 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReflect-RL: Two-Player Online RL Fine-Tuning for LMs
Paper and Code
Feb 20, 2024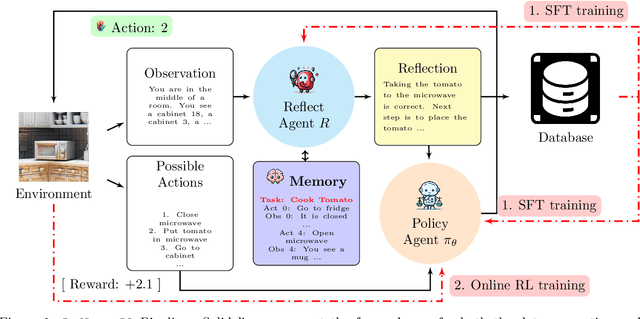
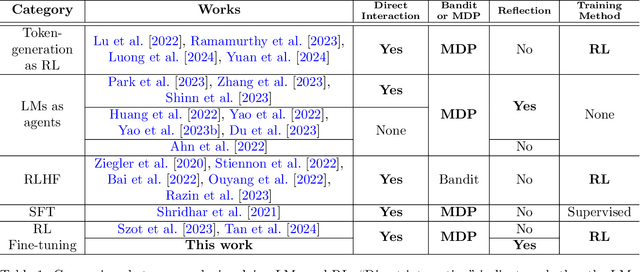
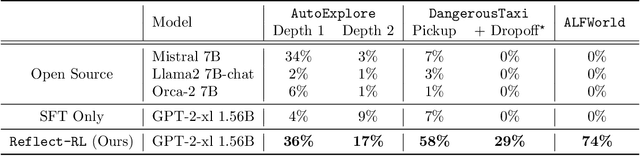
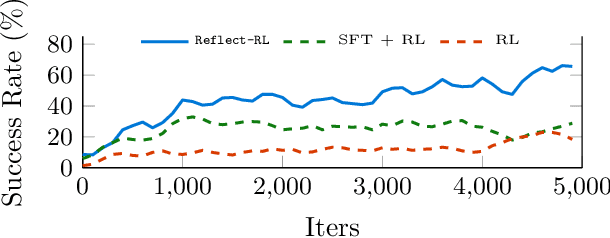
As language models (LMs) demonstrate their capabilities in various fields, their application to tasks requiring multi-round interactions has become increasingly popular. These tasks usually have complex dynamics, so supervised fine-tuning (SFT) on a limited offline dataset does not yield good performance. However, only a few works attempted to directly train the LMs within interactive decision-making environments. We aim to create an effective mechanism to fine-tune LMs with online reinforcement learning (RL) in these environments. We propose Reflect-RL, a two-player system to fine-tune an LM using online RL, where a frozen reflection model assists the policy model. To generate data for the warm-up SFT stage, we use negative example generation to enhance the error-correction ability of the reflection model. Furthermore, we designed single-prompt action enumeration and applied curriculum learning to allow the policy model to learn more efficiently. Empirically, we verify that Reflect-RL outperforms SFT and online RL without reflection. Testing results indicate GPT-2-xl after Reflect-RL also outperforms those of untuned pre-trained LMs, such as Mistral 7B.