 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Robust Optimization with Data-Driven Uncertainty for Enhancing Distribution System Resilience
May 16, 2025Extreme weather events are placing growing strain on electric power systems, exposing the limitations of purely reactive responses and prompting the need for proactive resilience planning. However, existing approaches often rely on simplified uncertainty models and decouple proactive and reactive decisions, overlooking their critical interdependence. This paper proposes a novel tri-level optimization framework that integrates proactive infrastructure investment, adversarial modeling of spatio-temporal disruptions, and adaptive reactive response. We construct high-probability, distribution-free uncertainty sets using conformal prediction to capture complex and data-scarce outage patterns. To solve the resulting nested decision problem, we derive a bi-level reformulation via strong duality and develop a scalable Benders decomposition algorithm. Experiments on both real and synthetic data demonstrate that our approach consistently outperforms conventional robust and two-stage methods, achieving lower worst-case losses and more efficient resource allocation, especially under tight operational constraints and large-scale uncertainty.
Knowledge Distillation for Enhancing Walmart E-commerce Search Relevance Using Large Language Models
May 11, 2025
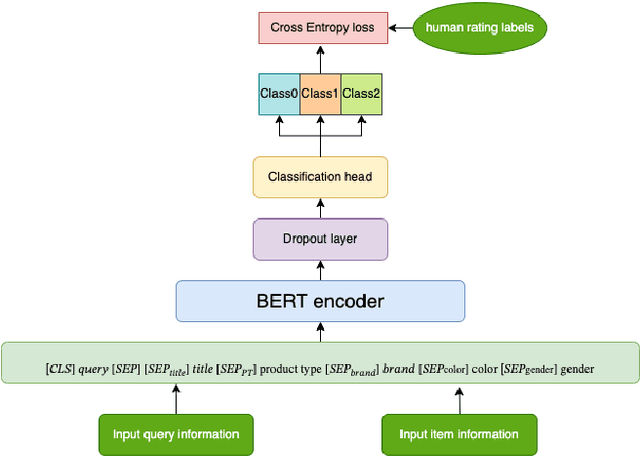
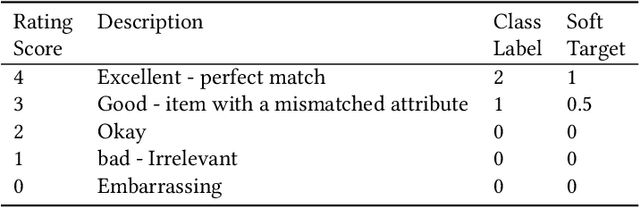
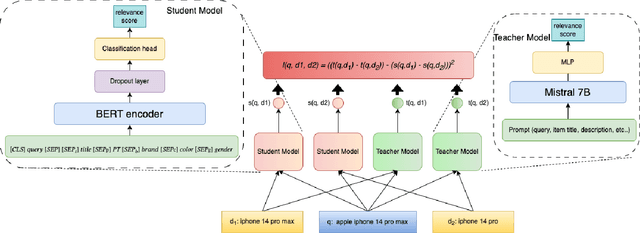
Ensuring the products displayed in e-commerce search results are relevant to users queries is crucial for improving the user experience. With their advanced semantic understanding, deep learning models have been widely used for relevance matching in search tasks. While large language models (LLMs) offer superior ranking capabilities, it is challenging to deploy LLMs in real-time systems due to the high-latency requirements. To leverage the ranking power of LLMs while meeting the low-latency demands of production systems, we propose a novel framework that distills a high performing LLM into a more efficient, low-latency student model. To help the student model learn more effectively from the teacher model, we first train the teacher LLM as a classification model with soft targets. Then, we train the student model to capture the relevance margin between pairs of products for a given query using mean squared error loss. Instead of using the same training data as the teacher model, we significantly expand the student model dataset by generating unlabeled data and labeling it with the teacher model predictions. Experimental results show that the student model performance continues to improve as the size of the augmented training data increases. In fact, with enough augmented data, the student model can outperform the teacher model. The student model has been successfully deployed in production at Walmart.com with significantly positive metrics.
* 9 pages, published at WWWW'25
Global-Decision-Focused Neural ODEs for Proactive Grid Resilience Management
Feb 25, 2025Extreme hazard events such as wildfires and hurricanes increasingly threaten power systems, causing widespread outages and disrupting critical services. Recently, predict-then-optimize approaches have gained traction in grid operations, where system functionality forecasts are first generated and then used as inputs for downstream decision-making. However, this two-stage method often results in a misalignment between prediction and optimization objectives, leading to suboptimal resource allocation. To address this, we propose predict-all-then-optimize-globally (PATOG), a framework that integrates outage prediction with globally optimized interventions. At its core, our global-decision-focused (GDF) neural ODE model captures outage dynamics while optimizing resilience strategies in a decision-aware manner. Unlike conventional methods, our approach ensures spatially and temporally coherent decision-making, improving both predictive accuracy and operational efficiency. Experiments on synthetic and real-world datasets demonstrate significant improvements in outage prediction consistency and grid resilience.
Gen-DFL: Decision-Focused Generative Learning for Robust Decision Making
Feb 08, 2025
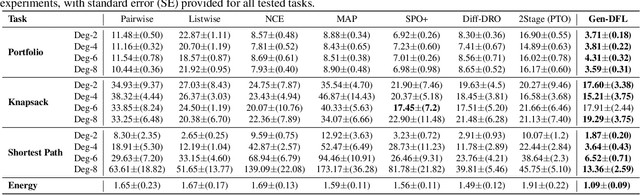


Decision-focused learning (DFL) integrates predictive models with downstream optimization, directly training machine learning models to minimize decision errors. While DFL has been shown to provide substantial advantages when compared to a counterpart that treats the predictive and prescriptive models separately, it has also been shown to struggle in high-dimensional and risk-sensitive settings, limiting its applicability in real-world settings. To address this limitation, this paper introduces decision-focused generative learning (Gen-DFL), a novel framework that leverages generative models to adaptively model uncertainty and improve decision quality. Instead of relying on fixed uncertainty sets, Gen-DFL learns a structured representation of the optimization parameters and samples from the tail regions of the learned distribution to enhance robustness against worst-case scenarios. This approach mitigates over-conservatism while capturing complex dependencies in the parameter space. The paper shows, theoretically, that Gen-DFL achieves improved worst-case performance bounds compared to traditional DFL. Empirically, it evaluates Gen-DFL on various scheduling and logistics problems, demonstrating its strong performance against existing DFL methods.
RIS-based Over-the-air Diffractional Channel Coding
Aug 17, 2024



Reconfigurable Intelligent Surfaces (RIS) are programmable metasurfaces utilizing sub-wavelength meta-atoms and a controller for precise electromagnetic wave manipulation. This work introduces an innovative channel coding scheme, termed RIS-based diffractional channel coding (DCC), which capitalizes on diffraction between two RIS layers for signal-level encoding. Contrary to traditional methods, DCC expands signal dimensions through diffraction, presenting a novel countermeasure to channel effects. This paper focuses on the operational principles of DCC, including encoder and decoder designs, and explores its possibilities to construct block and trellis codes, demonstrating its potential as both an alternative and a supplementary conventional coding scheme. Key advantages of DCC include eliminating extra power requirements for encoding, achieving computation at the speed of light, and enabling adjustable code distance, making it a progressive solution for efficient wireless communication, particularly in systems with large-scale data or massive MIMO.
Counterfactual Fairness through Transforming Data Orthogonal to Bias
Mar 26, 2024



Machine learning models have shown exceptional prowess in solving complex issues across various domains. Nonetheless, these models can sometimes exhibit biased decision-making, leading to disparities in treatment across different groups. Despite the extensive research on fairness, the nuanced effects of multivariate and continuous sensitive variables on decision-making outcomes remain insufficiently studied. We introduce a novel data pre-processing algorithm, Orthogonal to Bias (OB), designed to remove the influence of a group of continuous sensitive variables, thereby facilitating counterfactual fairness in machine learning applications. Our approach is grounded in the assumption of a jointly normal distribution within a structural causal model (SCM), proving that counterfactual fairness can be achieved by ensuring the data is uncorrelated with sensitive variables. The OB algorithm is model-agnostic, catering to a wide array of machine learning models and tasks, and includes a sparse variant to enhance numerical stability through regularization. Through empirical evaluation on simulated and real-world datasets - including the adult income and the COMPAS recidivism datasets - our methodology demonstrates its capacity to enable fairer outcomes without compromising accuracy.
RIS-Based On-the-Air Semantic Communications -- a Diffractional Deep Neural Network Approach
Dec 01, 2023Semantic communication has gained significant attention recently due to its advantages in achieving higher transmission efficiency by focusing on semantic information instead of bit-level information. However, current AI-based semantic communication methods require digital hardware for implementation. With the rapid advancement on reconfigurable intelligence surfaces (RISs), a new approach called on-the-air diffractional deep neural networks (D$^2$NN) can be utilized to enable semantic communications on the wave domain. This paper proposes a new paradigm of RIS-based on-the-air semantic communications, where the computational process occurs inherently as wireless signals pass through RISs. We present the system model and discuss the data and control flows of this scheme, followed by a performance analysis using image transmission as an example. In comparison to traditional hardware-based approaches, RIS-based semantic communications offer appealing features, such as light-speed computation, low computational power requirements, and the ability to handle multiple tasks simultaneously.
API-Assisted Code Generation for Question Answering on Varied Table Structures
Oct 23, 2023



A persistent challenge to table question answering (TableQA) by generating executable programs has been adapting to varied table structures, typically requiring domain-specific logical forms. In response, this paper introduces a unified TableQA framework that: (1) provides a unified representation for structured tables as multi-index Pandas data frames, (2) uses Python as a powerful querying language, and (3) uses few-shot prompting to translate NL questions into Python programs, which are executable on Pandas data frames. Furthermore, to answer complex relational questions with extended program functionality and external knowledge, our framework allows customized APIs that Python programs can call. We experiment with four TableQA datasets that involve tables of different structures -- relational, multi-table, and hierarchical matrix shapes -- and achieve prominent improvements over past state-of-the-art systems. In ablation studies, we (1) show benefits from our multi-index representation and APIs over baselines that use only an LLM, and (2) demonstrate that our approach is modular and can incorporate additional APIs.
Uncertainty-Aware Robust Learning on Noisy Graphs
Jun 14, 2023



Graph neural networks have shown impressive capabilities in solving various graph learning tasks, particularly excelling in node classification. However, their effectiveness can be hindered by the challenges arising from the widespread existence of noisy measurements associated with the topological or nodal information present in real-world graphs. These inaccuracies in observations can corrupt the crucial patterns within the graph data, ultimately resulting in undesirable performance in practical applications. To address these issues, this paper proposes a novel uncertainty-aware graph learning framework motivated by distributionally robust optimization. Specifically, we use a graph neural network-based encoder to embed the node features and find the optimal node embeddings by minimizing the worst-case risk through a minimax formulation. Such an uncertainty-aware learning process leads to improved node representations and a more robust graph predictive model that effectively mitigates the impact of uncertainty arising from data noise. Our experimental result shows that the proposed framework achieves superior predictive performance compared to the state-of-the-art baselines under various noisy settings.
Approach to Learning Generalized Audio Representation Through Batch Embedding Covariance Regularization and Constant-Q Transforms
Mar 07, 2023General-purpose embedding is highly desirable for few-shot even zero-shot learning in many application scenarios, including audio tasks. In order to understand representations better, we conducted a thorough error analysis and visualization of HEAR 2021 submission results. Inspired by the analysis, this work experiments with different front-end audio preprocessing methods, including Constant-Q Transform (CQT) and Short-time Fourier transform (STFT), and proposes a Batch Embedding Covariance Regularization (BECR) term to uncover a more holistic simulation of the frequency information received by the human auditory system. We tested the models on the suite of HEAR 2021 tasks, which encompass a broad category of tasks. Preliminary results show (1) the proposed BECR can incur a more dispersed embedding on the test set, (2) BECR improves the PaSST model without extra computation complexity, and (3) STFT preprocessing outperforms CQT in all tasks we tested. Github:https://github.com/ankitshah009/general_audio_embedding_hear_2021