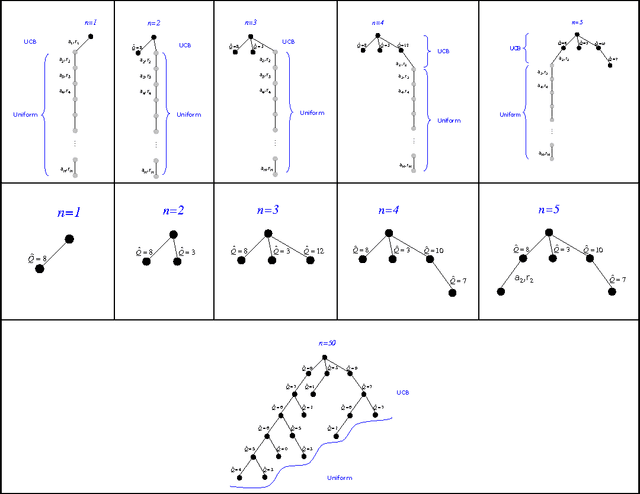
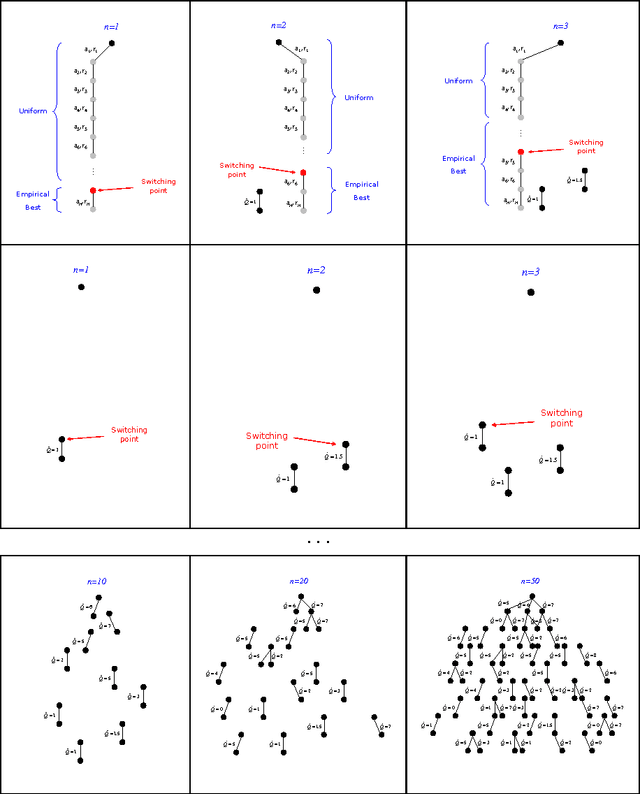
We consider online planning in Markov decision processes (MDPs). In online planning, the agent focuses on its current state only, deliberates about the set of possible policies from that state onwards and, when interrupted, uses the outcome of that exploratory deliberation to choose what action to perform next. The performance of algorithms for online planning is assessed in terms of simple regret, which is the agent's expected performance loss when the chosen action, rather than an optimal one, is followed. To date, state-of-the-art algorithms for online planning in general MDPs are either best effort, or guarantee only polynomial-rate reduction of simple regret over time. Here we introduce a new Monte-Carlo tree search algorithm, BRUE, that guarantees exponential-rate reduction of simple regret and error probability. This algorithm is based on a simple yet non-standard state-space sampling scheme, MCTS2e, in which different parts of each sample are dedicated to different exploratory objectives. Our empirical evaluation shows that BRUE not only provides superior performance guarantees, but is also very effective in practice and favorably compares to state-of-the-art. We then extend BRUE with a variant of "learning by forgetting." The resulting set of algorithms, BRUE(alpha), generalizes BRUE, improves the exponential factor in the upper bound on its reduction rate, and exhibits even more attractive empirical performance.
Introducing Variable Importance Tradeoffs into CP-Nets
Dec 12, 2012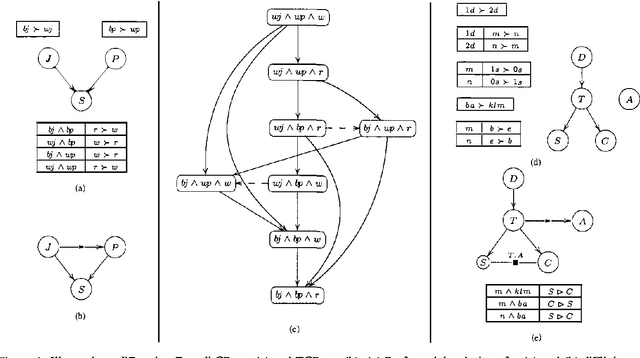

The ability to make decisions and to assess potential courses of action is a corner-stone of many AI applications, and usually this requires explicit information about the decision-maker s preferences. IN many applications, preference elicitation IS a serious bottleneck.The USER either does NOT have the time, the knowledge, OR the expert support required TO specify complex multi - attribute utility functions. IN such cases, a method that IS based ON intuitive, yet expressive, preference statements IS required. IN this paper we suggest the USE OF TCP - nets, an enhancement OF CP - nets, AS a tool FOR representing, AND reasoning about qualitative preference statements.We present AND motivate this framework, define its semantics, AND show how it can be used TO perform constrained optimization.
Compact Value-Function Representations for Qualitative Preferences
Jul 11, 2012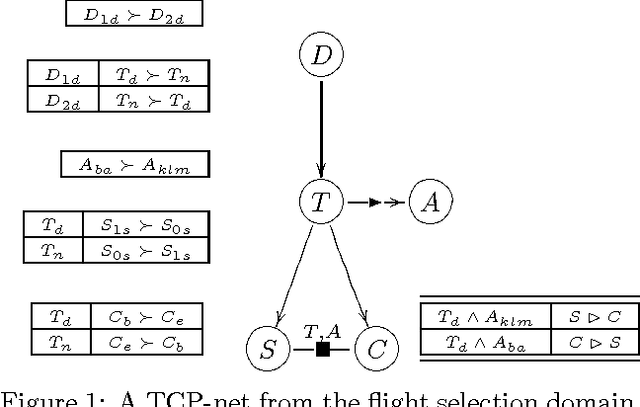
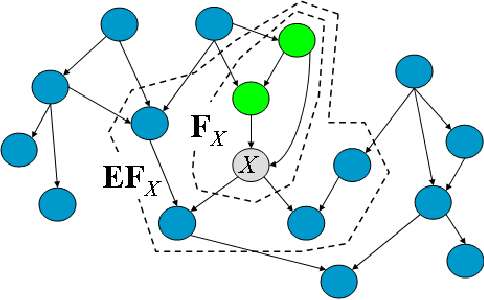
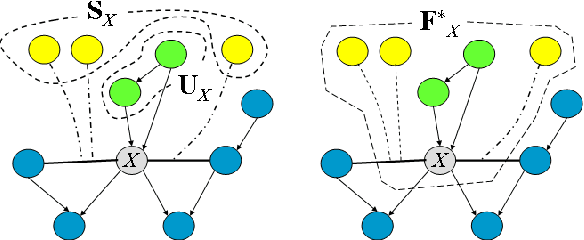
We consider the challenge of preference elicitation in systems that help users discover the most desirable item(s) within a given database. Past work on preference elicitation focused on structured models that provide a factored representation of users' preferences. Such models require less information to construct and support efficient reasoning algorithms. This paper makes two substantial contributions to this area: (1) Strong representation theorems for factored value functions. (2) A methodology that utilizes our representation results to address the problem of optimal item selection.
Unstructuring User Preferences: Efficient Non-Parametric Utility Revelation
Jul 04, 2012Tackling the problem of ordinal preference revelation and reasoning, we propose a novel methodology for generating an ordinal utility function from a set of qualitative preference statements. To the best of our knowledge, our proposal constitutes the first nonparametric solution for this problem that is both efficient and semantically sound. Our initial experiments provide strong evidence for practical effectiveness of our approach.
Reasoning about soft constraints and conditional preferences: complexity results and approximation techniques
May 22, 2009
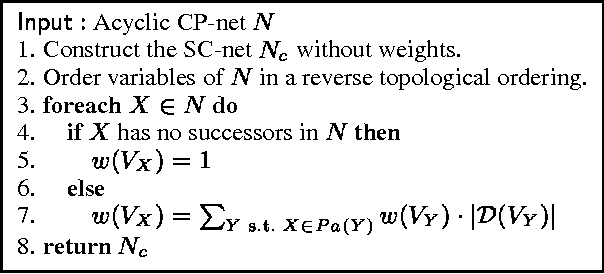
Many real life optimization problems contain both hard and soft constraints, as well as qualitative conditional preferences. However, there is no single formalism to specify all three kinds of information. We therefore propose a framework, based on both CP-nets and soft constraints, that handles both hard and soft constraints as well as conditional preferences efficiently and uniformly. We study the complexity of testing the consistency of preference statements, and show how soft constraints can faithfully approximate the semantics of conditional preference statements whilst improving the computational complexity
* Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence (IJCAI-03)