 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Do People Revise Inconsistent Beliefs? Examining Belief Revision in Humans with User Studies
Jun 11, 2025Understanding how humans revise their beliefs in light of new information is crucial for developing AI systems which can effectively model, and thus align with, human reasoning. While theoretical belief revision frameworks rely on a set of principles that establish how these operations are performed, empirical evidence from cognitive psychology suggests that people may follow different patterns when presented with conflicting information. In this paper, we present three comprehensive user studies showing that people consistently prefer explanation-based revisions, i.e., those which are guided by explanations, that result in changes to their belief systems that are not necessarily captured by classical belief change theory. Our experiments systematically investigate how people revise their beliefs with explanations for inconsistencies, whether they are provided with them or left to formulate them themselves, demonstrating a robust preference for what may seem non-minimal revisions across different types of scenarios. These findings have implications for AI systems designed to model human reasoning or interact with humans, suggesting that such systems should accommodate explanation-based, potentially non-minimal belief revision operators to better align with human cognitive processes.
Does Your AI Agent Get You? A Personalizable Framework for Approximating Human Models from Argumentation-based Dialogue Traces
Feb 22, 2025Explainable AI is increasingly employing argumentation methods to facilitate interactive explanations between AI agents and human users. While existing approaches typically rely on predetermined human user models, there remains a critical gap in dynamically learning and updating these models during interactions. In this paper, we present a framework that enables AI agents to adapt their understanding of human users through argumentation-based dialogues. Our approach, called Persona, draws on prospect theory and integrates a probability weighting function with a Bayesian belief update mechanism that refines a probability distribution over possible human models based on exchanged arguments. Through empirical evaluations with human users in an applied argumentation setting, we demonstrate that Persona effectively captures evolving human beliefs, facilitates personalized interactions, and outperforms state-of-the-art methods.
Explainable Distributed Constraint Optimization Problems
Feb 19, 2025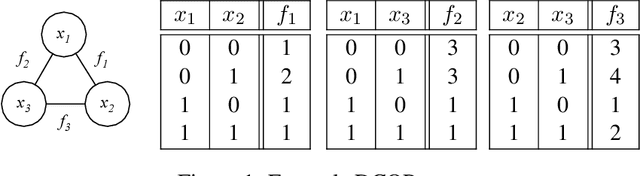
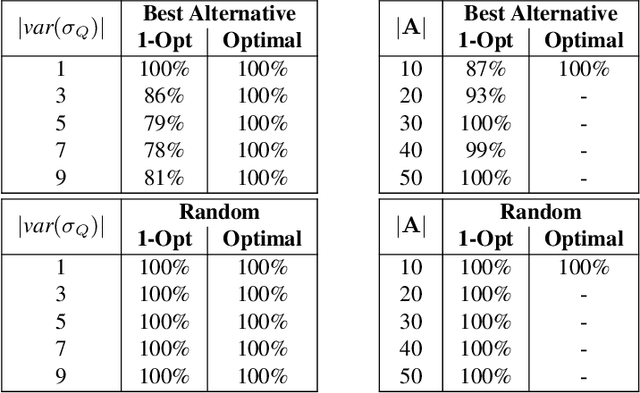
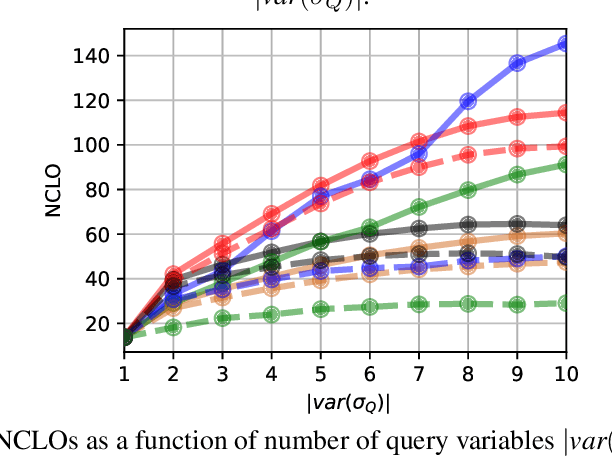
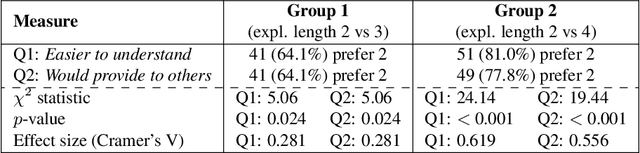
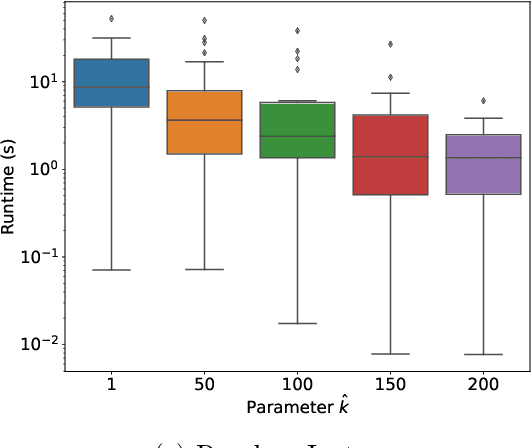
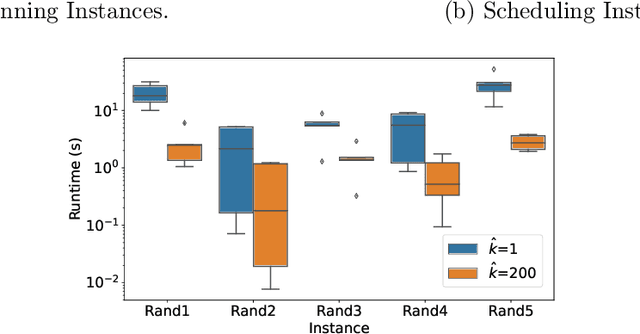
The Distributed Constraint Optimization Problem (DCOP) formulation is a powerful tool to model cooperative multi-agent problems that need to be solved distributively. A core assumption of existing approaches is that DCOP solutions can be easily understood, accepted, and adopted, which may not hold, as evidenced by the large body of literature on Explainable AI. In this paper, we propose the Explainable DCOP (X-DCOP) model, which extends a DCOP to include its solution and a contrastive query for that solution. We formally define some key properties that contrastive explanations must satisfy for them to be considered as valid solutions to X-DCOPs as well as theoretical results on the existence of such valid explanations. To solve X-DCOPs, we propose a distributed framework as well as several optimizations and suboptimal variants to find valid explanations. We also include a human user study that showed that users, not surprisingly, prefer shorter explanations over longer ones. Our empirical evaluations showed that our approach can scale to large problems, and the different variants provide different options for trading off explanation lengths for smaller runtimes. Thus, our model and algorithmic contributions extend the state of the art by reducing the barrier for users to understand DCOP solutions, facilitating their adoption in more real-world applications.
Inferring Implicit Goals Across Differing Task Models
Jan 29, 2025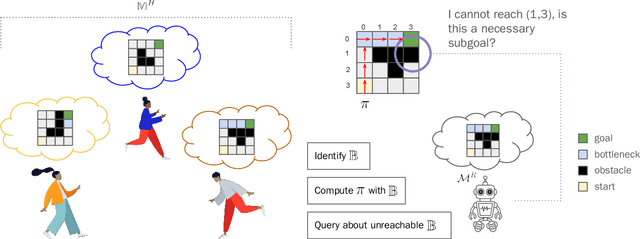
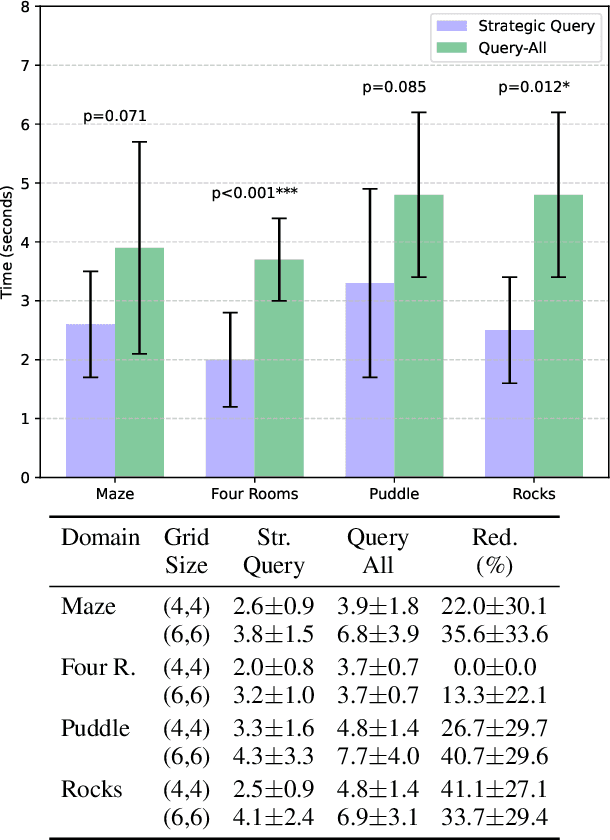
One of the significant challenges to generating value-aligned behavior is to not only account for the specified user objectives but also any implicit or unspecified user requirements. The existence of such implicit requirements could be particularly common in settings where the user's understanding of the task model may differ from the agent's estimate of the model. Under this scenario, the user may incorrectly expect some agent behavior to be inevitable or guaranteed. This paper addresses such expectation mismatch in the presence of differing models by capturing the possibility of unspecified user subgoal in the context of a task captured as a Markov Decision Process (MDP) and querying for it as required. Our method identifies bottleneck states and uses them as candidates for potential implicit subgoals. We then introduce a querying strategy that will generate the minimal number of queries required to identify a policy guaranteed to achieve the underlying goal. Our empirical evaluations demonstrate the effectiveness of our approach in inferring and achieving unstated goals across various tasks.
A Methodology for Gradual Semantics for Structured Argumentation under Incomplete Information
Oct 29, 2024


Gradual semantics have demonstrated great potential in argumentation, in particular for deploying quantitative bipolar argumentation frameworks (QBAFs) in a number of real-world settings, from judgmental forecasting to explainable AI. In this paper, we provide a novel methodology for obtaining gradual semantics for structured argumentation frameworks, where the building blocks of arguments and relations between them are known, unlike in QBAFs, where arguments are abstract entities. Differently from existing approaches, our methodology accommodates incomplete information about arguments' premises. We demonstrate the potential of our approach by introducing two different instantiations of the methodology, leveraging existing gradual semantics for QBAFs in these more complex frameworks. We also define a set of novel properties for gradual semantics in structured argumentation, discuss their suitability over a set of existing properties. Finally, we provide a comprehensive theoretical analysis assessing the instantiations, demonstrating the their advantages over existing gradual semantics for QBAFs and structured argumentation.
TRACE-cs: Trustworthy Reasoning for Contrastive Explanations in Course Scheduling Problems
Sep 05, 2024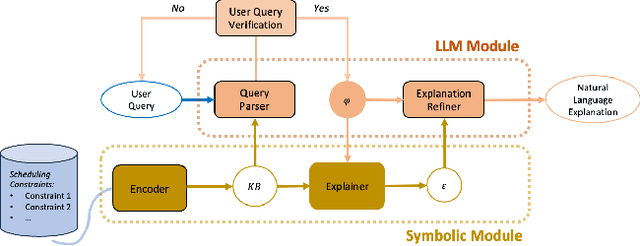

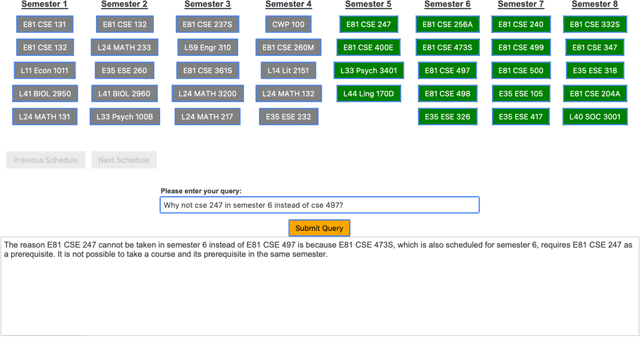
We present TRACE-cs, a novel hybrid system that combines symbolic reasoning with large language models (LLMs) to address contrastive queries in scheduling problems. TRACE-cs leverages SAT solving techniques to encode scheduling constraints and generate explanations for user queries, while utilizing an LLM to process the user queries into logical clauses as well as refine the explanations generated by the symbolic solver to natural language sentences. By integrating these components, our approach demonstrates the potential of combining symbolic methods with LLMs to create explainable AI agents with correctness guarantees.
On Generating Monolithic and Model Reconciling Explanations in Probabilistic Scenarios
May 29, 2024

Explanation generation frameworks aim to make AI systems' decisions transparent and understandable to human users. However, generating explanations in uncertain environments characterized by incomplete information and probabilistic models remains a significant challenge. In this paper, we propose a novel framework for generating probabilistic monolithic explanations and model reconciling explanations. Monolithic explanations provide self-contained reasons for an explanandum without considering the agent receiving the explanation, while model reconciling explanations account for the knowledge of the agent receiving the explanation. For monolithic explanations, our approach integrates uncertainty by utilizing probabilistic logic to increase the probability of the explanandum. For model reconciling explanations, we propose a framework that extends the logic-based variant of the model reconciliation problem to account for probabilistic human models, where the goal is to find explanations that increase the probability of the explanandum while minimizing conflicts between the explanation and the probabilistic human model. We introduce explanatory gain and explanatory power as quantitative metrics to assess the quality of these explanations. Further, we present algorithms that exploit the duality between minimal correction sets and minimal unsatisfiable sets to efficiently compute both types of explanations in probabilistic contexts. Extensive experimental evaluations on various benchmarks demonstrate the effectiveness and scalability of our approach in generating explanations under uncertainty.
Explanation-based Belief Revision: Moving Beyond Minimalism to Explanatory Understanding
May 29, 2024



In belief revision, agents typically modify their beliefs when they receive some new piece of information that is in conflict with them. The guiding principle behind most belief revision frameworks is that of minimalism, which advocates minimal changes to existing beliefs. However, minimalism may not necessarily capture the nuanced ways in which human agents reevaluate and modify their beliefs. In contrast, the explanatory hypothesis indicates that people are inherently driven to seek explanations for inconsistencies, thereby striving for explanatory coherence rather than minimal changes when revising beliefs. Our contribution in this paper is two-fold. Motivated by the explanatory hypothesis, we first present a novel, yet simple belief revision operator that, given a belief base and an explanation for an explanandum, it revises the belief bases in a manner that preserves the explanandum and is not necessarily minimal. We call this operator explanation-based belief revision. Second, we conduct two human-subject studies to empirically validate our approach and investigate belief revision behavior in real-world scenarios. Our findings support the explanatory hypothesis and provide insights into the strategies people employ when resolving inconsistencies.
Approximating Human Models During Argumentation-based Dialogues
May 28, 2024



Explainable AI Planning (XAIP) aims to develop AI agents that can effectively explain their decisions and actions to human users, fostering trust and facilitating human-AI collaboration. A key challenge in XAIP is model reconciliation, which seeks to align the mental models of AI agents and humans. While existing approaches often assume a known and deterministic human model, this simplification may not capture the complexities and uncertainties of real-world interactions. In this paper, we propose a novel framework that enables AI agents to learn and update a probabilistic human model through argumentation-based dialogues. Our approach incorporates trust-based and certainty-based update mechanisms, allowing the agent to refine its understanding of the human's mental state based on the human's expressed trust in the agent's arguments and certainty in their own arguments. We employ a probability weighting function inspired by prospect theory to capture the relationship between trust and perceived probability, and use a Bayesian approach to update the agent's probability distribution over possible human models. We conduct a human-subject study to empirically evaluate the effectiveness of our approach in an argumentation scenario, demonstrating its ability to capture the dynamics of human belief formation and adaptation.
Human-Modeling in Sequential Decision-Making: An Analysis through the Lens of Human-Aware AI
May 13, 2024

"Human-aware" has become a popular keyword used to describe a particular class of AI systems that are designed to work and interact with humans. While there exists a surprising level of consistency among the works that use the label human-aware, the term itself mostly remains poorly understood. In this work, we retroactively try to provide an account of what constitutes a human-aware AI system. We see that human-aware AI is a design-oriented paradigm, one that focuses on the need for modeling the humans it may interact with. Additionally, we see that this paradigm offers us intuitive dimensions to understand and categorize the kinds of interactions these systems might have with humans. We show the pedagogical value of these dimensions by using them as a tool to understand and review the current landscape of work related to human-AI systems that purport some form of human modeling. To fit the scope of a workshop paper, we specifically narrowed our review to papers that deal with sequential decision-making and were published in a major AI conference in the last three years. Our analysis helps identify the space of potential research problems that are currently being overlooked. We perform additional analysis on the degree to which these works make explicit reference to results from social science and whether they actually perform user-studies to validate their systems. We also provide an accounting of the various AI methods used by these works.