 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Planning with Explicit Latent Transitions
Feb 04, 2026Planning with LLMs is bottlenecked by token-by-token generation and repeated full forward passes, making multi-step lookahead and rollout-based search expensive in latency and compute. We propose EmbedPlan, which replaces autoregressive next-state generation with a lightweight transition model operating in a frozen language embedding space. EmbedPlan encodes natural language state and action descriptions into vectors, predicts the next-state embedding, and retrieves the next state by nearest-neighbor similarity, enabling fast planning computation without fine-tuning the encoder. We evaluate next-state prediction across nine classical planning domains using six evaluation protocols of increasing difficulty: interpolation, plan-variant, extrapolation, multi-domain, cross-domain, and leave-one-out. Results show near-perfect interpolation performance but a sharp degradation when generalization requires transfer to unseen problems or unseen domains; plan-variant evaluation indicates generalization to alternative plans rather than memorizing seen trajectories. Overall, frozen embeddings support within-domain dynamics learning after observing a domain's transitions, while transfer across domain boundaries remains a bottleneck.
Less is More: Learning Graph Tasks with Just LLMs
Aug 13, 2025For large language models (LLMs), reasoning over graphs could help solve many problems. Prior work has tried to improve LLM graph reasoning by examining how best to serialize graphs as text and by combining GNNs and LLMs. However, the merits of such approaches remain unclear, so we empirically answer the following research questions: (1) Can LLMs learn to solve fundamental graph tasks without specialized graph encoding models?, (2) Can LLMs generalize learned solutions to unseen graph structures or tasks?, and (3) What are the merits of competing approaches to learn graph tasks? We show that even small LLMs can learn to solve graph tasks by training them with instructive chain-of-thought solutions, and this training generalizes, without specialized graph encoders, to new tasks and graph structures.
Make Planning Research Rigorous Again!
May 27, 2025In over sixty years since its inception, the field of planning has made significant contributions to both the theory and practice of building planning software that can solve a never-before-seen planning problem. This was done through established practices of rigorous design and evaluation of planning systems. It is our position that this rigor should be applied to the current trend of work on planning with large language models. One way to do so is by correctly incorporating the insights, tools, and data from the automated planning community into the design and evaluation of LLM-based planners. The experience and expertise of the planning community are not just important from a historical perspective; the lessons learned could play a crucial role in accelerating the development of LLM-based planners. This position is particularly important in light of the abundance of recent works that replicate and propagate the same pitfalls that the planning community has encountered and learned from. We believe that avoiding such known pitfalls will contribute greatly to the progress in building LLM-based planners and to planning in general.
ACPBench Hard: Unrestrained Reasoning about Action, Change, and Planning
Mar 31, 2025The ACPBench dataset provides atomic reasoning tasks required for efficient planning. The dataset is aimed at distilling the complex plan generation task into separate atomic reasoning tasks in their easiest possible form, boolean or multiple-choice questions, where the model has to choose the right answer from the provided options. While the aim of ACPBench is to test the simplest form of reasoning about action and change, when tasked with planning, a model does not typically have options to choose from and thus the reasoning required for planning dictates an open-ended, generative form for these tasks. To that end, we introduce ACPBench Hard, a generative version of ACPBench, with open-ended questions which the model needs to answer. Models that perform well on these tasks could in principle be integrated into a planner or be used directly as a policy. We discuss the complexity of these tasks as well as the complexity of validating the correctness of their answers and present validation algorithms for each task. Equipped with these validators, we test the performance of a variety of models on our tasks and find that for most of these tasks the performance of even the largest models is still subpar. Our experiments show that no model outperforms another in these tasks and with a few exceptions all tested language models score below 65%, indicating that even the current frontier language models have a long way to go before they can reliably reason about planning. In fact, even the so-called reasoning models struggle with solving these reasoning tasks. ACPBench Hard collection is available at the following link: https://ibm.github.io/ACPBench
AI Planning: A Primer and Survey (Preliminary Report)
Dec 07, 2024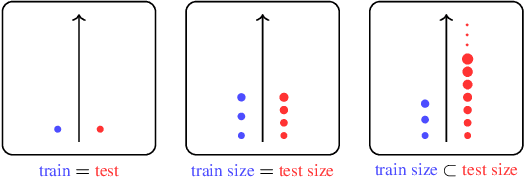
Automated decision-making is a fundamental topic that spans multiple sub-disciplines in AI: reinforcement learning (RL), AI planning (AP), foundation models, and operations research, among others. Despite recent efforts to ``bridge the gaps'' between these communities, there remain many insights that have not yet transcended the boundaries. Our goal in this paper is to provide a brief and non-exhaustive primer on ideas well-known in AP, but less so in other sub-disciplines. We do so by introducing the classical AP problem and representation, and extensions that handle uncertainty and time through the Markov Decision Process formalism. Next, we survey state-of-the-art techniques and ideas for solving AP problems, focusing on their ability to exploit problem structure. Lastly, we cover subfields within AP for learning structure from unstructured inputs and learning to generalise to unseen scenarios and situations.
ACPBench: Reasoning about Action, Change, and Planning
Oct 08, 2024There is an increasing body of work using Large Language Models (LLMs) as agents for orchestrating workflows and making decisions in domains that require planning and multi-step reasoning. As a result, it is imperative to evaluate LLMs on core skills required for planning. In this work, we present ACPBench, a benchmark for evaluating the reasoning tasks in the field of planning. The benchmark consists of 7 reasoning tasks over 13 planning domains. The collection is constructed from planning domains described in a formal language. This allows us to synthesize problems with provably correct solutions across many tasks and domains. Further, it allows us the luxury of scale without additional human effort, i.e., many additional problems can be created automatically. Our extensive evaluation of 22 open-sourced and frontier LLMs highlight the significant gap in the reasoning capability of the LLMs. The average accuracy of one of the best-performing frontier LLMs -- GPT-4o on these tasks can fall as low as 52.50% ACPBench collection is available at https://ibm.github.io/ACPBench.
Automating Thought of Search: A Journey Towards Soundness and Completeness
Aug 21, 2024



Planning remains one of the last standing bastions for large language models (LLMs), which now turn their attention to search. Most of the literature uses the language models as world models to define the search space, forgoing soundness for the sake of flexibility. A recent work, Thought of Search (ToS), proposed defining the search space with code, having the language models produce that code. ToS requires a human in the loop, collaboratively producing a sound successor function and goal test. The result, however, is worth the effort: all the tested datasets were solved with 100% accuracy. At the same time LLMs have demonstrated significant progress in code generation and refinement for complex reasoning tasks. In this work, we automate ToS (AutoToS), completely taking the human out of the loop of solving planning problems. AutoToS guides the language model step by step towards the generation of sound and complete search components, through feedback from both generic and domain specific unit tests. We achieve 100% accuracy, with minimal feedback iterations, using LLMs of various sizes on all evaluated domains.
Planning with Language Models Through The Lens of Efficiency
Apr 18, 2024We analyse the cost of using LLMs for planning and highlight that recent trends are profoundly uneconomical. We propose a significantly more efficient approach and argue for a responsible use of compute resources; urging research community to investigate LLM-based approaches that upholds efficiency.
Some Orders Are Important: Partially Preserving Orders in Top-Quality Planning
Apr 01, 2024


The ability to generate multiple plans is central to using planning in real-life applications. Top-quality planners generate sets of such top-cost plans, allowing flexibility in determining equivalent ones. In terms of the order between actions in a plan, the literature only considers two extremes -- either all orders are important, making each plan unique, or all orders are unimportant, treating two plans differing only in the order of actions as equivalent. To allow flexibility in selecting important orders, we propose specifying a subset of actions the orders between which are important, interpolating between the top-quality and unordered top-quality planning problems. We explore the ways of adapting partial order reduction search pruning techniques to address this new computational problem and present experimental evaluations demonstrating the benefits of exploiting such techniques in this setting.
Unifying and Certifying Top-Quality Planning
Mar 05, 2024
The growing utilization of planning tools in practical scenarios has sparked an interest in generating multiple high-quality plans. Consequently, a range of computational problems under the general umbrella of top-quality planning were introduced over a short time period, each with its own definition. In this work, we show that the existing definitions can be unified into one, based on a dominance relation. The different computational problems, therefore, simply correspond to different dominance relations. Given the unified definition, we can now certify the top-quality of the solutions, leveraging existing certification of unsolvability and optimality. We show that task transformations found in the existing literature can be employed for the efficient certification of various top-quality planning problems and propose a novel transformation to efficiently certify loopless top-quality planning.