 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniRel-R1: RL-tuned LLM Reasoning for Knowledge Graph Relational Question Answering
Dec 18, 2025Knowledge Graph Question Answering (KGQA) has traditionally focused on entity-centric queries that return a single answer entity. However, real-world queries are often relational, seeking to understand how entities are associated. In this work, we introduce relation-centric KGQA, a complementary setting where the answer is a subgraph capturing the semantic connections among entities rather than an individual entity. The main challenge lies in the abundance of candidate subgraphs, where trivial or overly common connections often obscure the identification of unique and informative answers. To tackle this, we propose UniRel-R1, a unified framework that integrates subgraph selection, multi-stage graph pruning, and an LLM fine-tuned with reinforcement learning. The reward function is designed to encourage compact and specific subgraphs with more informative relations and lower-degree intermediate entities. Extensive experiments show that UniRel-R1 achieves significant gains in connectivity and reward over Vanilla baselines and generalizes effectively to unseen entities and relations.
Does Your AI Agent Get You? A Personalizable Framework for Approximating Human Models from Argumentation-based Dialogue Traces
Feb 22, 2025Explainable AI is increasingly employing argumentation methods to facilitate interactive explanations between AI agents and human users. While existing approaches typically rely on predetermined human user models, there remains a critical gap in dynamically learning and updating these models during interactions. In this paper, we present a framework that enables AI agents to adapt their understanding of human users through argumentation-based dialogues. Our approach, called Persona, draws on prospect theory and integrates a probability weighting function with a Bayesian belief update mechanism that refines a probability distribution over possible human models based on exchanged arguments. Through empirical evaluations with human users in an applied argumentation setting, we demonstrate that Persona effectively captures evolving human beliefs, facilitates personalized interactions, and outperforms state-of-the-art methods.
Approximating Human Models During Argumentation-based Dialogues
May 28, 2024



Explainable AI Planning (XAIP) aims to develop AI agents that can effectively explain their decisions and actions to human users, fostering trust and facilitating human-AI collaboration. A key challenge in XAIP is model reconciliation, which seeks to align the mental models of AI agents and humans. While existing approaches often assume a known and deterministic human model, this simplification may not capture the complexities and uncertainties of real-world interactions. In this paper, we propose a novel framework that enables AI agents to learn and update a probabilistic human model through argumentation-based dialogues. Our approach incorporates trust-based and certainty-based update mechanisms, allowing the agent to refine its understanding of the human's mental state based on the human's expressed trust in the agent's arguments and certainty in their own arguments. We employ a probability weighting function inspired by prospect theory to capture the relationship between trust and perceived probability, and use a Bayesian approach to update the agent's probability distribution over possible human models. We conduct a human-subject study to empirically evaluate the effectiveness of our approach in an argumentation scenario, demonstrating its ability to capture the dynamics of human belief formation and adaptation.
Data-Driven Bandit Learning for Proactive Cache Placement in Fog-Assisted IoT Systems
Aug 01, 2020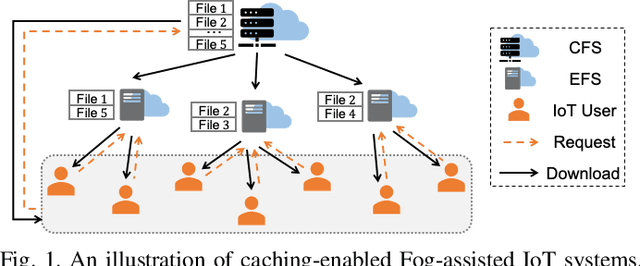
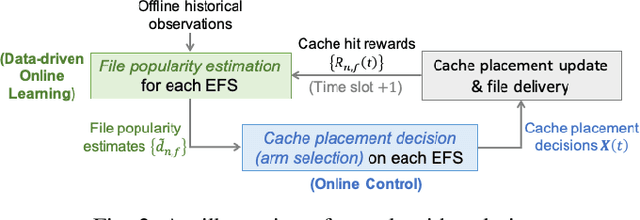

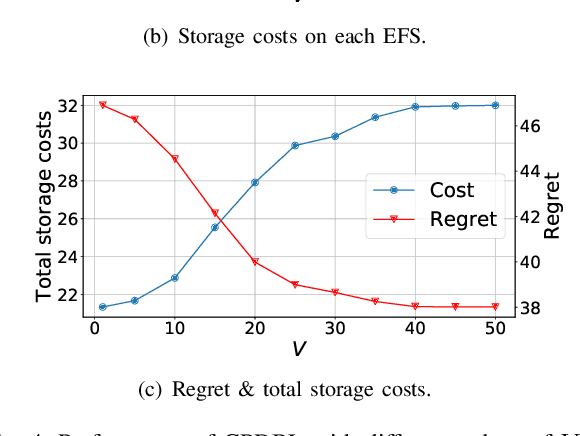
In Fog-assisted IoT systems, it is a common practice to cache popular content at the network edge to achieve high quality of service. Due to uncertainties in practice such as unknown file popularities, cache placement scheme design is still an open problem with unresolved challenges: 1) how to maintain time-averaged storage costs under budgets, 2) how to incorporate online learning to aid cache placement to minimize performance loss (a.k.a. regret), and 3) how to exploit offline history information to further reduce regret. In this paper, we formulate the cache placement problem with unknown file popularities as a constrained combinatorial multi-armed bandit (CMAB) problem. To solve the problem, we employ virtual queue techniques to manage time-averaged constraints, and adopt data-driven bandit learning methods to integrate offline history information into online learning to handle exploration-exploitation tradeoff. With an effective combination of online control and data-driven online learning, we devise a Cache Placement scheme with Data-driven Bandit Learning called CPDBL. Our theoretical analysis and simulations show that CPDBL achieves a sublinear time-averaged regret under long-term storage cost constraints.