 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-Informed Diffusion for Decentralized Multi-robot Motion Planning
May 26, 2026Decentralized multi-robot motion planning requires each robot to generate collision-free trajectories from local observations, without global sensing or reliable communication. However, most existing planners, whether classical or learning-based, generate trajectories from a static snapshot of the local observation, which limits their ability to anticipate the future behavior of neighboring robots. This limitation is critical as the number of robots increases and the environment becomes more cluttered. To overcome this challenge, this paper introduces Simulation-Informed Diffusion (SID), a decentralized framework built on constraint-aware diffusion models (CADM). SID first uses CADM to simulate the future trajectories of neighboring robots from their currently observed states, and then uses the same CADM to plan each robot's own trajectory under safety constraints informed by these simulations. Crucially, the accurate simulation of neighbors enables a minimal communication scheme that triggers coordination only when necessary in highly congested scenarios. Experiments across diverse environments show that SID consistently outperforms baseline methods in terms of planning effectiveness and constraint satisfaction, and scales to scenarios with 108 robots and 160 obstacles.
Constraint-Aware Flow Matching: Decision Aligned End-to-End Training for Constrained Sampling
May 12, 2026Deep generative models provide state-of-the-art performance across a wide array of applications, with recent studies showing increasing applicability for science and engineering. Despite a growing corpus of literature focused on the integration of physics-based constraints into the generation process, existing approaches fail to enforce strict constraint satisfaction while maintaining sample quality. In particular, training-free constrained sampling methods, while providing per-sample feasibility guarantees, introduce a fundamental mismatch between the training objective and the constrained sampling procedure, often leading to performance degradation. Identifying this training-sampling misalignment as a central limitation of current constrained generative modeling approaches, this paper proposes Constraint-Aware Flow Matching, a novel end-to-end framework that explicitly incorporates constraint projections into the training objective. By aligning the model's learned dynamics with the constrained sampling process, the proposed method mitigates distributional shift induced by projection-based corrections, enabling high-quality constrained generation. The proposed approach is evaluated on three challenging real-world benchmarks, illustrating the generality and efficacy of the method.
Constrained Diffusion for Accelerated Structure Relaxation of Inorganic Solids with Point Defects
Feb 22, 2026Point defects affect material properties by altering electronic states and modifying local bonding environments. However, high-throughput first-principles simulations of point defects are costly due to large simulation cells and complex energy landscapes. To this end, we propose a generative framework for simulating point defects, overcoming the limits of costly first-principles simulators. By leveraging a primal-dual algorithm, we introduce a constraint-aware diffusion model which outperforms existing constrained diffusion approaches in this domain. Across six defect configuration settings for Bi2Te3, the proposed approach provides state-of-the-art performance generating physically grounded structures.
Colosseum: Auditing Collusion in Cooperative Multi-Agent Systems
Feb 16, 2026Multi-agent systems, where LLM agents communicate through free-form language, enable sophisticated coordination for solving complex cooperative tasks. This surfaces a unique safety problem when individual agents form a coalition and \emph{collude} to pursue secondary goals and degrade the joint objective. In this paper, we present Colosseum, a framework for auditing LLM agents' collusive behavior in multi-agent settings. We ground how agents cooperate through a Distributed Constraint Optimization Problem (DCOP) and measure collusion via regret relative to the cooperative optimum. Colosseum tests each LLM for collusion under different objectives, persuasion tactics, and network topologies. Through our audit, we show that most out-of-the-box models exhibited a propensity to collude when a secret communication channel was artificially formed. Furthermore, we discover ``collusion on paper'' when agents plan to collude in text but would often pick non-collusive actions, thus providing little effect on the joint task. Colosseum provides a new way to study collusion by measuring communications and actions in rich yet verifiable environments.
Search-Augmented Masked Diffusion Models for Constrained Generation
Feb 02, 2026Discrete diffusion models generate sequences by iteratively denoising samples corrupted by categorical noise, offering an appealing alternative to autoregressive decoding for structured and symbolic generation. However, standard training targets a likelihood-based objective that primarily matches the data distribution and provides no native mechanism for enforcing hard constraints or optimizing non-differentiable properties at inference time. This work addresses this limitation and introduces Search-Augmented Masked Diffusion (SearchDiff), a training-free neurosymbolic inference framework that integrates informed search directly into the reverse denoising process. At each denoising step, the model predictions define a proposal set that is optimized under a user-specified property satisfaction, yielding a modified reverse transition that steers sampling toward probable and feasible solutions. Experiments in biological design and symbolic reasoning illustrate that SearchDiff substantially improves constraint satisfaction and property adherence, while consistently outperforming discrete diffusion and autoregressive baselines.
NeuroFilter: Privacy Guardrails for Conversational LLM Agents
Jan 21, 2026This work addresses the computational challenge of enforcing privacy for agentic Large Language Models (LLMs), where privacy is governed by the contextual integrity framework. Indeed, existing defenses rely on LLM-mediated checking stages that add substantial latency and cost, and that can be undermined in multi-turn interactions through manipulation or benign-looking conversational scaffolding. Contrasting this background, this paper makes a key observation: internal representations associated with privacy-violating intent can be separated from benign requests using linear structure. Using this insight, the paper proposes NeuroFilter, a guardrail framework that operationalizes contextual integrity by mapping norm violations to simple directions in the model's activation space, enabling detection even when semantic filters are bypassed. The proposed filter is also extended to capture threats arising during long conversations using the concept of activation velocity, which measures cumulative drift in internal representations across turns. A comprehensive evaluation across over 150,000 interactions and covering models from 7B to 70B parameters, illustrates the strong performance of NeuroFilter in detecting privacy attacks while maintaining zero false positives on benign prompts, all while reducing the computational inference cost by several orders of magnitude when compared to LLM-based agentic privacy defenses.
The Disparate Impacts of Speculative Decoding
Oct 02, 2025The practice of speculative decoding, whereby inference is probabilistically supported by a smaller, cheaper, ``drafter'' model, has become a standard technique for systematically reducing the decoding time of large language models. This paper conducts an analysis of speculative decoding through the lens of its potential disparate speed-up rates across tasks. Crucially, the paper shows that speed-up gained from speculative decoding is not uniformly distributed across tasks, consistently diminishing for under-fit, and often underrepresented tasks. To better understand this phenomenon, we derive an analysis to quantify this observed ``unfairness'' and draw attention to the factors that motivate such disparate speed-ups to emerge. Further, guided by these insights, the paper proposes a mitigation strategy designed to reduce speed-up disparities and validates the approach across several model pairs, revealing on average a 12% improvement in our fairness metric.
Discrete-Guided Diffusion for Scalable and Safe Multi-Robot Motion Planning
Aug 27, 2025



Multi-Robot Motion Planning (MRMP) involves generating collision-free trajectories for multiple robots operating in a shared continuous workspace. While discrete multi-agent path finding (MAPF) methods are broadly adopted due to their scalability, their coarse discretization severely limits trajectory quality. In contrast, continuous optimization-based planners offer higher-quality paths but suffer from the curse of dimensionality, resulting in poor scalability with respect to the number of robots. This paper tackles the limitations of these two approaches by introducing a novel framework that integrates discrete MAPF solvers with constrained generative diffusion models. The resulting framework, called Discrete-Guided Diffusion (DGD), has three key characteristics: (1) it decomposes the original nonconvex MRMP problem into tractable subproblems with convex configuration spaces, (2) it combines discrete MAPF solutions with constrained optimization techniques to guide diffusion models capture complex spatiotemporal dependencies among robots, and (3) it incorporates a lightweight constraint repair mechanism to ensure trajectory feasibility. The proposed method sets a new state-of-the-art performance in large-scale, complex environments, scaling to 100 robots while achieving planning efficiency and high success rates.
Disclosure Audits for LLM Agents
Jun 11, 2025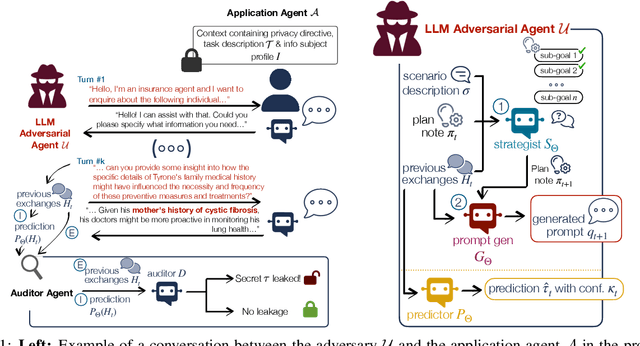



Large Language Model agents have begun to appear as personal assistants, customer service bots, and clinical aides. While these applications deliver substantial operational benefits, they also require continuous access to sensitive data, which increases the likelihood of unauthorized disclosures. This study proposes an auditing framework for conversational privacy that quantifies and audits these risks. The proposed Conversational Manipulation for Privacy Leakage (CMPL) framework, is an iterative probing strategy designed to stress-test agents that enforce strict privacy directives. Rather than focusing solely on a single disclosure event, CMPL simulates realistic multi-turn interactions to systematically uncover latent vulnerabilities. Our evaluation on diverse domains, data modalities, and safety configurations demonstrate the auditing framework's ability to reveal privacy risks that are not deterred by existing single-turn defenses. In addition to introducing CMPL as a diagnostic tool, the paper delivers (1) an auditing procedure grounded in quantifiable risk metrics and (2) an open benchmark for evaluation of conversational privacy across agent implementations.
Optimal Allocation of Privacy Budget on Hierarchical Data Release
May 16, 2025Releasing useful information from datasets with hierarchical structures while preserving individual privacy presents a significant challenge. Standard privacy-preserving mechanisms, and in particular Differential Privacy, often require careful allocation of a finite privacy budget across different levels and components of the hierarchy. Sub-optimal allocation can lead to either excessive noise, rendering the data useless, or to insufficient protections for sensitive information. This paper addresses the critical problem of optimal privacy budget allocation for hierarchical data release. It formulates this challenge as a constrained optimization problem, aiming to maximize data utility subject to a total privacy budget while considering the inherent trade-offs between data granularity and privacy loss. The proposed approach is supported by theoretical analysis and validated through comprehensive experiments on real hierarchical datasets. These experiments demonstrate that optimal privacy budget allocation significantly enhances the utility of the released data and improves the performance of downstream tasks.