 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Domain Experts in Creating Effective Tutoring Systems
Oct 01, 2025The role that highly curated knowledge, provided by domain experts, could play in creating effective tutoring systems is often overlooked within the AI for education community. In this paper, we highlight this topic by discussing two ways such highly curated expert knowledge could help in creating novel educational systems. First, we will look at how one could use explainable AI (XAI) techniques to automatically create lessons. Most existing XAI methods are primarily aimed at debugging AI systems. However, we will discuss how one could use expert specified rules about solving specific problems along with novel XAI techniques to automatically generate lessons that could be provided to learners. Secondly, we will see how an expert specified curriculum for learning a target concept can help develop adaptive tutoring systems, that can not only provide a better learning experience, but could also allow us to use more efficient algorithms to create these systems. Finally, we will highlight the importance of such methods using a case study of creating a tutoring system for pollinator identification, where such knowledge could easily be elicited from experts.
Make Planning Research Rigorous Again!
May 27, 2025In over sixty years since its inception, the field of planning has made significant contributions to both the theory and practice of building planning software that can solve a never-before-seen planning problem. This was done through established practices of rigorous design and evaluation of planning systems. It is our position that this rigor should be applied to the current trend of work on planning with large language models. One way to do so is by correctly incorporating the insights, tools, and data from the automated planning community into the design and evaluation of LLM-based planners. The experience and expertise of the planning community are not just important from a historical perspective; the lessons learned could play a crucial role in accelerating the development of LLM-based planners. This position is particularly important in light of the abundance of recent works that replicate and propagate the same pitfalls that the planning community has encountered and learned from. We believe that avoiding such known pitfalls will contribute greatly to the progress in building LLM-based planners and to planning in general.
Inferring Implicit Goals Across Differing Task Models
Jan 29, 2025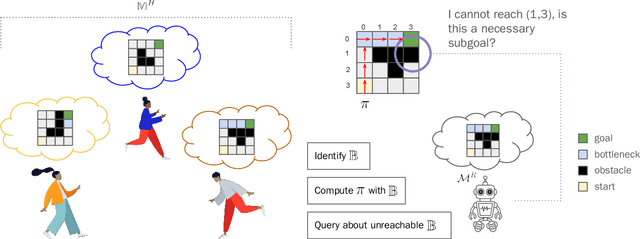
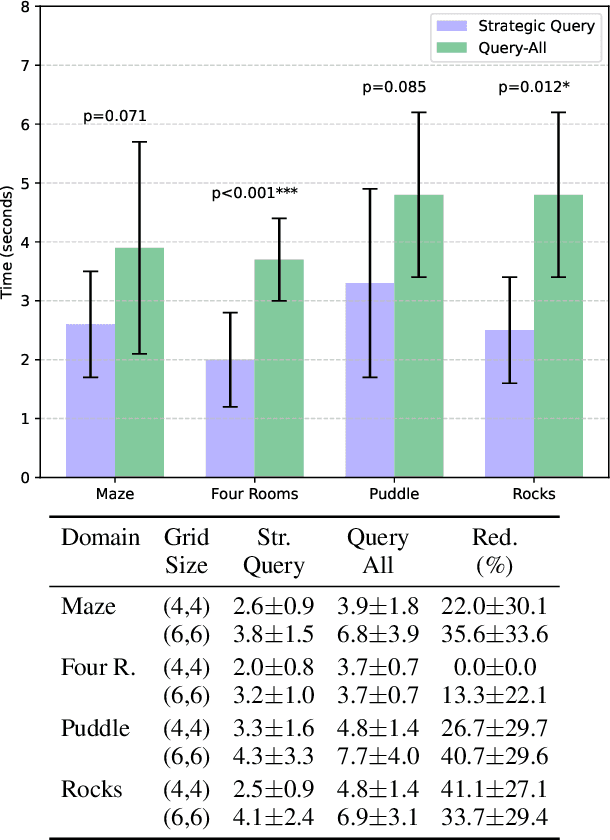
One of the significant challenges to generating value-aligned behavior is to not only account for the specified user objectives but also any implicit or unspecified user requirements. The existence of such implicit requirements could be particularly common in settings where the user's understanding of the task model may differ from the agent's estimate of the model. Under this scenario, the user may incorrectly expect some agent behavior to be inevitable or guaranteed. This paper addresses such expectation mismatch in the presence of differing models by capturing the possibility of unspecified user subgoal in the context of a task captured as a Markov Decision Process (MDP) and querying for it as required. Our method identifies bottleneck states and uses them as candidates for potential implicit subgoals. We then introduce a querying strategy that will generate the minimal number of queries required to identify a policy guaranteed to achieve the underlying goal. Our empirical evaluations demonstrate the effectiveness of our approach in inferring and achieving unstated goals across various tasks.
Human-Modeling in Sequential Decision-Making: An Analysis through the Lens of Human-Aware AI
May 13, 2024

"Human-aware" has become a popular keyword used to describe a particular class of AI systems that are designed to work and interact with humans. While there exists a surprising level of consistency among the works that use the label human-aware, the term itself mostly remains poorly understood. In this work, we retroactively try to provide an account of what constitutes a human-aware AI system. We see that human-aware AI is a design-oriented paradigm, one that focuses on the need for modeling the humans it may interact with. Additionally, we see that this paradigm offers us intuitive dimensions to understand and categorize the kinds of interactions these systems might have with humans. We show the pedagogical value of these dimensions by using them as a tool to understand and review the current landscape of work related to human-AI systems that purport some form of human modeling. To fit the scope of a workshop paper, we specifically narrowed our review to papers that deal with sequential decision-making and were published in a major AI conference in the last three years. Our analysis helps identify the space of potential research problems that are currently being overlooked. We perform additional analysis on the degree to which these works make explicit reference to results from social science and whether they actually perform user-studies to validate their systems. We also provide an accounting of the various AI methods used by these works.
Handling Reward Misspecification in the Presence of Expectation Mismatch
Apr 12, 2024Detecting and handling misspecified objectives, such as reward functions, has been widely recognized as one of the central challenges within the domain of Artificial Intelligence (AI) safety research. However, even with the recognition of the importance of this problem, we are unaware of any works that attempt to provide a clear definition for what constitutes (a) misspecified objectives and (b) successfully resolving such misspecifications. In this work, we use the theory of mind, i.e., the human user's beliefs about the AI agent, as a basis to develop a formal explanatory framework called Expectation Alignment (EAL) to understand the objective misspecification and its causes. Our \EAL\ framework not only acts as an explanatory framework for existing works but also provides us with concrete insights into the limitations of existing methods to handle reward misspecification and novel solution strategies. We use these insights to propose a new interactive algorithm that uses the specified reward to infer potential user expectations about the system behavior. We show how one can efficiently implement this algorithm by mapping the inference problem into linear programs. We evaluate our method on a set of standard Markov Decision Process (MDP) benchmarks.
Towards More Likely Models for AI Planning
Nov 22, 2023



This is the first work to look at the application of large language models (LLMs) for the purpose of model space edits in automated planning tasks. To set the stage for this sangam, we explore two different flavors of model space problems that have been studied in the AI planning literature and explore the effect of an LLM on those tasks. We empirically demonstrate how the performance of an LLM contrasts with combinatorial search (CS) - an approach that has been traditionally used to solve model space tasks in planning, both with the LLM in the role of a standalone model space reasoner as well as in the role of a statistical signal in concert with the CS approach as part of a two-stage process. Our experiments show promising results suggesting further forays of LLMs into the exciting world of model space reasoning for planning tasks in the future.
TOBY: A Tool for Exploring Data in Academic Survey Papers
Jun 13, 2023This paper describes TOBY, a visualization tool that helps a user explore the contents of an academic survey paper. The visualization consists of four components: a hierarchical view of taxonomic data in the survey, a document similarity view in the space of taxonomic classes, a network view of citations, and a new paper recommendation tool. In this paper, we will discuss these features in the context of three separate deployments of the tool.
On the Planning Abilities of Large Language Models -- A Critical Investigation
May 25, 2023



Intrigued by the claims of emergent reasoning capabilities in LLMs trained on general web corpora, in this paper, we set out to investigate their planning capabilities. We aim to evaluate (1) the effectiveness of LLMs in generating plans autonomously in commonsense planning tasks and (2) the potential of LLMs as a source of heuristic guidance for other agents (AI planners) in their planning tasks. We conduct a systematic study by generating a suite of instances on domains similar to the ones employed in the International Planning Competition and evaluate LLMs in two distinct modes: autonomous and heuristic. Our findings reveal that LLMs' ability to generate executable plans autonomously is rather limited, with the best model (GPT-4) having an average success rate of ~12% across the domains. However, the results in the heuristic mode show more promise. In the heuristic mode, we demonstrate that LLM-generated plans can improve the search process for underlying sound planners and additionally show that external verifiers can help provide feedback on the generated plans and back-prompt the LLM for better plan generation.
Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning
May 24, 2023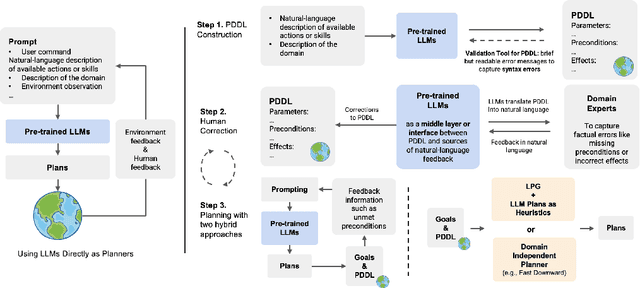

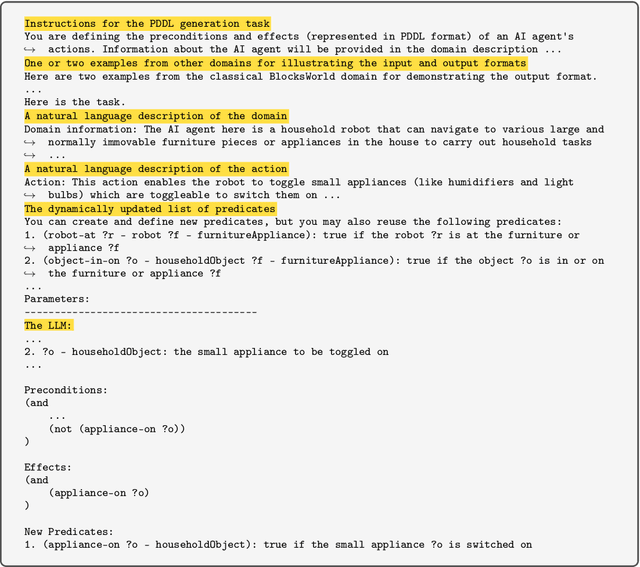
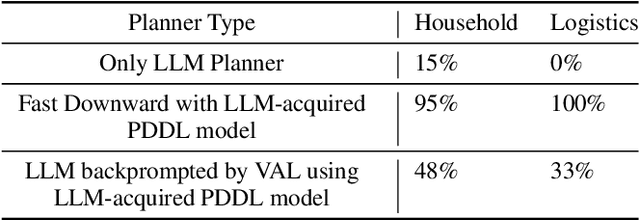
There is a growing interest in applying pre-trained large language models (LLMs) to planning problems. However, methods that use LLMs directly as planners are currently impractical due to several factors, including limited correctness of plans, strong reliance on feedback from interactions with simulators or even the actual environment, and the inefficiency in utilizing human feedback. In this work, we introduce a novel alternative paradigm that constructs an explicit world (domain) model in planning domain definition language (PDDL) and then uses it to plan with sound domain-independent planners. To address the fact that LLMs may not generate a fully functional PDDL model initially, we employ LLMs as an interface between PDDL and sources of corrective feedback, such as PDDL validators and humans. For users who lack a background in PDDL, we show that LLMs can translate PDDL into natural language and effectively encode corrective feedback back to the underlying domain model. Our framework not only enjoys the correctness guarantee offered by the external planners but also reduces human involvement by allowing users to correct domain models at the beginning, rather than inspecting and correcting (through interactive prompting) every generated plan as in previous work. On two IPC domains and a Household domain that is more complicated than commonly used benchmarks such as ALFWorld, we demonstrate that GPT-4 can be leveraged to produce high-quality PDDL models for over 40 actions, and the corrected PDDL models are then used to successfully solve 48 challenging planning tasks. Resources including the source code will be released at: https://guansuns.github.io/pages/llm-dm.
Planning for Attacker Entrapment in Adversarial Settings
Mar 01, 2023In this paper, we propose a planning framework to generate a defense strategy against an attacker who is working in an environment where a defender can operate without the attacker's knowledge. The objective of the defender is to covertly guide the attacker to a trap state from which the attacker cannot achieve their goal. Further, the defender is constrained to achieve its goal within K number of steps, where K is calculated as a pessimistic lower bound within which the attacker is unlikely to suspect a threat in the environment. Such a defense strategy is highly useful in real world systems like honeypots or honeynets, where an unsuspecting attacker interacts with a simulated production system while assuming it is the actual production system. Typically, the interaction between an attacker and a defender is captured using game theoretic frameworks. Our problem formulation allows us to capture it as a much simpler infinite horizon discounted MDP, in which the optimal policy for the MDP gives the defender's strategy against the actions of the attacker. Through empirical evaluation, we show the merits of our problem formulation.