 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualSphinx: Large-Scale Synthetic Vision Logic Puzzles for RL
May 29, 2025Vision language models (VLMs) are expected to perform effective multimodal reasoning and make logically coherent decisions, which is critical to tasks such as diagram understanding and spatial problem solving. However, current VLM reasoning lacks large-scale and well-structured training datasets. To bridge this gap, we propose VisualSphinx, a first-of-its-kind large-scale synthetic visual logical reasoning training data. To tackle the challenge of image synthesis with grounding answers, we propose a rule-to-image synthesis pipeline, which extracts and expands puzzle rules from seed questions and generates the code of grounding synthesis image synthesis for puzzle sample assembly. Experiments demonstrate that VLM trained using GRPO on VisualSphinx benefit from logical coherence and readability of our dataset and exhibit improved performance on logical reasoning tasks. The enhanced reasoning capabilities developed from VisualSphinx also benefit other reasoning tasks such as algebraic reasoning, arithmetic reasoning and geometry reasoning.
Temporal Sampling for Forgotten Reasoning in LLMs
May 26, 2025Fine-tuning large language models (LLMs) is intended to improve their reasoning capabilities, yet we uncover a counterintuitive effect: models often forget how to solve problems they previously answered correctly during training. We term this phenomenon temporal forgetting and show that it is widespread across model sizes, fine-tuning methods (both Reinforcement Learning and Supervised Fine-Tuning), and multiple reasoning benchmarks. To address this gap, we introduce Temporal Sampling, a simple decoding strategy that draws outputs from multiple checkpoints along the training trajectory. This approach recovers forgotten solutions without retraining or ensembling, and leads to substantial improvements in reasoning performance, gains from 4 to 19 points in Pass@k and consistent gains in Majority@k across several benchmarks. We further extend our method to LoRA-adapted models, demonstrating that storing only adapter weights across checkpoints achieves similar benefits with minimal storage cost. By leveraging the temporal diversity inherent in training, Temporal Sampling offers a practical, compute-efficient way to surface hidden reasoning ability and rethink how we evaluate LLMs.
TinyV: Reducing False Negatives in Verification Improves RL for LLM Reasoning
May 20, 2025Reinforcement Learning (RL) has become a powerful tool for enhancing the reasoning abilities of large language models (LLMs) by optimizing their policies with reward signals. Yet, RL's success relies on the reliability of rewards, which are provided by verifiers. In this paper, we expose and analyze a widespread problem--false negatives--where verifiers wrongly reject correct model outputs. Our in-depth study of the Big-Math-RL-Verified dataset reveals that over 38% of model-generated responses suffer from false negatives, where the verifier fails to recognize correct answers. We show, both empirically and theoretically, that these false negatives severely impair RL training by depriving the model of informative gradient signals and slowing convergence. To mitigate this, we propose tinyV, a lightweight LLM-based verifier that augments existing rule-based methods, which dynamically identifies potential false negatives and recovers valid responses to produce more accurate reward estimates. Across multiple math-reasoning benchmarks, integrating TinyV boosts pass rates by up to 10% and accelerates convergence relative to the baseline. Our findings highlight the critical importance of addressing verifier false negatives and offer a practical approach to improve RL-based fine-tuning of LLMs. Our code is available at https://github.com/uw-nsl/TinyV.
CrossWordBench: Evaluating the Reasoning Capabilities of LLMs and LVLMs with Controllable Puzzle Generation
Mar 30, 2025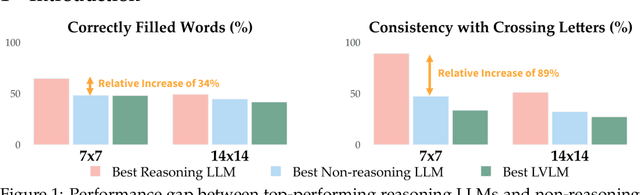
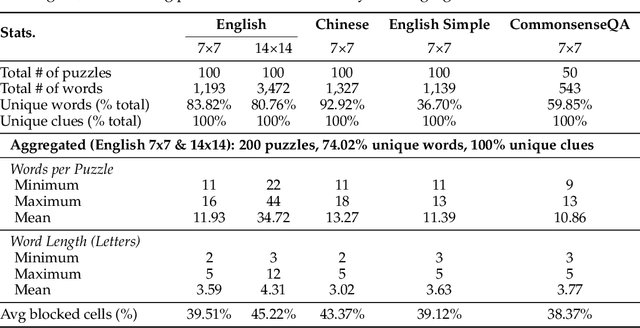
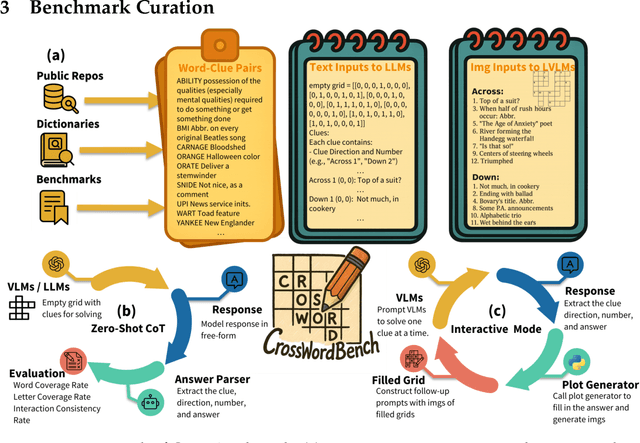
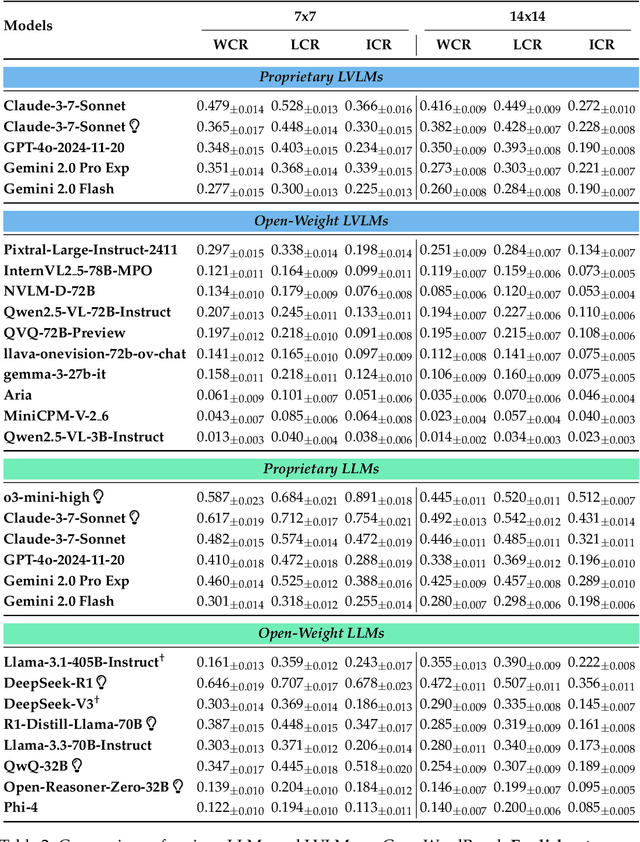
Existing reasoning evaluation frameworks for Large Language Models (LLMs) and Large Vision-Language Models (LVLMs) predominantly either assess text-based reasoning or vision-language understanding capabilities, with limited dynamic interplay between textual and visual constraints. To address this limitation, we introduce CrossWordBench, a benchmark designed to evaluate the reasoning capabilities of both LLMs and LVLMs through the medium of crossword puzzles-a task requiring multimodal adherence to semantic constraints from text-based clues and intersectional constraints from visual grid structures. CrossWordBench leverages a controllable puzzle generation framework that produces puzzles in multiple formats (text and image) and offers different evaluation strategies ranging from direct puzzle solving to interactive modes. Our extensive evaluation of over 20 models reveals that reasoning LLMs outperform non-reasoning models substantially by effectively leveraging crossing-letter constraints. We further demonstrate that LVLMs struggle with the task, showing a strong correlation between their puzzle-solving performance and grid-parsing accuracy. Our findings offer insights into the limitations of the reasoning capabilities of current LLMs and LVLMs, and provide an effective approach for creating multimodal constrained tasks for future evaluations.
SafeChain: Safety of Language Models with Long Chain-of-Thought Reasoning Capabilities
Feb 17, 2025



Emerging large reasoning models (LRMs), such as DeepSeek-R1 models, leverage long chain-of-thought (CoT) reasoning to generate structured intermediate steps, enhancing their reasoning capabilities. However, long CoT does not inherently guarantee safe outputs, potentially leading to harmful consequences such as the introduction of security vulnerabilities in code or the spread of misinformation. Current research on large language model (LLM) safety usually focuses on short-answer responses, overlooking the long CoT style outputs of LRMs. To bridge this gap, we conduct a systematic study of LRM safety. First, we investigate safety evaluators calibrated against human annotations. Using our newly developed metrics, we thoroughly assess the safety of 12 state-of-the-art LRMs on StrongReject and WildJailbreak datasets. Our results show that LRMs are not safe compared to their reasoning advance. Further, we perform a fine-grained analysis of the reasoning trace and final answer. We find that three decoding strategies-ZeroThink, LessThink, and MoreThink-can improve model safety without additional training. However, these strategies either use constrained reasoning traces or incur high inference costs. To better strengthen LRM safety, we introduce SafeChain, the first-of-its-kind safety training dataset in CoT style. We fine-tune two LRMs with SafeChain, showing that it not only enhances model safety but also preserves performance across 6 reasoning benchmarks.
Small Models Struggle to Learn from Strong Reasoners
Feb 17, 2025



Large language models (LLMs) excel in complex reasoning tasks, and distilling their reasoning capabilities into smaller models has shown promise. However, we uncover an interesting phenomenon, which we term the Small Model Learnability Gap: small models ($\leq$3B parameters) do not consistently benefit from long chain-of-thought (CoT) reasoning or distillation from larger models. Instead, they perform better when fine-tuned on shorter, simpler reasoning chains that better align with their intrinsic learning capacity. To address this, we propose Mix Distillation, a simple yet effective strategy that balances reasoning complexity by combining long and short CoT examples or reasoning from both larger and smaller models. Our experiments demonstrate that Mix Distillation significantly improves small model reasoning performance compared to training on either data alone. These findings highlight the limitations of direct strong model distillation and underscore the importance of adapting reasoning complexity for effective reasoning capability transfer.
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning
Feb 03, 2025



We investigate the logical reasoning capabilities of large language models (LLMs) and their scalability in complex non-monotonic reasoning. To this end, we introduce ZebraLogic, a comprehensive evaluation framework for assessing LLM reasoning performance on logic grid puzzles derived from constraint satisfaction problems (CSPs). ZebraLogic enables the generation of puzzles with controllable and quantifiable complexity, facilitating a systematic study of the scaling limits of models such as Llama, o1 models, and DeepSeek-R1. By encompassing a broad range of search space complexities and diverse logical constraints, ZebraLogic provides a structured environment to evaluate reasoning under increasing difficulty. Our results reveal a significant decline in accuracy as problem complexity grows -- a phenomenon we term the curse of complexity. This limitation persists even with larger models and increased inference-time computation, suggesting inherent constraints in current LLM reasoning capabilities. Additionally, we explore strategies to enhance logical reasoning, including Best-of-N sampling, backtracking mechanisms, and self-verification prompts. Our findings offer critical insights into the scalability of LLM reasoning, highlight fundamental limitations, and outline potential directions for improvement.
VLRewardBench: A Challenging Benchmark for Vision-Language Generative Reward Models
Nov 26, 2024



Vision-language generative reward models (VL-GenRMs) play a crucial role in aligning and evaluating multimodal AI systems, yet their own evaluation remains under-explored. Current assessment methods primarily rely on AI-annotated preference labels from traditional VL tasks, which can introduce biases and often fail to effectively challenge state-of-the-art models. To address these limitations, we introduce VL-RewardBench, a comprehensive benchmark spanning general multimodal queries, visual hallucination detection, and complex reasoning tasks. Through our AI-assisted annotation pipeline combining sample selection with human verification, we curate 1,250 high-quality examples specifically designed to probe model limitations. Comprehensive evaluation across 16 leading large vision-language models, demonstrates VL-RewardBench's effectiveness as a challenging testbed, where even GPT-4o achieves only 65.4% accuracy, and state-of-the-art open-source models such as Qwen2-VL-72B, struggle to surpass random-guessing. Importantly, performance on VL-RewardBench strongly correlates (Pearson's r > 0.9) with MMMU-Pro accuracy using Best-of-N sampling with VL-GenRMs. Analysis experiments uncover three critical insights for improving VL-GenRMs: (i) models predominantly fail at basic visual perception tasks rather than reasoning tasks; (ii) inference-time scaling benefits vary dramatically by model capacity; and (iii) training VL-GenRMs to learn to judge substantially boosts judgment capability (+14.7% accuracy for a 7B VL-GenRM). We believe VL-RewardBench along with the experimental insights will become a valuable resource for advancing VL-GenRMs.
Stronger Models are NOT Stronger Teachers for Instruction Tuning
Nov 12, 2024



Instruction tuning has been widely adopted to ensure large language models (LLMs) follow user instructions effectively. The resulting instruction-following capabilities of LLMs heavily rely on the instruction datasets used for tuning. Recently, synthetic instruction datasets have emerged as an economically viable solution to provide LLMs diverse and high-quality instructions. However, existing approaches typically assume that larger or stronger models are stronger teachers for instruction tuning, and hence simply adopt these models as response generators to the synthetic instructions. In this paper, we challenge this commonly-adopted assumption. Our extensive experiments across five base models and twenty response generators reveal that larger and stronger models are not necessarily stronger teachers of smaller models. We refer to this phenomenon as the Larger Models' Paradox. We observe that existing metrics cannot precisely predict the effectiveness of response generators since they ignore the compatibility between teachers and base models being fine-tuned. We thus develop a novel metric, named as Compatibility-Adjusted Reward (CAR) to measure the effectiveness of response generators. Our experiments across five base models demonstrate that CAR outperforms almost all baselines.
On Memorization of Large Language Models in Logical Reasoning
Oct 30, 2024



Large language models (LLMs) achieve good performance on challenging reasoning benchmarks, yet could also make basic reasoning mistakes. This contrasting behavior is puzzling when it comes to understanding the mechanisms behind LLMs' reasoning capabilities. One hypothesis is that the increasingly high and nearly saturated performance on common reasoning benchmarks could be due to the memorization of similar problems. In this paper, we systematically investigate this hypothesis with a quantitative measurement of memorization in reasoning tasks, using a dynamically generated logical reasoning benchmark based on Knights and Knaves (K&K) puzzles. We found that LLMs could interpolate the training puzzles (achieving near-perfect accuracy) after fine-tuning, yet fail when those puzzles are slightly perturbed, suggesting that the models heavily rely on memorization to solve those training puzzles. On the other hand, we show that while fine-tuning leads to heavy memorization, it also consistently improves generalization performance. In-depth analyses with perturbation tests, cross difficulty-level transferability, probing model internals, and fine-tuning with wrong answers suggest that the LLMs learn to reason on K&K puzzles despite training data memorization. This phenomenon indicates that LLMs exhibit a complex interplay between memorization and genuine reasoning abilities. Finally, our analysis with per-sample memorization score sheds light on how LLMs switch between reasoning and memorization in solving logical puzzles. Our code and data are available at https://memkklogic.github.io.