 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgumentative Human-AI Decision-Making: Toward AI Agents That Reason With Us, Not For Us
Mar 16, 2026Computational argumentation offers formal frameworks for transparent, verifiable reasoning but has traditionally been limited by its reliance on domain-specific information and extensive feature engineering. In contrast, LLMs excel at processing unstructured text, yet their opaque nature makes their reasoning difficult to evaluate and trust. We argue that the convergence of these fields will lay the foundation for a new paradigm: Argumentative Human-AI Decision-Making. We analyze how the synergy of argumentation framework mining, argumentation framework synthesis, and argumentative reasoning enables agents that do not just justify decisions, but engage in dialectical processes where decisions are contestable and revisable -- reasoning with humans rather than for them. This convergence of computational argumentation and LLMs is essential for human-aware, trustworthy AI in high-stakes domains.
Protecting Language Models Against Unauthorized Distillation through Trace Rewriting
Feb 16, 2026Knowledge distillation is a widely adopted technique for transferring capabilities from LLMs to smaller, more efficient student models. However, unauthorized use of knowledge distillation takes unfair advantage of the considerable effort and cost put into developing frontier models. We investigate methods for modifying teacher-generated reasoning traces to achieve two objectives that deter unauthorized distillation: (1) \emph{anti-distillation}, or degrading the training usefulness of query responses, and (2) \emph{API watermarking}, which embeds verifiable signatures in student models. We introduce several approaches for dynamically rewriting a teacher's reasoning outputs while preserving answer correctness and semantic coherence. Two of these leverage the rewriting capabilities of LLMs, while others use gradient-based techniques. Our experiments show that a simple instruction-based rewriting approach achieves a strong anti-distillation effect while maintaining or even improving teacher performance. Furthermore, we show that our rewriting approach also enables highly reliable watermark detection with essentially no false alarms.
UniRel-R1: RL-tuned LLM Reasoning for Knowledge Graph Relational Question Answering
Dec 18, 2025Knowledge Graph Question Answering (KGQA) has traditionally focused on entity-centric queries that return a single answer entity. However, real-world queries are often relational, seeking to understand how entities are associated. In this work, we introduce relation-centric KGQA, a complementary setting where the answer is a subgraph capturing the semantic connections among entities rather than an individual entity. The main challenge lies in the abundance of candidate subgraphs, where trivial or overly common connections often obscure the identification of unique and informative answers. To tackle this, we propose UniRel-R1, a unified framework that integrates subgraph selection, multi-stage graph pruning, and an LLM fine-tuned with reinforcement learning. The reward function is designed to encourage compact and specific subgraphs with more informative relations and lower-degree intermediate entities. Extensive experiments show that UniRel-R1 achieves significant gains in connectivity and reward over Vanilla baselines and generalizes effectively to unseen entities and relations.
A General Incentives-Based Framework for Fairness in Multi-agent Resource Allocation
Oct 30, 2025We introduce the General Incentives-based Framework for Fairness (GIFF), a novel approach for fair multi-agent resource allocation that infers fair decision-making from standard value functions. In resource-constrained settings, agents optimizing for efficiency often create inequitable outcomes. Our approach leverages the action-value (Q-)function to balance efficiency and fairness without requiring additional training. Specifically, our method computes a local fairness gain for each action and introduces a counterfactual advantage correction term to discourage over-allocation to already well-off agents. This approach is formalized within a centralized control setting, where an arbitrator uses the GIFF-modified Q-values to solve an allocation problem. Empirical evaluations across diverse domains, including dynamic ridesharing, homelessness prevention, and a complex job allocation task-demonstrate that our framework consistently outperforms strong baselines and can discover far-sighted, equitable policies. The framework's effectiveness is supported by a theoretical foundation; we prove its fairness surrogate is a principled lower bound on the true fairness improvement and that its trade-off parameter offers monotonic tuning. Our findings establish GIFF as a robust and principled framework for leveraging standard reinforcement learning components to achieve more equitable outcomes in complex multi-agent systems.
Mind the Gaps: Auditing and Reducing Group Inequity in Large-Scale Mobility Prediction
Oct 30, 2025Next location prediction underpins a growing number of mobility, retail, and public-health applications, yet its societal impacts remain largely unexplored. In this paper, we audit state-of-the-art mobility prediction models trained on a large-scale dataset, highlighting hidden disparities based on user demographics. Drawing from aggregate census data, we compute the difference in predictive performance on racial and ethnic user groups and show a systematic disparity resulting from the underlying dataset, resulting in large differences in accuracy based on location and user groups. To address this, we propose Fairness-Guided Incremental Sampling (FGIS), a group-aware sampling strategy designed for incremental data collection settings. Because individual-level demographic labels are unavailable, we introduce Size-Aware K-Means (SAKM), a clustering method that partitions users in latent mobility space while enforcing census-derived group proportions. This yields proxy racial labels for the four largest groups in the state: Asian, Black, Hispanic, and White. Built on these labels, our sampling algorithm prioritizes users based on expected performance gains and current group representation. This method incrementally constructs training datasets that reduce demographic performance gaps while preserving overall accuracy. Our method reduces total disparity between groups by up to 40\% with minimal accuracy trade-offs, as evaluated on a state-of-art MetaPath2Vec model and a transformer-encoder model. Improvements are most significant in early sampling stages, highlighting the potential for fairness-aware strategies to deliver meaningful gains even in low-resource settings. Our findings expose structural inequities in mobility prediction pipelines and demonstrate how lightweight, data-centric interventions can improve fairness with little added complexity, especially for low-data applications.
How Do People Revise Inconsistent Beliefs? Examining Belief Revision in Humans with User Studies
Jun 11, 2025Understanding how humans revise their beliefs in light of new information is crucial for developing AI systems which can effectively model, and thus align with, human reasoning. While theoretical belief revision frameworks rely on a set of principles that establish how these operations are performed, empirical evidence from cognitive psychology suggests that people may follow different patterns when presented with conflicting information. In this paper, we present three comprehensive user studies showing that people consistently prefer explanation-based revisions, i.e., those which are guided by explanations, that result in changes to their belief systems that are not necessarily captured by classical belief change theory. Our experiments systematically investigate how people revise their beliefs with explanations for inconsistencies, whether they are provided with them or left to formulate them themselves, demonstrating a robust preference for what may seem non-minimal revisions across different types of scenarios. These findings have implications for AI systems designed to model human reasoning or interact with humans, suggesting that such systems should accommodate explanation-based, potentially non-minimal belief revision operators to better align with human cognitive processes.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Remember, but also, Forget: Bridging Myopic and Perfect Recall Fairness with Past-Discounting
Apr 01, 2025Dynamic resource allocation in multi-agent settings often requires balancing efficiency with fairness over time--a challenge inadequately addressed by conventional, myopic fairness measures. Motivated by behavioral insights that human judgments of fairness evolve with temporal distance, we introduce a novel framework for temporal fairness that incorporates past-discounting mechanisms. By applying a tunable discount factor to historical utilities, our approach interpolates between instantaneous and perfect-recall fairness, thereby capturing both immediate outcomes and long-term equity considerations. Beyond aligning more closely with human perceptions of fairness, this past-discounting method ensures that the augmented state space remains bounded, significantly improving computational tractability in sequential decision-making settings. We detail the formulation of discounted-recall fairness in both additive and averaged utility contexts, illustrate its benefits through practical examples, and discuss its implications for designing balanced, scalable resource allocation strategies.
Does Your AI Agent Get You? A Personalizable Framework for Approximating Human Models from Argumentation-based Dialogue Traces
Feb 22, 2025Explainable AI is increasingly employing argumentation methods to facilitate interactive explanations between AI agents and human users. While existing approaches typically rely on predetermined human user models, there remains a critical gap in dynamically learning and updating these models during interactions. In this paper, we present a framework that enables AI agents to adapt their understanding of human users through argumentation-based dialogues. Our approach, called Persona, draws on prospect theory and integrates a probability weighting function with a Bayesian belief update mechanism that refines a probability distribution over possible human models based on exchanged arguments. Through empirical evaluations with human users in an applied argumentation setting, we demonstrate that Persona effectively captures evolving human beliefs, facilitates personalized interactions, and outperforms state-of-the-art methods.
Explainable Distributed Constraint Optimization Problems
Feb 19, 2025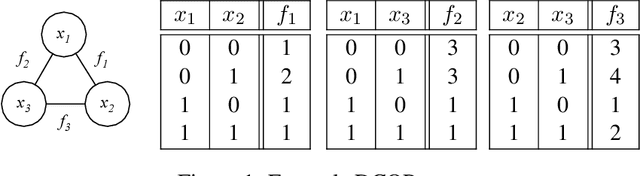
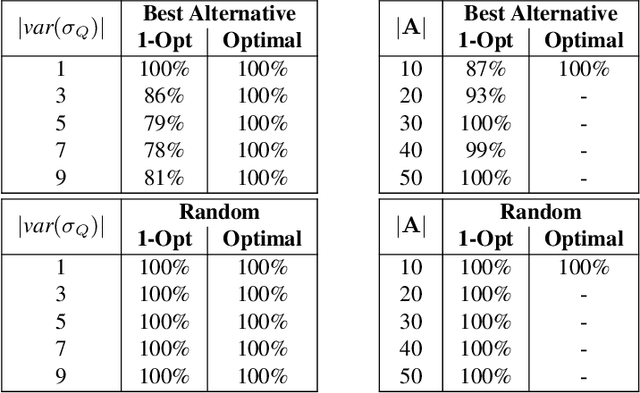
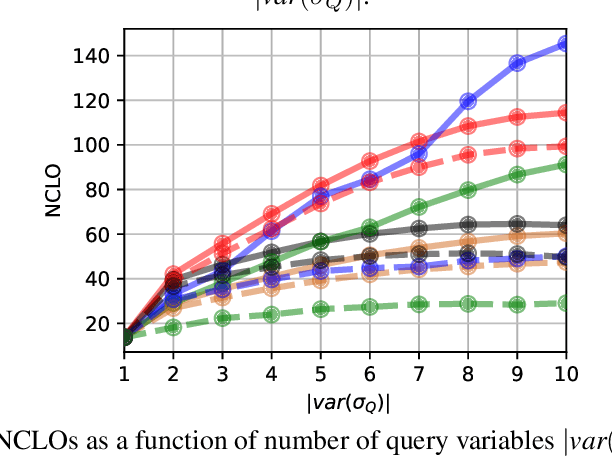
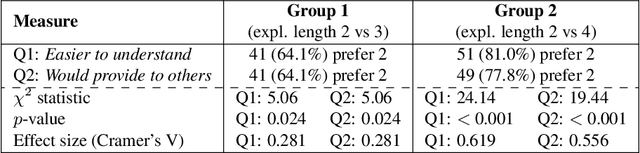
The Distributed Constraint Optimization Problem (DCOP) formulation is a powerful tool to model cooperative multi-agent problems that need to be solved distributively. A core assumption of existing approaches is that DCOP solutions can be easily understood, accepted, and adopted, which may not hold, as evidenced by the large body of literature on Explainable AI. In this paper, we propose the Explainable DCOP (X-DCOP) model, which extends a DCOP to include its solution and a contrastive query for that solution. We formally define some key properties that contrastive explanations must satisfy for them to be considered as valid solutions to X-DCOPs as well as theoretical results on the existence of such valid explanations. To solve X-DCOPs, we propose a distributed framework as well as several optimizations and suboptimal variants to find valid explanations. We also include a human user study that showed that users, not surprisingly, prefer shorter explanations over longer ones. Our empirical evaluations showed that our approach can scale to large problems, and the different variants provide different options for trading off explanation lengths for smaller runtimes. Thus, our model and algorithmic contributions extend the state of the art by reducing the barrier for users to understand DCOP solutions, facilitating their adoption in more real-world applications.