 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Constrained Optimization with Deep Augmented Lagrangian Methods
Paper and Code
Mar 14, 2024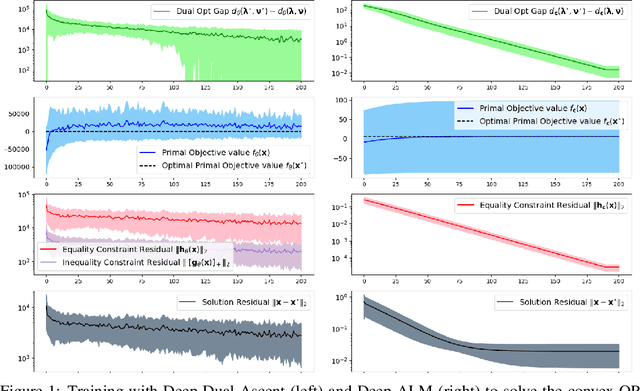
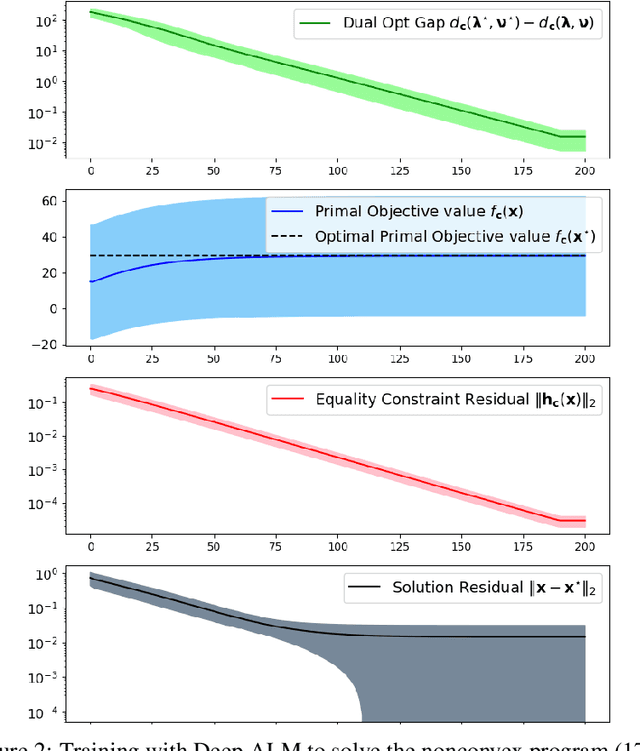
Learning to Optimize (LtO) is a problem setting in which a machine learning (ML) model is trained to emulate a constrained optimization solver. Learning to produce optimal and feasible solutions subject to complex constraints is a difficult task, but is often made possible by restricting the input space to a limited distribution of related problems. Most LtO methods focus on directly learning solutions to the primal problem, and applying correction schemes or loss function penalties to encourage feasibility. This paper proposes an alternative approach, in which the ML model is trained instead to predict dual solution estimates directly, from which primal estimates are constructed to form dual-feasible solution pairs. This enables an end-to-end training scheme is which the dual objective is maximized as a loss function, and solution estimates iterate toward primal feasibility, emulating a Dual Ascent method. First it is shown that the poor convergence properties of classical Dual Ascent are reflected in poor convergence of the proposed training scheme. Then, by incorporating techniques from practical Augmented Lagrangian methods, we show how the training scheme can be improved to learn highly accurate constrained optimization solvers, for both convex and nonconvex problems.