 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Enhancing Walmart E-commerce Search Relevance Using Large Language Models
May 11, 2025
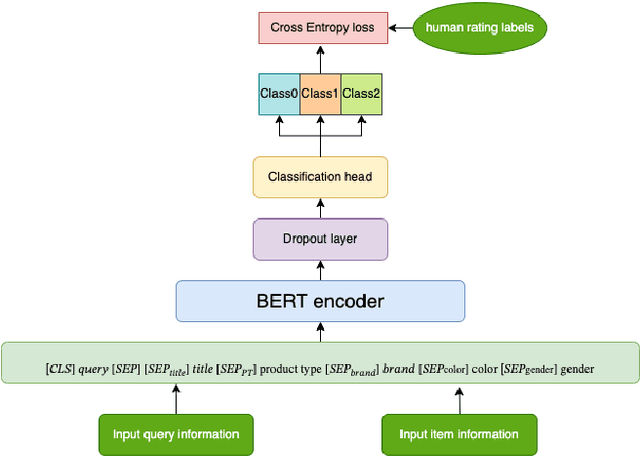
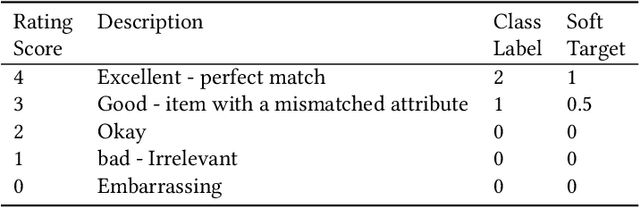
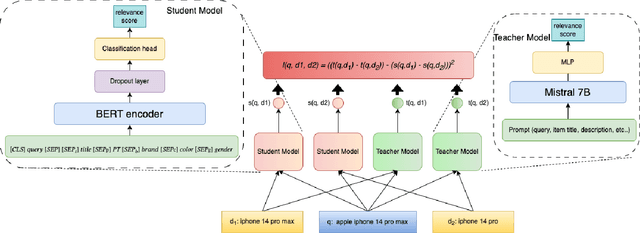
Ensuring the products displayed in e-commerce search results are relevant to users queries is crucial for improving the user experience. With their advanced semantic understanding, deep learning models have been widely used for relevance matching in search tasks. While large language models (LLMs) offer superior ranking capabilities, it is challenging to deploy LLMs in real-time systems due to the high-latency requirements. To leverage the ranking power of LLMs while meeting the low-latency demands of production systems, we propose a novel framework that distills a high performing LLM into a more efficient, low-latency student model. To help the student model learn more effectively from the teacher model, we first train the teacher LLM as a classification model with soft targets. Then, we train the student model to capture the relevance margin between pairs of products for a given query using mean squared error loss. Instead of using the same training data as the teacher model, we significantly expand the student model dataset by generating unlabeled data and labeling it with the teacher model predictions. Experimental results show that the student model performance continues to improve as the size of the augmented training data increases. In fact, with enough augmented data, the student model can outperform the teacher model. The student model has been successfully deployed in production at Walmart.com with significantly positive metrics.
* 9 pages, published at WWWW'25
Enhancing Incremental Summarization with Structured Representations
Jul 21, 2024



Large language models (LLMs) often struggle with processing extensive input contexts, which can lead to redundant, inaccurate, or incoherent summaries. Recent methods have used unstructured memory to incrementally process these contexts, but they still suffer from information overload due to the volume of unstructured data handled. In our study, we introduce structured knowledge representations ($GU_{json}$), which significantly improve summarization performance by 40% and 14% across two public datasets. Most notably, we propose the Chain-of-Key strategy ($CoK_{json}$) that dynamically updates or augments these representations with new information, rather than recreating the structured memory for each new source. This method further enhances performance by 7% and 4% on the datasets.
STRUM-LLM: Attributed and Structured Contrastive Summarization
Mar 25, 2024Users often struggle with decision-making between two options (A vs B), as it usually requires time-consuming research across multiple web pages. We propose STRUM-LLM that addresses this challenge by generating attributed, structured, and helpful contrastive summaries that highlight key differences between the two options. STRUM-LLM identifies helpful contrast: the specific attributes along which the two options differ significantly and which are most likely to influence the user's decision. Our technique is domain-agnostic, and does not require any human-labeled data or fixed attribute list as supervision. STRUM-LLM attributes all extractions back to the input sources along with textual evidence, and it does not have a limit on the length of input sources that it can process. STRUM-LLM Distilled has 100x more throughput than the models with comparable performance while being 10x smaller. In this paper, we provide extensive evaluations for our method and lay out future directions for our currently deployed system.
Hierarchical Multi-head Attentive Network for Evidence-aware Fake News Detection
Feb 04, 2021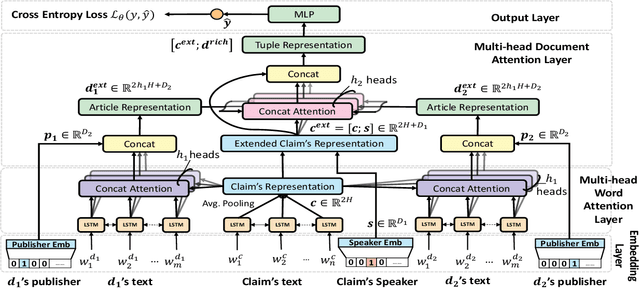
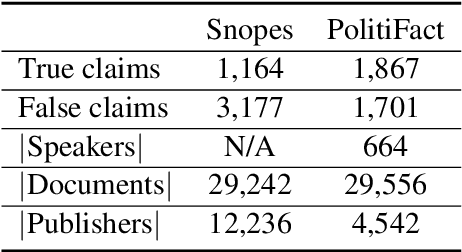
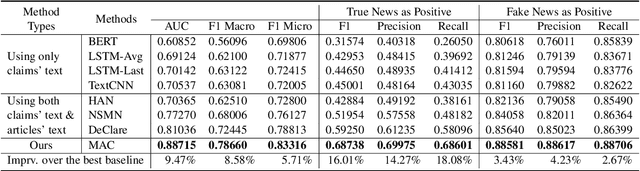
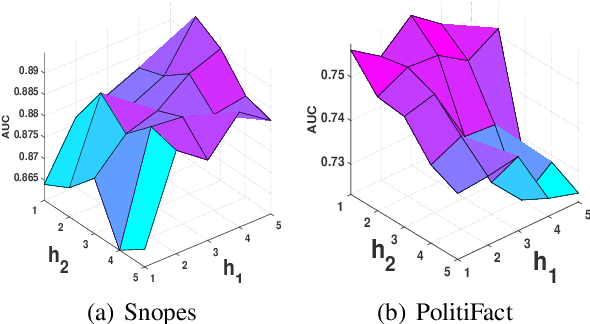
The widespread of fake news and misinformation in various domains ranging from politics, economics to public health has posed an urgent need to automatically fact-check information. A recent trend in fake news detection is to utilize evidence from external sources. However, existing evidence-aware fake news detection methods focused on either only word-level attention or evidence-level attention, which may result in suboptimal performance. In this paper, we propose a Hierarchical Multi-head Attentive Network to fact-check textual claims. Our model jointly combines multi-head word-level attention and multi-head document-level attention, which aid explanation in both word-level and evidence-level. Experiments on two real-word datasets show that our model outperforms seven state-of-the-art baselines. Improvements over baselines are from 6\% to 18\%. Our source code and datasets are released at \texttt{\url{https://github.com/nguyenvo09/EACL2021}}.
Simplified DOM Trees for Transferable Attribute Extraction from the Web
Jan 07, 2021
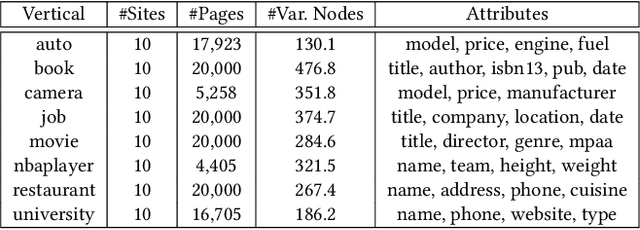
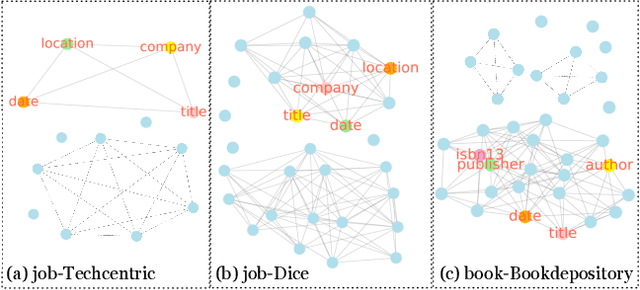
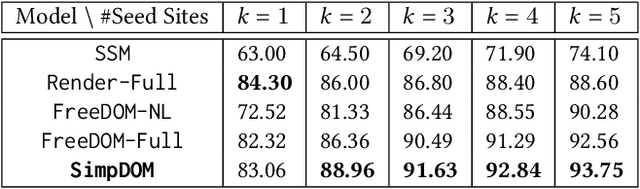
There has been a steady need to precisely extract structured knowledge from the web (i.e. HTML documents). Given a web page, extracting a structured object along with various attributes of interest (e.g. price, publisher, author, and genre for a book) can facilitate a variety of downstream applications such as large-scale knowledge base construction, e-commerce product search, and personalized recommendation. Considering each web page is rendered from an HTML DOM tree, existing approaches formulate the problem as a DOM tree node tagging task. However, they either rely on computationally expensive visual feature engineering or are incapable of modeling the relationship among the tree nodes. In this paper, we propose a novel transferable method, Simplified DOM Trees for Attribute Extraction (SimpDOM), to tackle the problem by efficiently retrieving useful context for each node by leveraging the tree structure. We study two challenging experimental settings: (i) intra-vertical few-shot extraction, and (ii) cross-vertical fewshot extraction with out-of-domain knowledge, to evaluate our approach. Extensive experiments on the SWDE public dataset show that SimpDOM outperforms the state-of-the-art (SOTA) method by 1.44% on the F1 score. We also find that utilizing knowledge from a different vertical (cross-vertical extraction) is surprisingly useful and helps beat the SOTA by a further 1.37%.
FreeDOM: A Transferable Neural Architecture for Structured Information Extraction on Web Documents
Oct 21, 2020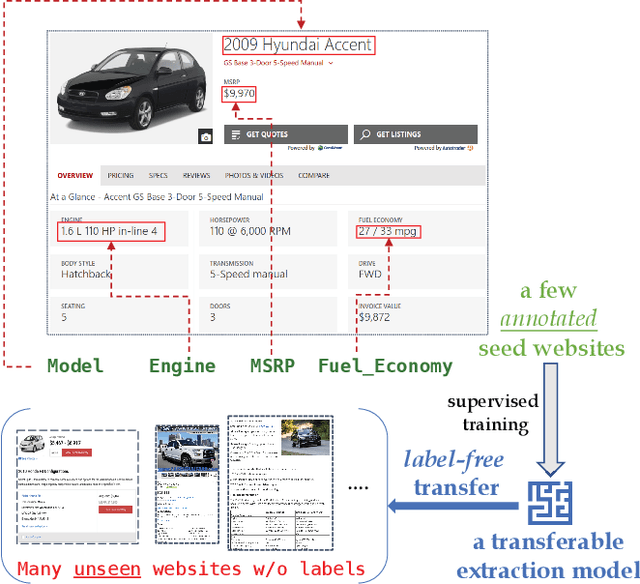
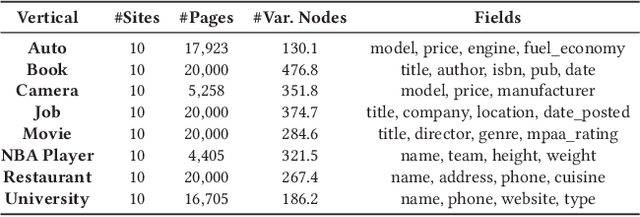

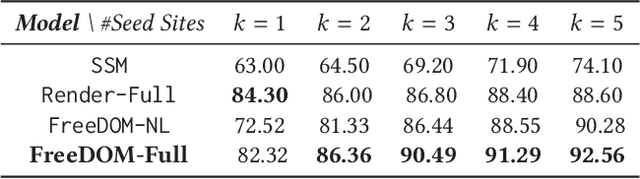
Extracting structured data from HTML documents is a long-studied problem with a broad range of applications like augmenting knowledge bases, supporting faceted search, and providing domain-specific experiences for key verticals like shopping and movies. Previous approaches have either required a small number of examples for each target site or relied on carefully handcrafted heuristics built over visual renderings of websites. In this paper, we present a novel two-stage neural approach, named FreeDOM, which overcomes both these limitations. The first stage learns a representation for each DOM node in the page by combining both the text and markup information. The second stage captures longer range distance and semantic relatedness using a relational neural network. By combining these stages, FreeDOM is able to generalize to unseen sites after training on a small number of seed sites from that vertical without requiring expensive hand-crafted features over visual renderings of the page. Through experiments on a public dataset with 8 different verticals, we show that FreeDOM beats the previous state of the art by nearly 3.7 F1 points on average without requiring features over rendered pages or expensive hand-crafted features.
Where Are the Facts? Searching for Fact-checked Information to Alleviate the Spread of Fake News
Oct 07, 2020

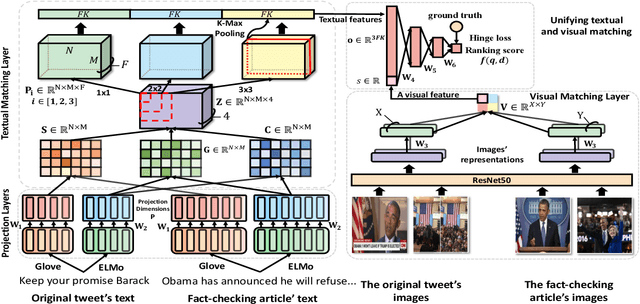
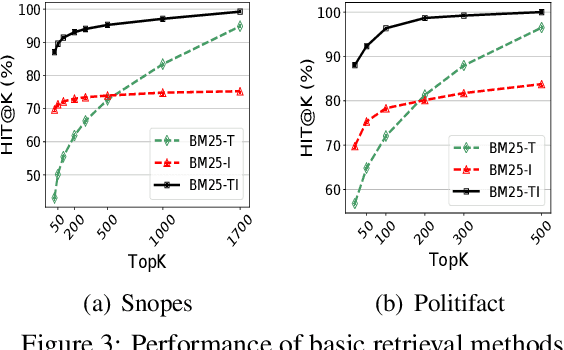
Although many fact-checking systems have been developed in academia and industry, fake news is still proliferating on social media. These systems mostly focus on fact-checking but usually neglect online users who are the main drivers of the spread of misinformation. How can we use fact-checked information to improve users' consciousness of fake news to which they are exposed? How can we stop users from spreading fake news? To tackle these questions, we propose a novel framework to search for fact-checking articles, which address the content of an original tweet (that may contain misinformation) posted by online users. The search can directly warn fake news posters and online users (e.g. the posters' followers) about misinformation, discourage them from spreading fake news, and scale up verified content on social media. Our framework uses both text and images to search for fact-checking articles, and achieves promising results on real-world datasets. Our code and datasets are released at https://github.com/nguyenvo09/EMNLP2020.
Attributed Multi-Relational Attention Network for Fact-checking URL Recommendation
Jan 07, 2020

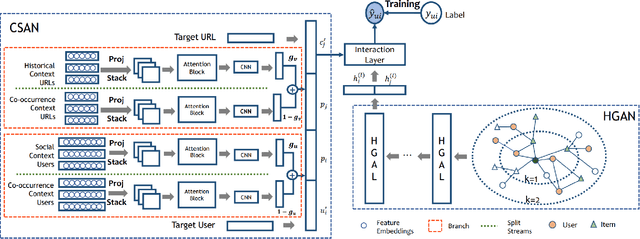
To combat fake news, researchers mostly focused on detecting fake news and journalists built and maintained fact-checking sites (e.g., Snopes.com and Politifact.com). However, fake news dissemination has been greatly promoted via social media sites, and these fact-checking sites have not been fully utilized. To overcome these problems and complement existing methods against fake news, in this paper we propose a deep-learning based fact-checking URL recommender system to mitigate impact of fake news in social media sites such as Twitter and Facebook. In particular, our proposed framework consists of a multi-relational attentive module and a heterogeneous graph attention network to learn complex/semantic relationship between user-URL pairs, user-user pairs, and URL-URL pairs. Extensive experiments on a real-world dataset show that our proposed framework outperforms eight state-of-the-art recommendation models, achieving at least 3~5.3% improvement.
Learning from Fact-checkers: Analysis and Generation of Fact-checking Language
Oct 05, 2019
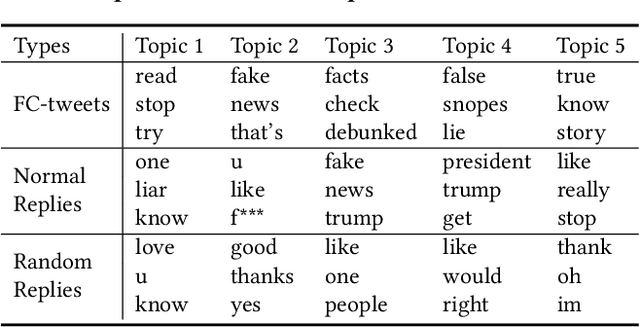
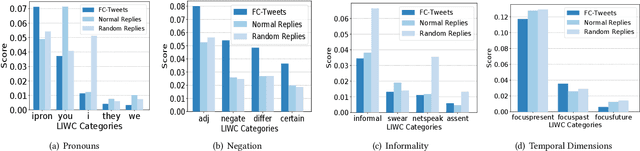

In fighting against fake news, many fact-checking systems comprised of human-based fact-checking sites (e.g., snopes.com and politifact.com) and automatic detection systems have been developed in recent years. However, online users still keep sharing fake news even when it has been debunked. It means that early fake news detection may be insufficient and we need another complementary approach to mitigate the spread of misinformation. In this paper, we introduce a novel application of text generation for combating fake news. In particular, we (1) leverage online users named \emph{fact-checkers}, who cite fact-checking sites as credible evidences to fact-check information in public discourse; (2) analyze linguistic characteristics of fact-checking tweets; and (3) propose and build a deep learning framework to generate responses with fact-checking intention to increase the fact-checkers' engagement in fact-checking activities. Our analysis reveals that the fact-checkers tend to refute misinformation and use formal language (e.g. few swear words and Internet slangs). Our framework successfully generates relevant responses, and outperforms competing models by achieving up to 30\% improvements. Our qualitative study also confirms that the superiority of our generated responses compared with responses generated from the existing models.
Identifying On-time Reward Delivery Projects with Estimating Delivery Duration on Kickstarter
Oct 12, 2017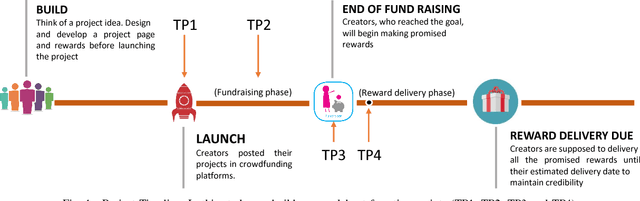

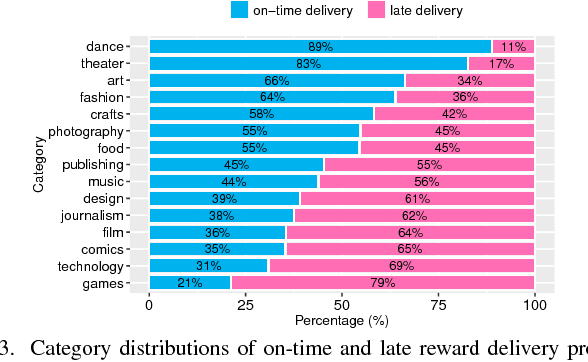
In Crowdfunding platforms, people turn their prototype ideas into real products by raising money from the crowd, or invest in someone else's projects. In reward-based crowdfunding platforms such as Kickstarter and Indiegogo, selecting accurate reward delivery duration becomes crucial for creators, backers, and platform providers to keep the trust between the creators and the backers, and the trust between the platform providers and users. According to Kickstarter, 35% backers did not receive rewards on time. Unfortunately, little is known about on-time and late reward delivery projects, and there is no prior work to estimate reward delivery duration. To fill the gap, in this paper, we (i) extract novel features that reveal latent difficulty levels of project rewards; (ii) build predictive models to identify whether a creator will deliver all rewards in a project on time or not; and (iii) build a regression model to estimate accurate reward delivery duration (i.e., how long it will take to produce and deliver all the rewards). Experimental results show that our models achieve good performance -- 82.5% accuracy, 78.1 RMSE, and 0.108 NRMSE at the first 5% of the longest reward delivery duration.