 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePADiff: Predictive and Adaptive Diffusion Policies for Ad Hoc Teamwork
Nov 10, 2025Ad hoc teamwork (AHT) requires agents to collaborate with previously unseen teammates, which is crucial for many real-world applications. The core challenge of AHT is to develop an ego agent that can predict and adapt to unknown teammates on the fly. Conventional RL-based approaches optimize a single expected return, which often causes policies to collapse into a single dominant behavior, thus failing to capture the multimodal cooperation patterns inherent in AHT. In this work, we introduce PADiff, a diffusion-based approach that captures agent's multimodal behaviors, unlocking its diverse cooperation modes with teammates. However, standard diffusion models lack the ability to predict and adapt in highly non-stationary AHT scenarios. To address this limitation, we propose a novel diffusion-based policy that integrates critical predictive information about teammates into the denoising process. Extensive experiments across three cooperation environments demonstrate that PADiff outperforms existing AHT methods significantly.
Pseudo-Asynchronous Local SGD: Robust and Efficient Data-Parallel Training
Apr 25, 2025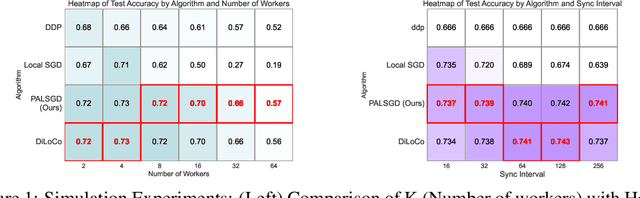
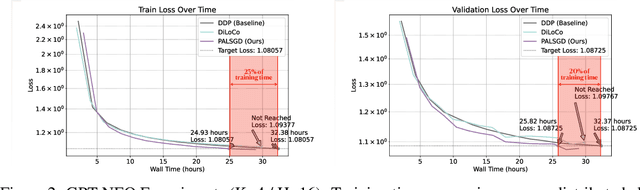
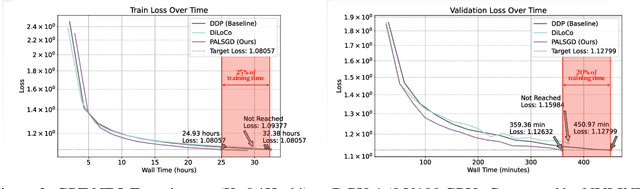
Following AI scaling trends, frontier models continue to grow in size and continue to be trained on larger datasets. Training these models requires huge investments in exascale computational resources, which has in turn driven development of distributed deep learning methods. Data parallelism is an essential approach to speed up training, but it requires frequent global communication between workers, which can bottleneck training at the largest scales. In this work, we propose a method called Pseudo-Asynchronous Local SGD (PALSGD) to improve the efficiency of data-parallel training. PALSGD is an extension of Local SGD (Stich, 2018) and DiLoCo (Douillard et al., 2023), designed to further reduce communication frequency by introducing a pseudo-synchronization mechanism. PALSGD allows the use of longer synchronization intervals compared to standard Local SGD. Despite the reduced communication frequency, the pseudo-synchronization approach ensures that model consistency is maintained, leading to performance results comparable to those achieved with more frequent synchronization. Furthermore, we provide a theoretical analysis of PALSGD, establishing its convergence and deriving its convergence rate. This analysis offers insights into the algorithm's behavior and performance guarantees. We evaluated PALSGD on image classification and language modeling tasks. Our results show that PALSGD achieves better performance in less time compared to existing methods like Distributed Data Parallel (DDP), and DiLoCo. Notably, PALSGD trains 18.4% faster than DDP on ImageNet-1K with ResNet-50, 24.4% faster than DDP on TinyStories with GPT-Neo125M, and 21.1% faster than DDP on TinyStories with GPT-Neo-8M.
On the Emergence of Thinking in LLMs I: Searching for the Right Intuition
Feb 10, 2025



Recent AI advancements, such as OpenAI's new models, are transforming LLMs into LRMs (Large Reasoning Models) that perform reasoning during inference, taking extra time and compute for higher-quality outputs. We aim to uncover the algorithmic framework for training LRMs. Methods like self-consistency, PRM, and AlphaZero suggest reasoning as guided search. We ask: what is the simplest, most scalable way to enable search in LLMs? We propose a post-training framework called Reinforcement Learning via Self-Play (RLSP). RLSP involves three steps: (1) supervised fine-tuning with human or synthetic demonstrations of the reasoning process, (2) using an exploration reward signal to encourage diverse and efficient reasoning behaviors, and (3) RL training with an outcome verifier to ensure correctness while preventing reward hacking. Our key innovation is to decouple exploration and correctness signals during PPO training, carefully balancing them to improve performance and efficiency. Empirical studies in the math domain show that RLSP improves reasoning. On the Llama-3.1-8B-Instruct model, RLSP can boost performance by 23% in MATH-500 test set; On AIME 2024 math problems, Qwen2.5-32B-Instruct improved by 10% due to RLSP. However, a more important finding of this work is that the models trained using RLSP, even with the simplest exploration reward that encourages the model to take more intermediate steps, showed several emergent behaviors such as backtracking, exploration of ideas, and verification. These findings demonstrate that RLSP framework might be enough to enable emergence of complex reasoning abilities in LLMs when scaled. Lastly, we propose a theory as to why RLSP search strategy is more suitable for LLMs inspired by a remarkable result that says CoT provably increases computational power of LLMs, which grows as the number of steps in CoT \cite{li2024chain,merrill2023expresssive}.
Generalizing Complex Hypotheses on Product Distributions: Auctions, Prophet Inequalities, and Pandora's Problem
Nov 27, 2019
This paper explores a theory of generalization for learning problems on product distributions, complementing the existing learning theories in the sense that it does not rely on any complexity measures of the hypothesis classes. The main contributions are two general sample complexity bounds: (1) $\tilde{O} \big( \frac{nk}{\epsilon^2} \big)$ samples are sufficient and necessary for learning an $\epsilon$-optimal hypothesis in any problem on an $n$-dimensional product distribution, whose marginals have finite supports of sizes at most $k$; (2) $\tilde{O} \big( \frac{n}{\epsilon^2} \big)$ samples are sufficient and necessary for any problem on $n$-dimensional product distributions if it satisfies a notion of strong monotonicity from the algorithmic game theory literature. As applications of these theories, we match the optimal sample complexity for single-parameter revenue maximization (Guo et al., STOC 2019), improve the state-of-the-art for multi-parameter revenue maximization (Gonczarowski and Weinberg, FOCS 2018) and prophet inequality (Correa et al., EC 2019), and provide the first and tight sample complexity bound for Pandora's problem.