 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement World Model Learning for LLM-based Agents
Feb 05, 2026Large language models (LLMs) have achieved strong performance in language-centric tasks. However, in agentic settings, LLMs often struggle to anticipate action consequences and adapt to environment dynamics, highlighting the need for world-modeling capabilities in LLM-based agents. We propose Reinforcement World Model Learning (RWML), a self-supervised method that learns action-conditioned world models for LLM-based agents on textual states using sim-to-real gap rewards. Our method aligns simulated next states produced by the model with realized next states observed from the environment, encouraging consistency between internal world simulations and actual environment dynamics in a pre-trained embedding space. Unlike next-state token prediction, which prioritizes token-level fidelity (i.e., reproducing exact wording) over semantic equivalence and can lead to model collapse, our method provides a more robust training signal and is empirically less susceptible to reward hacking than LLM-as-a-judge. We evaluate our method on ALFWorld and $τ^2$ Bench and observe significant gains over the base model, despite being entirely self-supervised. When combined with task-success rewards, our method outperforms direct task-success reward RL by 6.9 and 5.7 points on ALFWorld and $τ^2$ Bench respectively, while matching the performance of expert-data training.
Adapting Web Agents with Synthetic Supervision
Nov 08, 2025Web agents struggle to adapt to new websites due to the scarcity of environment specific tasks and demonstrations. Recent works have explored synthetic data generation to address this challenge, however, they suffer from data quality issues where synthesized tasks contain hallucinations that cannot be executed, and collected trajectories are noisy with redundant or misaligned actions. In this paper, we propose SynthAgent, a fully synthetic supervision framework that aims at improving synthetic data quality via dual refinement of both tasks and trajectories. Our approach begins by synthesizing diverse tasks through categorized exploration of web elements, ensuring efficient coverage of the target environment. During trajectory collection, we refine tasks when conflicts with actual observations are detected, mitigating hallucinations while maintaining task consistency. After collection, we conduct trajectory refinement with a global context to mitigate potential noise or misalignments. Finally, we fine-tune open-source web agents on the refined synthetic data to adapt them to the target environment. Experimental results demonstrate that SynthAgent outperforms existing synthetic data methods, validating the importance of high-quality synthetic supervision. The code will be publicly available at https://github.com/aiming-lab/SynthAgent.
Dyna-Mind: Learning to Simulate from Experience for Better AI Agents
Oct 10, 2025



Reasoning models have recently shown remarkable progress in domains such as math and coding. However, their expert-level abilities in math and coding contrast sharply with their performance in long-horizon, interactive tasks such as web navigation and computer/phone-use. Inspired by literature on human cognition, we argue that current AI agents need ''vicarious trial and error'' - the capacity to mentally simulate alternative futures before acting - in order to enhance their understanding and performance in complex interactive environments. We introduce Dyna-Mind, a two-stage training framework that explicitly teaches (V)LM agents to integrate such simulation into their reasoning. In stage 1, we introduce Reasoning with Simulations (ReSim), which trains the agent to generate structured reasoning traces from expanded search trees built from real experience gathered through environment interactions. ReSim thus grounds the agent's reasoning in faithful world dynamics and equips it with the ability to anticipate future states in its reasoning. In stage 2, we propose Dyna-GRPO, an online reinforcement learning method to further strengthen the agent's simulation and decision-making ability by using both outcome rewards and intermediate states as feedback from real rollouts. Experiments on two synthetic benchmarks (Sokoban and ALFWorld) and one realistic benchmark (AndroidWorld) demonstrate that (1) ReSim effectively infuses simulation ability into AI agents, and (2) Dyna-GRPO leverages outcome and interaction-level signals to learn better policies for long-horizon, planning-intensive tasks. Together, these results highlight the central role of simulation in enabling AI agents to reason, plan, and act more effectively in the ever more challenging environments.
Decoder-Hybrid-Decoder Architecture for Efficient Reasoning with Long Generation
Jul 09, 2025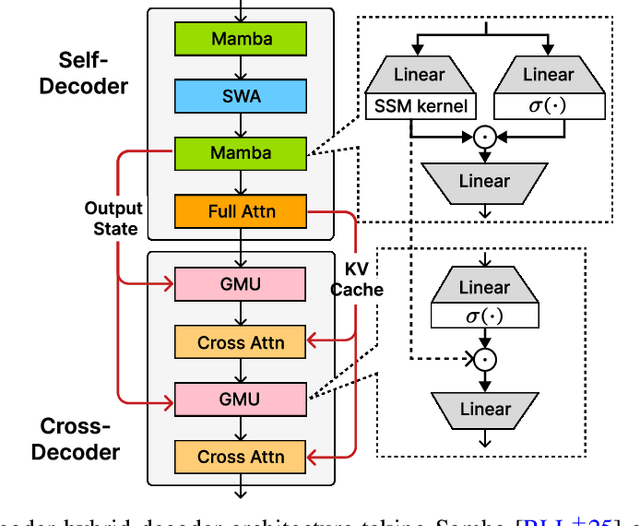
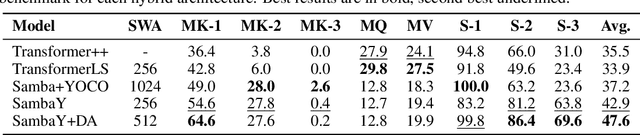
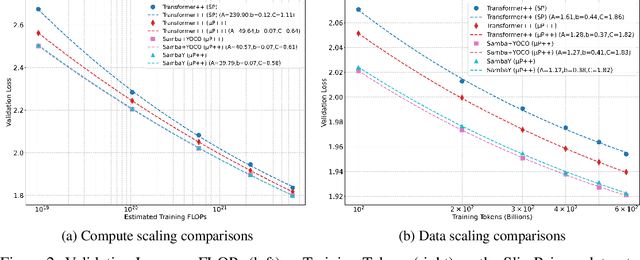
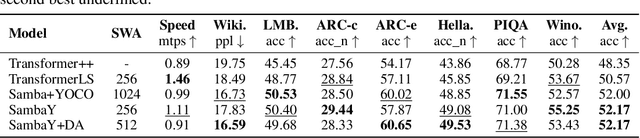
Recent advances in language modeling have demonstrated the effectiveness of State Space Models (SSMs) for efficient sequence modeling. While hybrid architectures such as Samba and the decoder-decoder architecture, YOCO, have shown promising performance gains over Transformers, prior works have not investigated the efficiency potential of representation sharing between SSM layers. In this paper, we introduce the Gated Memory Unit (GMU), a simple yet effective mechanism for efficient memory sharing across layers. We apply it to create SambaY, a decoder-hybrid-decoder architecture that incorporates GMUs in the cross-decoder to share memory readout states from a Samba-based self-decoder. SambaY significantly enhances decoding efficiency, preserves linear pre-filling time complexity, and boosts long-context performance, all while eliminating the need for explicit positional encoding. Through extensive scaling experiments, we demonstrate that our model exhibits a significantly lower irreducible loss compared to a strong YOCO baseline, indicating superior performance scalability under large-scale compute regimes. Our largest model enhanced with Differential Attention, Phi4-mini-Flash-Reasoning, achieves significantly better performance than Phi4-mini-Reasoning on reasoning tasks such as Math500, AIME24/25, and GPQA Diamond without any reinforcement learning, while delivering up to 10x higher decoding throughput on 2K-length prompts with 32K generation length under the vLLM inference framework. We release our training codebase on open-source data at https://github.com/microsoft/ArchScale.
Phi-4-Mini-Reasoning: Exploring the Limits of Small Reasoning Language Models in Math
Apr 30, 2025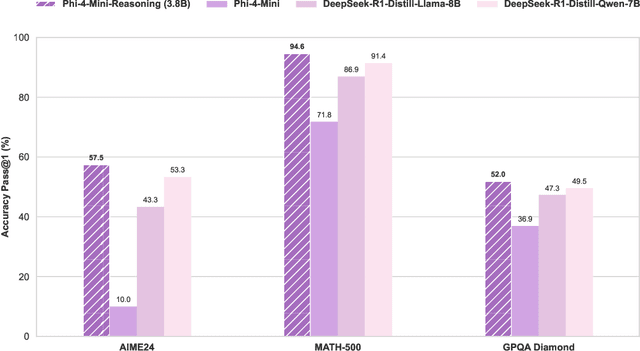
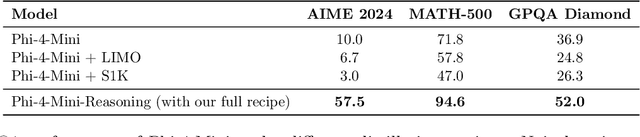

Chain-of-Thought (CoT) significantly enhances formal reasoning capabilities in Large Language Models (LLMs) by training them to explicitly generate intermediate reasoning steps. While LLMs readily benefit from such techniques, improving reasoning in Small Language Models (SLMs) remains challenging due to their limited model capacity. Recent work by Deepseek-R1 demonstrates that distillation from LLM-generated synthetic data can substantially improve the reasoning ability of SLM. However, the detailed modeling recipe is not disclosed. In this work, we present a systematic training recipe for SLMs that consists of four steps: (1) large-scale mid-training on diverse distilled long-CoT data, (2) supervised fine-tuning on high-quality long-CoT data, (3) Rollout DPO leveraging a carefully curated preference dataset, and (4) Reinforcement Learning (RL) with Verifiable Reward. We apply our method on Phi-4-Mini, a compact 3.8B-parameter model. The resulting Phi-4-Mini-Reasoning model exceeds, on math reasoning tasks, much larger reasoning models, e.g., outperforming DeepSeek-R1-Distill-Qwen-7B by 3.2 points and DeepSeek-R1-Distill-Llama-8B by 7.7 points on Math-500. Our results validate that a carefully designed training recipe, with large-scale high-quality CoT data, is effective to unlock strong reasoning capabilities even in resource-constrained small models.
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Apr 29, 2025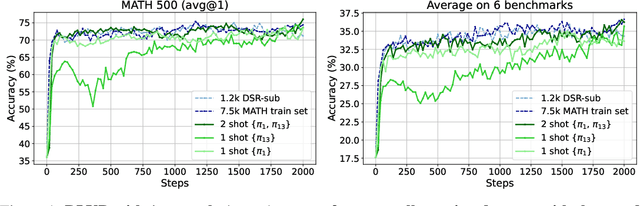
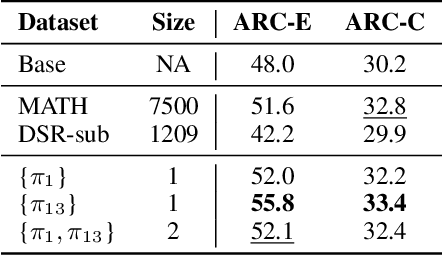
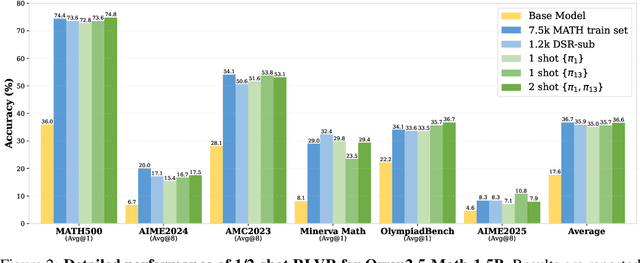

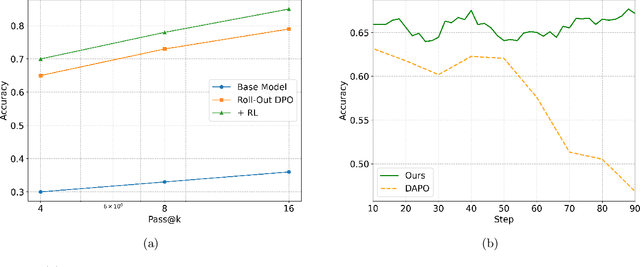
We show that reinforcement learning with verifiable reward using one training example (1-shot RLVR) is effective in incentivizing the math reasoning capabilities of large language models (LLMs). Applying RLVR to the base model Qwen2.5-Math-1.5B, we identify a single example that elevates model performance on MATH500 from 36.0% to 73.6%, and improves the average performance across six common mathematical reasoning benchmarks from 17.6% to 35.7%. This result matches the performance obtained using the 1.2k DeepScaleR subset (MATH500: 73.6%, average: 35.9%), which includes the aforementioned example. Similar substantial improvements are observed across various models (Qwen2.5-Math-7B, Llama3.2-3B-Instruct, DeepSeek-R1-Distill-Qwen-1.5B), RL algorithms (GRPO and PPO), and different math examples (many of which yield approximately 30% or greater improvement on MATH500 when employed as a single training example). In addition, we identify some interesting phenomena during 1-shot RLVR, including cross-domain generalization, increased frequency of self-reflection, and sustained test performance improvement even after the training accuracy has saturated, a phenomenon we term post-saturation generalization. Moreover, we verify that the effectiveness of 1-shot RLVR primarily arises from the policy gradient loss, distinguishing it from the "grokking" phenomenon. We also show the critical role of promoting exploration (e.g., by adding entropy loss with an appropriate coefficient) in 1-shot RLVR training. As a bonus, we observe that applying entropy loss alone, without any outcome reward, significantly enhances Qwen2.5-Math-1.5B's performance on MATH500 by 27.4%. These findings can inspire future work on RLVR data efficiency and encourage a re-examination of both recent progress and the underlying mechanisms in RLVR. Our code, model, and data are open source at https://github.com/ypwang61/One-Shot-RLVR
Magma: A Foundation Model for Multimodal AI Agents
Feb 18, 2025We present Magma, a foundation model that serves multimodal AI agentic tasks in both the digital and physical worlds. Magma is a significant extension of vision-language (VL) models in that it not only retains the VL understanding ability (verbal intelligence) of the latter, but is also equipped with the ability to plan and act in the visual-spatial world (spatial-temporal intelligence) and complete agentic tasks ranging from UI navigation to robot manipulation. To endow the agentic capabilities, Magma is pretrained on large amounts of heterogeneous datasets spanning from images, videos to robotics data, where the actionable visual objects (e.g., clickable buttons in GUI) in images are labeled by Set-of-Mark (SoM) for action grounding, and the object movements (e.g., the trace of human hands or robotic arms) in videos are labeled by Trace-of-Mark (ToM) for action planning. Extensive experiments show that SoM and ToM reach great synergy and facilitate the acquisition of spatial-temporal intelligence for our Magma model, which is fundamental to a wide range of tasks as shown in Fig.1. In particular, Magma creates new state-of-the-art results on UI navigation and robotic manipulation tasks, outperforming previous models that are specifically tailored to these tasks. On image and video-related multimodal tasks, Magma also compares favorably to popular large multimodal models that are trained on much larger datasets. We make our model and code public for reproducibility at https://microsoft.github.io/Magma.
On the Emergence of Thinking in LLMs I: Searching for the Right Intuition
Feb 10, 2025



Recent AI advancements, such as OpenAI's new models, are transforming LLMs into LRMs (Large Reasoning Models) that perform reasoning during inference, taking extra time and compute for higher-quality outputs. We aim to uncover the algorithmic framework for training LRMs. Methods like self-consistency, PRM, and AlphaZero suggest reasoning as guided search. We ask: what is the simplest, most scalable way to enable search in LLMs? We propose a post-training framework called Reinforcement Learning via Self-Play (RLSP). RLSP involves three steps: (1) supervised fine-tuning with human or synthetic demonstrations of the reasoning process, (2) using an exploration reward signal to encourage diverse and efficient reasoning behaviors, and (3) RL training with an outcome verifier to ensure correctness while preventing reward hacking. Our key innovation is to decouple exploration and correctness signals during PPO training, carefully balancing them to improve performance and efficiency. Empirical studies in the math domain show that RLSP improves reasoning. On the Llama-3.1-8B-Instruct model, RLSP can boost performance by 23% in MATH-500 test set; On AIME 2024 math problems, Qwen2.5-32B-Instruct improved by 10% due to RLSP. However, a more important finding of this work is that the models trained using RLSP, even with the simplest exploration reward that encourages the model to take more intermediate steps, showed several emergent behaviors such as backtracking, exploration of ideas, and verification. These findings demonstrate that RLSP framework might be enough to enable emergence of complex reasoning abilities in LLMs when scaled. Lastly, we propose a theory as to why RLSP search strategy is more suitable for LLMs inspired by a remarkable result that says CoT provably increases computational power of LLMs, which grows as the number of steps in CoT \cite{li2024chain,merrill2023expresssive}.
Latent Action Pretraining from Videos
Oct 15, 2024



We introduce Latent Action Pretraining for general Action models (LAPA), an unsupervised method for pretraining Vision-Language-Action (VLA) models without ground-truth robot action labels. Existing Vision-Language-Action models require action labels typically collected by human teleoperators during pretraining, which significantly limits possible data sources and scale. In this work, we propose a method to learn from internet-scale videos that do not have robot action labels. We first train an action quantization model leveraging VQ-VAE-based objective to learn discrete latent actions between image frames, then pretrain a latent VLA model to predict these latent actions from observations and task descriptions, and finally finetune the VLA on small-scale robot manipulation data to map from latent to robot actions. Experimental results demonstrate that our method significantly outperforms existing techniques that train robot manipulation policies from large-scale videos. Furthermore, it outperforms the state-of-the-art VLA model trained with robotic action labels on real-world manipulation tasks that require language conditioning, generalization to unseen objects, and semantic generalization to unseen instructions. Training only on human manipulation videos also shows positive transfer, opening up the potential for leveraging web-scale data for robotics foundation model.
Teaching AI Agents to Search with Reflective-MCTS and Exploratory Learning
Oct 15, 2024
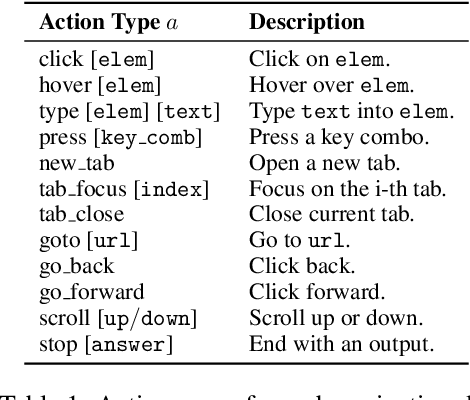
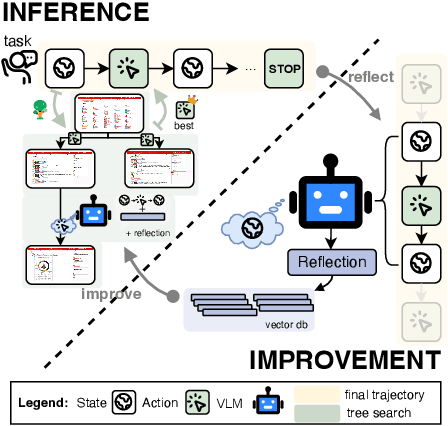
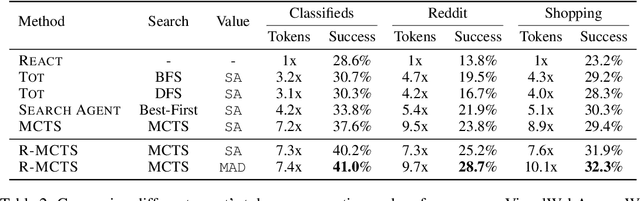
Autonomous agents have demonstrated significant potential in automating complex multistep decision-making tasks. However, even state-of-the-art vision-language models (VLMs), such as GPT-4o, still fall short of human-level performance, particularly in intricate web environments and long-horizon planning tasks. To address these limitations, we present Reflective Monte Carlo Tree Search (R-MCTS) and Exploratory Learning to build o1-like models for agentic applications. We first introduce R-MCTS, a novel test-time algorithm designed to enhance the ability of AI agents to explore decision space on the fly. R-MCTS extends traditional MCTS by 1) incorporating contrastive reflection, allowing agents to learn from past interactions and dynamically improve their search efficiency; and 2) using multi-agent debate to provide reliable state evaluation. Next, we introduce Exploratory Learning, a novel learning strategy to teach agents to search at inference time without relying on any external search algorithms. On the challenging VisualWebArena benchmark, our GPT-4o-based R-MCTS agent achieves a 6% to 30% relative improvement across various tasks compared to the previous state-of-the-art. Additionally, we show that the experience gained from test-time search can be effectively transferred back to GPT-4o via fine-tuning. After Exploratory Learning, GPT-4o 1) demonstrates the ability to explore the environment, evaluate a state, and backtrack to viable ones when it detects that the current state cannot lead to success, and 2) matches 87% of R-MCTS's performance while using significantly less compute. Notably, our work demonstrates the compute scaling properties in both training - data collection with R-MCTS - and testing time. These results suggest a promising research direction to enhance VLMs' reasoning and planning capabilities for agentic applications via test-time search and self-learning.