 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Optimization and Learning of Fair Court Schedules
Oct 22, 2024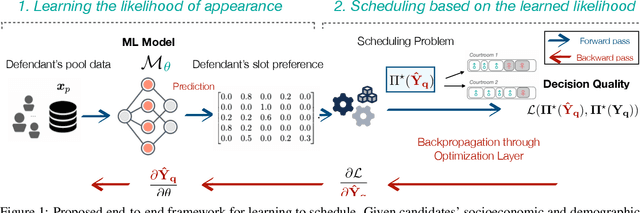

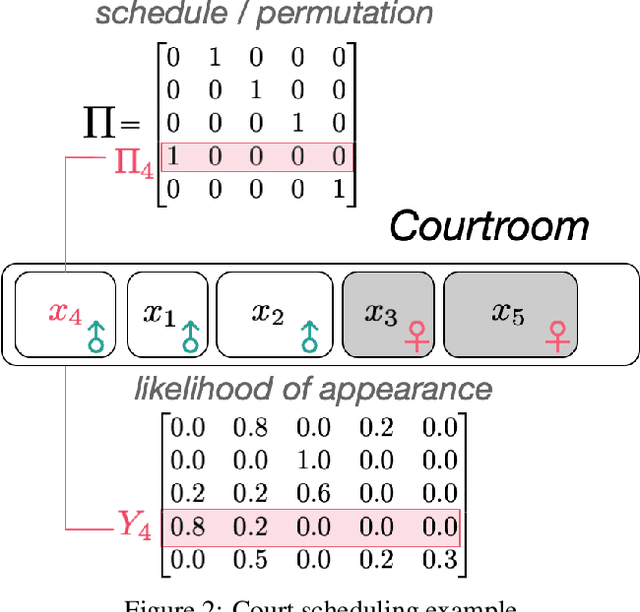
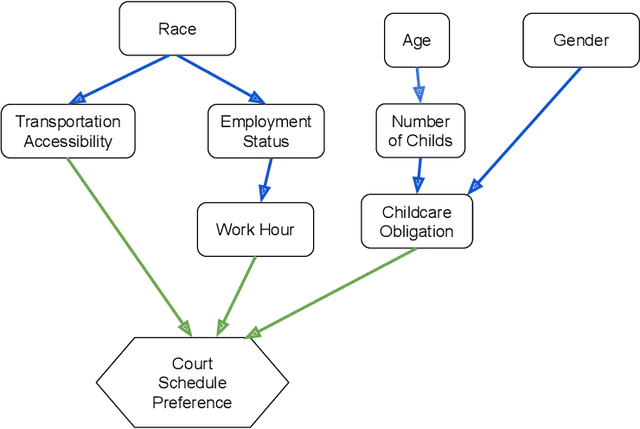
Criminal courts across the United States handle millions of cases every year, and the scheduling of those cases must accommodate a diverse set of constraints, including the preferences and availability of courts, prosecutors, and defense teams. When criminal court schedules are formed, defendants' scheduling preferences often take the least priority, although defendants may face significant consequences (including arrest or detention) for missed court dates. Additionally, studies indicate that defendants' nonappearances impose costs on the courts and other system stakeholders. To address these issues, courts and commentators have begun to recognize that pretrial outcomes for defendants and for the system would be improved with greater attention to court processes, including \emph{court scheduling practices}. There is thus a need for fair criminal court pretrial scheduling systems that account for defendants' preferences and availability, but the collection of such data poses logistical challenges. Furthermore, optimizing schedules fairly across various parties' preferences is a complex optimization problem, even when such data is available. In an effort to construct such a fair scheduling system under data uncertainty, this paper proposes a joint optimization and learning framework that combines machine learning models trained end-to-end with efficient matching algorithms. This framework aims to produce court scheduling schedules that optimize a principled measure of fairness, balancing the availability and preferences of all parties.
Learning Joint Models of Prediction and Optimization
Sep 07, 2024



The Predict-Then-Optimize framework uses machine learning models to predict unknown parameters of an optimization problem from exogenous features before solving. This setting is common to many real-world decision processes, and recently it has been shown that decision quality can be substantially improved by solving and differentiating the optimization problem within an end-to-end training loop. However, this approach requires significant computational effort in addition to handcrafted, problem-specific rules for backpropagation through the optimization step, challenging its applicability to a broad class of optimization problems. This paper proposes an alternative method, in which optimal solutions are learned directly from the observable features by joint predictive models. The approach is generic, and based on an adaptation of the Learning-to-Optimize paradigm, from which a rich variety of existing techniques can be employed. Experimental evaluations show the ability of several Learning-to-Optimize methods to provide efficient and accurate solutions to an array of challenging Predict-Then-Optimize problems.
Metric Learning to Accelerate Convergence of Operator Splitting Methods for Differentiable Parametric Programming
Apr 01, 2024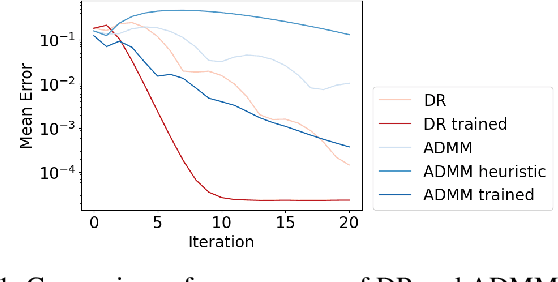
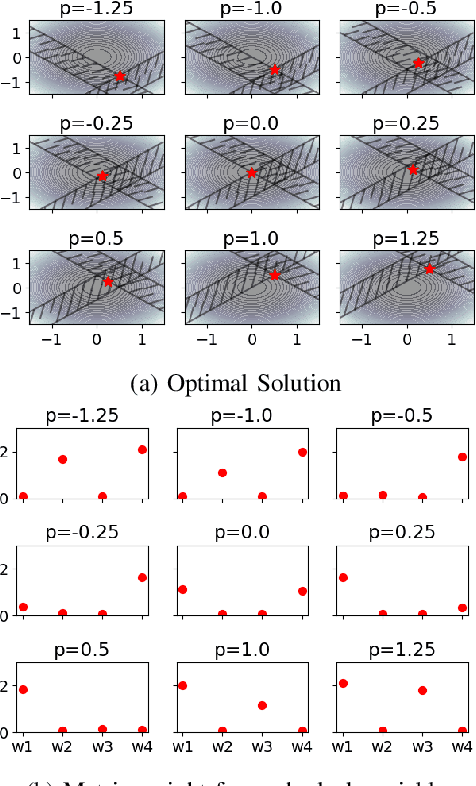
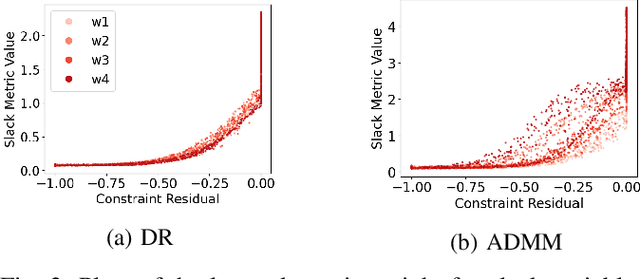
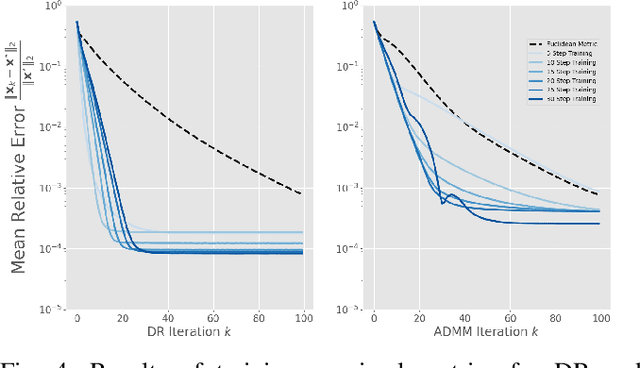
Recent work has shown a variety of ways in which machine learning can be used to accelerate the solution of constrained optimization problems. Increasing demand for real-time decision-making capabilities in applications such as artificial intelligence and optimal control has led to a variety of approaches, based on distinct strategies. This work proposes a novel approach to learning optimization, in which the underlying metric space of a proximal operator splitting algorithm is learned so as to maximize its convergence rate. While prior works in optimization theory have derived optimal metrics for limited classes of problems, the results do not extend to many practical problem forms including general Quadratic Programming (QP). This paper shows how differentiable optimization can enable the end-to-end learning of proximal metrics, enhancing the convergence of proximal algorithms for QP problems beyond what is possible based on known theory. Additionally, the results illustrate a strong connection between the learned proximal metrics and active constraints at the optima, leading to an interpretation in which the learning of proximal metrics can be viewed as a form of active set learning.
Learning Constrained Optimization with Deep Augmented Lagrangian Methods
Mar 14, 2024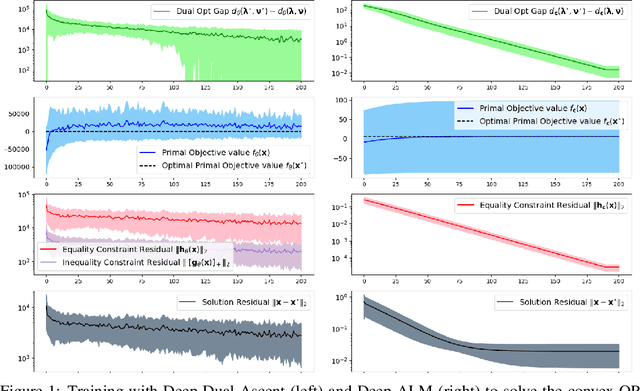
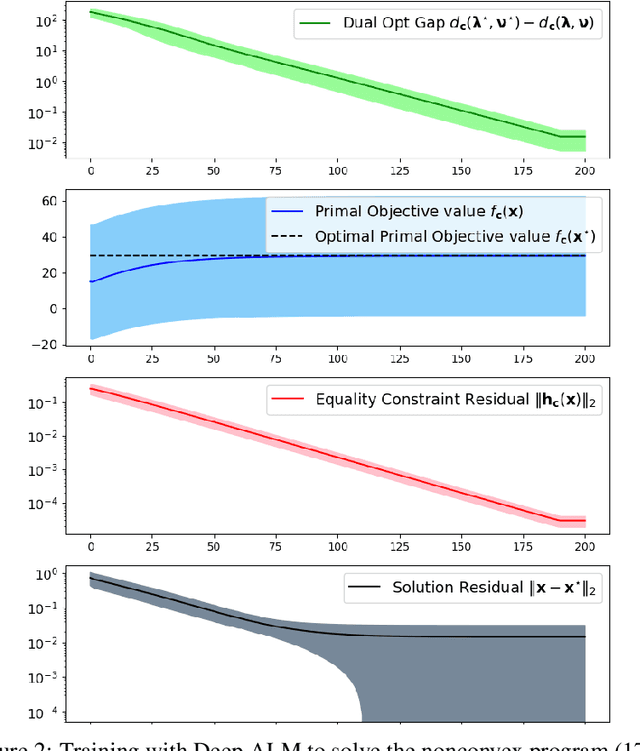
Learning to Optimize (LtO) is a problem setting in which a machine learning (ML) model is trained to emulate a constrained optimization solver. Learning to produce optimal and feasible solutions subject to complex constraints is a difficult task, but is often made possible by restricting the input space to a limited distribution of related problems. Most LtO methods focus on directly learning solutions to the primal problem, and applying correction schemes or loss function penalties to encourage feasibility. This paper proposes an alternative approach, in which the ML model is trained instead to predict dual solution estimates directly, from which primal estimates are constructed to form dual-feasible solution pairs. This enables an end-to-end training scheme is which the dual objective is maximized as a loss function, and solution estimates iterate toward primal feasibility, emulating a Dual Ascent method. First it is shown that the poor convergence properties of classical Dual Ascent are reflected in poor convergence of the proposed training scheme. Then, by incorporating techniques from practical Augmented Lagrangian methods, we show how the training scheme can be improved to learn highly accurate constrained optimization solvers, for both convex and nonconvex problems.
End-to-End Learning for Fair Multiobjective Optimization Under Uncertainty
Feb 12, 2024



Many decision processes in artificial intelligence and operations research are modeled by parametric optimization problems whose defining parameters are unknown and must be inferred from observable data. The Predict-Then-Optimize (PtO) paradigm in machine learning aims to maximize downstream decision quality by training the parametric inference model end-to-end with the subsequent constrained optimization. This requires backpropagation through the optimization problem using approximation techniques specific to the problem's form, especially for nondifferentiable linear and mixed-integer programs. This paper extends the PtO methodology to optimization problems with nondifferentiable Ordered Weighted Averaging (OWA) objectives, known for their ability to ensure properties of fairness and robustness in decision models. Through a collection of training techniques and proposed application settings, it shows how optimization of OWA functions can be effectively integrated with parametric prediction for fair and robust optimization under uncertainty.
Learning Fair Ranking Policies via Differentiable Optimization of Ordered Weighted Averages
Feb 07, 2024

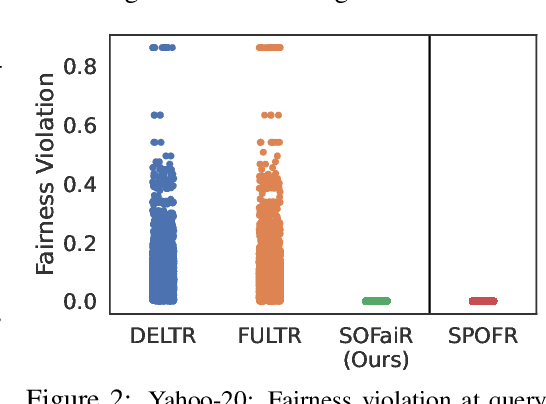

Learning to Rank (LTR) is one of the most widely used machine learning applications. It is a key component in platforms with profound societal impacts, including job search, healthcare information retrieval, and social media content feeds. Conventional LTR models have been shown to produce biases results, stimulating a discourse on how to address the disparities introduced by ranking systems that solely prioritize user relevance. However, while several models of fair learning to rank have been proposed, they suffer from deficiencies either in accuracy or efficiency, thus limiting their applicability to real-world ranking platforms. This paper shows how efficiently-solvable fair ranking models, based on the optimization of Ordered Weighted Average (OWA) functions, can be integrated into the training loop of an LTR model to achieve favorable balances between fairness, user utility, and runtime efficiency. In particular, this paper is the first to show how to backpropagate through constrained optimizations of OWA objectives, enabling their use in integrated prediction and decision models.
Analyzing and Enhancing the Backward-Pass Convergence of Unrolled Optimization
Dec 28, 2023The integration of constrained optimization models as components in deep networks has led to promising advances on many specialized learning tasks. A central challenge in this setting is backpropagation through the solution of an optimization problem, which often lacks a closed form. One typical strategy is algorithm unrolling, which relies on automatic differentiation through the entire chain of operations executed by an iterative optimization solver. This paper provides theoretical insights into the backward pass of unrolled optimization, showing that it is asymptotically equivalent to the solution of a linear system by a particular iterative method. Several practical pitfalls of unrolling are demonstrated in light of these insights, and a system called Folded Optimization is proposed to construct more efficient backpropagation rules from unrolled solver implementations. Experiments over various end-to-end optimization and learning tasks demonstrate the advantages of this system both computationally, and in terms of flexibility over various optimization problem forms.
Predict-Then-Optimize by Proxy: Learning Joint Models of Prediction and Optimization
Nov 22, 2023
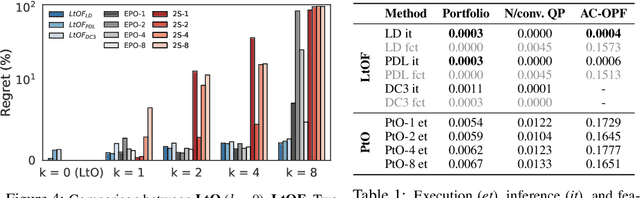
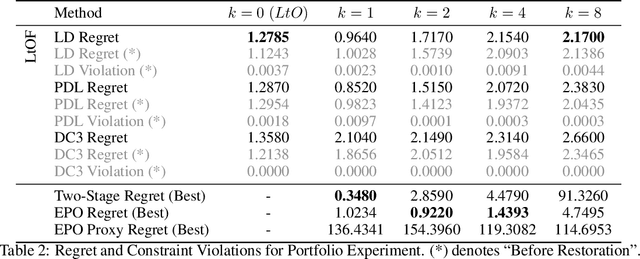
Many real-world decision processes are modeled by optimization problems whose defining parameters are unknown and must be inferred from observable data. The Predict-Then-Optimize framework uses machine learning models to predict unknown parameters of an optimization problem from features before solving. Recent works show that decision quality can be improved in this setting by solving and differentiating the optimization problem in the training loop, enabling end-to-end training with loss functions defined directly on the resulting decisions. However, this approach can be inefficient and requires handcrafted, problem-specific rules for backpropagation through the optimization step. This paper proposes an alternative method, in which optimal solutions are learned directly from the observable features by predictive models. The approach is generic, and based on an adaptation of the Learning-to-Optimize paradigm, from which a rich variety of existing techniques can be employed. Experimental evaluations show the ability of several Learning-to-Optimize methods to provide efficient, accurate, and flexible solutions to an array of challenging Predict-Then-Optimize problems.
Decision-Focused Learning: Foundations, State of the Art, Benchmark and Future Opportunities
Aug 16, 2023



Decision-focused learning (DFL) is an emerging paradigm in machine learning which trains a model to optimize decisions, integrating prediction and optimization in an end-to-end system. This paradigm holds the promise to revolutionize decision-making in many real-world applications which operate under uncertainty, where the estimation of unknown parameters within these decision models often becomes a substantial roadblock. This paper presents a comprehensive review of DFL. It provides an in-depth analysis of the various techniques devised to integrate machine learning and optimization models, introduces a taxonomy of DFL methods distinguished by their unique characteristics, and conducts an extensive empirical evaluation of these methods proposing suitable benchmark dataset and tasks for DFL. Finally, the study provides valuable insights into current and potential future avenues in DFL research.
Folded Optimization for End-to-End Model-Based Learning
Jan 28, 2023



The integration of constrained optimization models as components in deep networks has led to promising advances in both these domains. A primary challenge in this setting is backpropagation through the optimization mapping, which typically lacks a closed form. A common approach is unrolling, which relies on automatic differentiation through the operations of an iterative solver. While flexible and general, unrolling can encounter accuracy and efficiency issues in practice. These issues can be avoided by differentiating the optimization mapping analytically, but current frameworks impose rigid requirements on the optimization problem's form. This paper provides theoretical insights into the backpropagation of unrolled optimizers, which lead to a system for generating equivalent but efficiently solvable analytical models. Additionally, it proposes a unifying view of unrolling and analytical differentiation through constrained optimization mappings. Experiments over various structured prediction and decision-focused learning tasks illustrate the potential of the approach both computationally and in terms of enhanced expressiveness.