 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Rubric-Based Benchmarking and Reinforcement Learning for Advancing LLM Instruction Following
Nov 13, 2025Recent progress in large language models (LLMs) has led to impressive performance on a range of tasks, yet advanced instruction following (IF)-especially for complex, multi-turn, and system-prompted instructions-remains a significant challenge. Rigorous evaluation and effective training for such capabilities are hindered by the lack of high-quality, human-annotated benchmarks and reliable, interpretable reward signals. In this work, we introduce AdvancedIF (we will release this benchmark soon), a comprehensive benchmark featuring over 1,600 prompts and expert-curated rubrics that assess LLMs ability to follow complex, multi-turn, and system-level instructions. We further propose RIFL (Rubric-based Instruction-Following Learning), a novel post-training pipeline that leverages rubric generation, a finetuned rubric verifier, and reward shaping to enable effective reinforcement learning for instruction following. Extensive experiments demonstrate that RIFL substantially improves the instruction-following abilities of LLMs, achieving a 6.7% absolute gain on AdvancedIF and strong results on public benchmarks. Our ablation studies confirm the effectiveness of each component in RIFL. This work establishes rubrics as a powerful tool for both training and evaluating advanced IF in LLMs, paving the way for more capable and reliable AI systems.
Which Agent Causes Task Failures and When? On Automated Failure Attribution of LLM Multi-Agent Systems
Apr 30, 2025
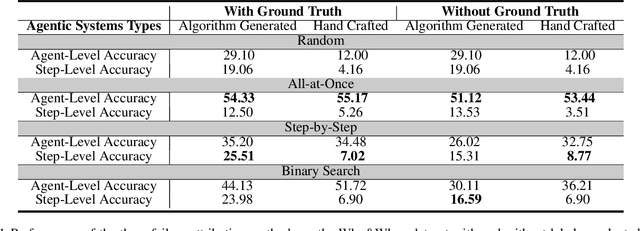
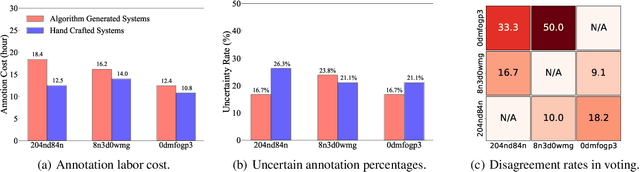

Failure attribution in LLM multi-agent systems-identifying the agent and step responsible for task failures-provides crucial clues for systems debugging but remains underexplored and labor-intensive. In this paper, we propose and formulate a new research area: automated failure attribution for LLM multi-agent systems. To support this initiative, we introduce the Who&When dataset, comprising extensive failure logs from 127 LLM multi-agent systems with fine-grained annotations linking failures to specific agents and decisive error steps. Using the Who&When, we develop and evaluate three automated failure attribution methods, summarizing their corresponding pros and cons. The best method achieves 53.5% accuracy in identifying failure-responsible agents but only 14.2% in pinpointing failure steps, with some methods performing below random. Even SOTA reasoning models, such as OpenAI o1 and DeepSeek R1, fail to achieve practical usability. These results highlight the task's complexity and the need for further research in this area. Code and dataset are available at https://github.com/mingyin1/Agents_Failure_Attribution
Alchemist: Towards the Design of Efficient Online Continual Learning System
Mar 03, 2025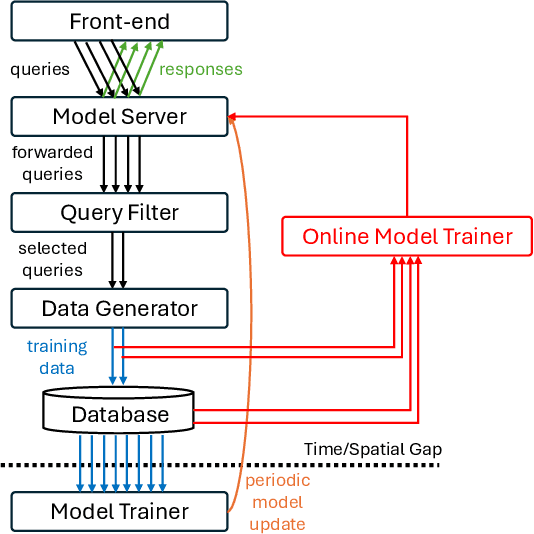
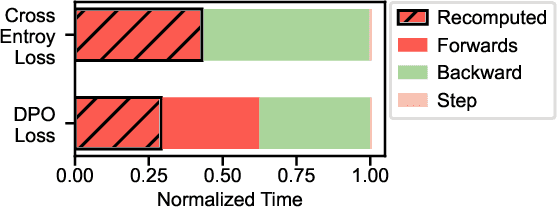
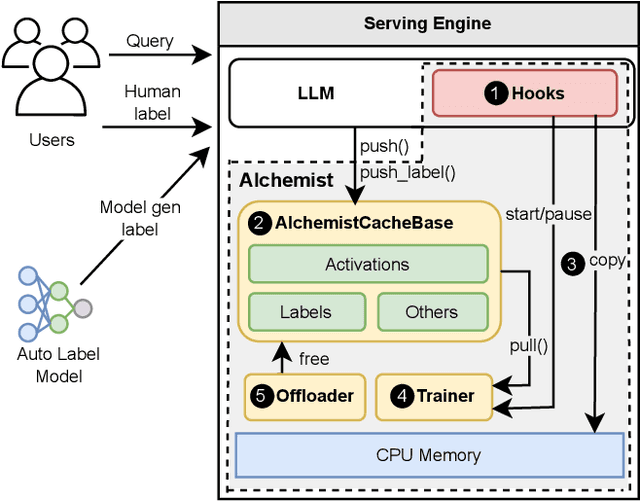
Continual learning has emerged as a promising solution to refine models incrementally by leveraging user feedback, thereby enhancing model performance in applications like code completion, personal assistants, and chat interfaces. In particular, online continual learning - iteratively training the model with small batches of user feedback - has demonstrated notable performance improvements. However, the existing practice of segregating training and serving processes forces the online trainer to recompute the intermediate results already done during serving. Such redundant computations can account for 30%-42% of total training time. In this paper, we propose Alchemist, to the best of our knowledge, the first online continual learning system that efficiently reuses intermediate results computed during serving to reduce redundant computation with minimal impact on the serving latency or capacity. Alchemist introduces two key techniques: (1) minimal activations recording and saving during serving, where activations are recorded and saved only during the prefill phase to minimize overhead; and (2) offloading of serving activations, which dynamically manages GPU memory by freeing activations in the forward order, while reloading them in the backward order during the backward pass. Evaluations with the ShareGPT dataset show that compared with a separate training cluster, Alchemist significantly increases training throughput by up to 1.72x, reduces up to 47% memory usage during training, and supports up to 2x more training tokens - all while maintaining negligible impact on serving latency.
PathFinder: A Multi-Modal Multi-Agent System for Medical Diagnostic Decision-Making Applied to Histopathology
Feb 13, 2025



Diagnosing diseases through histopathology whole slide images (WSIs) is fundamental in modern pathology but is challenged by the gigapixel scale and complexity of WSIs. Trained histopathologists overcome this challenge by navigating the WSI, looking for relevant patches, taking notes, and compiling them to produce a final holistic diagnostic. Traditional AI approaches, such as multiple instance learning and transformer-based models, fail short of such a holistic, iterative, multi-scale diagnostic procedure, limiting their adoption in the real-world. We introduce PathFinder, a multi-modal, multi-agent framework that emulates the decision-making process of expert pathologists. PathFinder integrates four AI agents, the Triage Agent, Navigation Agent, Description Agent, and Diagnosis Agent, that collaboratively navigate WSIs, gather evidence, and provide comprehensive diagnoses with natural language explanations. The Triage Agent classifies the WSI as benign or risky; if risky, the Navigation and Description Agents iteratively focus on significant regions, generating importance maps and descriptive insights of sampled patches. Finally, the Diagnosis Agent synthesizes the findings to determine the patient's diagnostic classification. Our Experiments show that PathFinder outperforms state-of-the-art methods in skin melanoma diagnosis by 8% while offering inherent explainability through natural language descriptions of diagnostically relevant patches. Qualitative analysis by pathologists shows that the Description Agent's outputs are of high quality and comparable to GPT-4o. PathFinder is also the first AI-based system to surpass the average performance of pathologists in this challenging melanoma classification task by 9%, setting a new record for efficient, accurate, and interpretable AI-assisted diagnostics in pathology. Data, code and models available at https://pathfinder-dx.github.io/
On the Emergence of Thinking in LLMs I: Searching for the Right Intuition
Feb 10, 2025



Recent AI advancements, such as OpenAI's new models, are transforming LLMs into LRMs (Large Reasoning Models) that perform reasoning during inference, taking extra time and compute for higher-quality outputs. We aim to uncover the algorithmic framework for training LRMs. Methods like self-consistency, PRM, and AlphaZero suggest reasoning as guided search. We ask: what is the simplest, most scalable way to enable search in LLMs? We propose a post-training framework called Reinforcement Learning via Self-Play (RLSP). RLSP involves three steps: (1) supervised fine-tuning with human or synthetic demonstrations of the reasoning process, (2) using an exploration reward signal to encourage diverse and efficient reasoning behaviors, and (3) RL training with an outcome verifier to ensure correctness while preventing reward hacking. Our key innovation is to decouple exploration and correctness signals during PPO training, carefully balancing them to improve performance and efficiency. Empirical studies in the math domain show that RLSP improves reasoning. On the Llama-3.1-8B-Instruct model, RLSP can boost performance by 23% in MATH-500 test set; On AIME 2024 math problems, Qwen2.5-32B-Instruct improved by 10% due to RLSP. However, a more important finding of this work is that the models trained using RLSP, even with the simplest exploration reward that encourages the model to take more intermediate steps, showed several emergent behaviors such as backtracking, exploration of ideas, and verification. These findings demonstrate that RLSP framework might be enough to enable emergence of complex reasoning abilities in LLMs when scaled. Lastly, we propose a theory as to why RLSP search strategy is more suitable for LLMs inspired by a remarkable result that says CoT provably increases computational power of LLMs, which grows as the number of steps in CoT \cite{li2024chain,merrill2023expresssive}.
Towards Safer Heuristics With XPlain
Oct 19, 2024



Many problems that cloud operators solve are computationally expensive, and operators often use heuristic algorithms (that are faster and scale better than optimal) to solve them more efficiently. Heuristic analyzers enable operators to find when and by how much their heuristics underperform. However, these tools do not provide enough detail for operators to mitigate the heuristic's impact in practice: they only discover a single input instance that causes the heuristic to underperform (and not the full set), and they do not explain why. We propose XPlain, a tool that extends these analyzers and helps operators understand when and why their heuristics underperform. We present promising initial results that show such an extension is viable.
Towards Foundation Models for Mixed Integer Linear Programming
Oct 10, 2024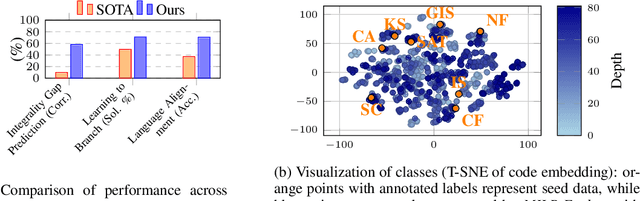

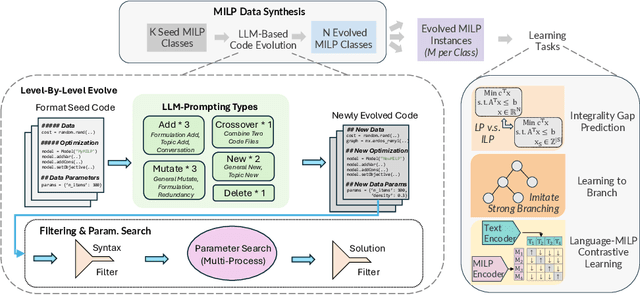
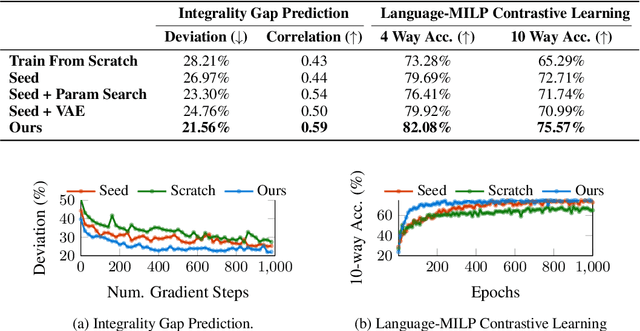
Mixed Integer Linear Programming (MILP) is essential for modeling complex decision-making problems but faces challenges in computational tractability and requires expert formulation. Current deep learning approaches for MILP focus on specific problem classes and do not generalize to unseen classes. To address this shortcoming, we take a foundation model training approach, where we train a single deep learning model on a diverse set of MILP problems to generalize across problem classes. As existing datasets for MILP lack diversity and volume, we introduce MILP-Evolve, a novel LLM-based evolutionary framework that is capable of generating a large set of diverse MILP classes with an unlimited amount of instances. We study our methodology on three key learning tasks that capture diverse aspects of MILP: (1) integrality gap prediction, (2) learning to branch, and (3) a new task of aligning MILP instances with natural language descriptions. Our empirical results show that models trained on the data generated by MILP-Evolve achieve significant improvements on unseen problems, including MIPLIB benchmarks. Our work highlights the potential of moving towards a foundation model approach for MILP that can generalize to a broad range of MILP applications. We are committed to fully open-sourcing our work to advance further research.
Small Language Models for Application Interactions: A Case Study
May 23, 2024



We study the efficacy of Small Language Models (SLMs) in facilitating application usage through natural language interactions. Our focus here is on a particular internal application used in Microsoft for cloud supply chain fulfilment. Our experiments show that small models can outperform much larger ones in terms of both accuracy and running time, even when fine-tuned on small datasets. Alongside these results, we also highlight SLM-based system design considerations.
Reflect-RL: Two-Player Online RL Fine-Tuning for LMs
Feb 20, 2024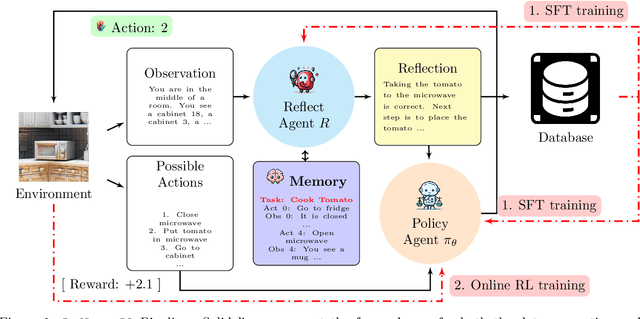
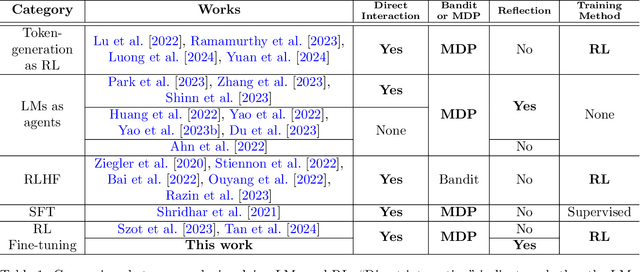
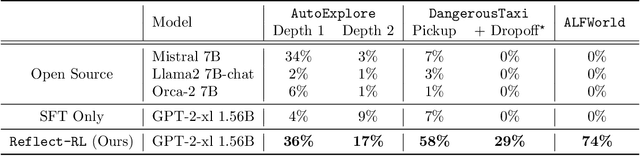
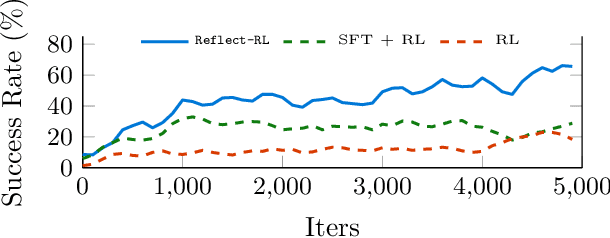
As language models (LMs) demonstrate their capabilities in various fields, their application to tasks requiring multi-round interactions has become increasingly popular. These tasks usually have complex dynamics, so supervised fine-tuning (SFT) on a limited offline dataset does not yield good performance. However, only a few works attempted to directly train the LMs within interactive decision-making environments. We aim to create an effective mechanism to fine-tune LMs with online reinforcement learning (RL) in these environments. We propose Reflect-RL, a two-player system to fine-tune an LM using online RL, where a frozen reflection model assists the policy model. To generate data for the warm-up SFT stage, we use negative example generation to enhance the error-correction ability of the reflection model. Furthermore, we designed single-prompt action enumeration and applied curriculum learning to allow the policy model to learn more efficiently. Empirically, we verify that Reflect-RL outperforms SFT and online RL without reflection. Testing results indicate GPT-2-xl after Reflect-RL also outperforms those of untuned pre-trained LMs, such as Mistral 7B.