 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnregularized Linear Convergence in Zero-Sum Game from Preference Feedback
Dec 31, 2025Aligning large language models (LLMs) with human preferences has proven effective for enhancing model capabilities, yet standard preference modeling using the Bradley-Terry model assumes transitivity, overlooking the inherent complexity of human population preferences. Nash learning from human feedback (NLHF) addresses this by framing non-transitive preferences as a two-player zero-sum game, where alignment reduces to finding the Nash equilibrium (NE). However, existing algorithms typically rely on regularization, incurring unavoidable bias when computing the duality gap in the original game. In this work, we provide the first convergence guarantee for Optimistic Multiplicative Weights Update ($\mathtt{OMWU}$) in NLHF, showing that it achieves last-iterate linear convergence after a burn-in phase whenever an NE with full support exists, with an instance-dependent linear convergence rate to the original NE, measured by duality gaps. Compared to prior results in Wei et al. (2020), we do not require the assumption of NE uniqueness. Our analysis identifies a novel marginal convergence behavior, where the probability of rarely played actions grows exponentially from exponentially small values, enabling exponentially better dependence on instance-dependent constants than prior results. Experiments corroborate the theoretical strengths of $\mathtt{OMWU}$ in both tabular and neural policy classes, demonstrating its potential for LLM applications.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025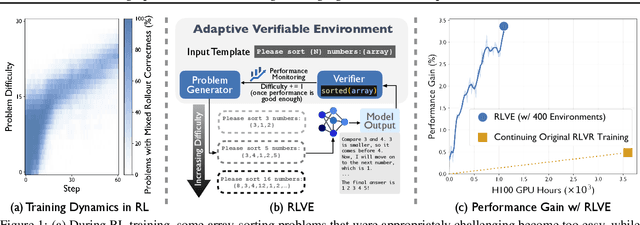

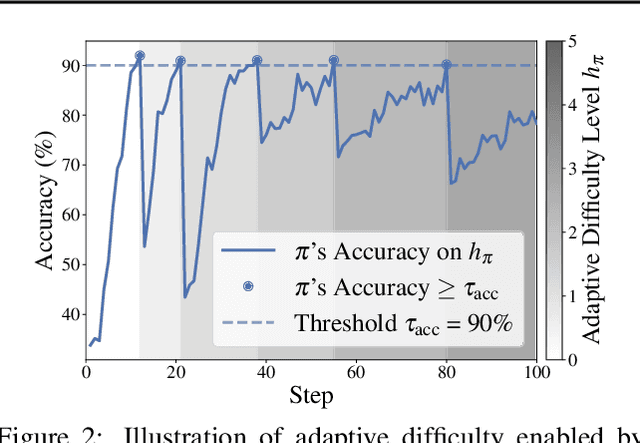
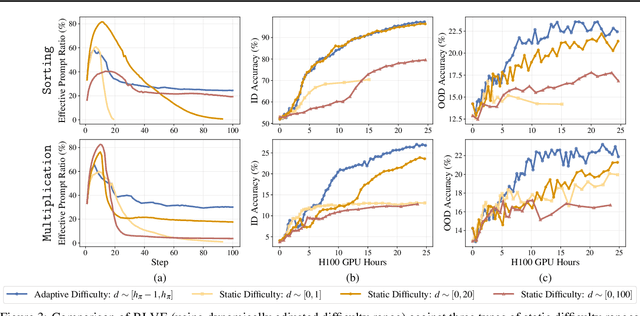
We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
The Ramon Llull's Thinking Machine for Automated Ideation
Aug 28, 2025This paper revisits Ramon Llull's Ars combinatoria - a medieval framework for generating knowledge through symbolic recombination - as a conceptual foundation for building a modern Llull's thinking machine for research ideation. Our approach defines three compositional axes: Theme (e.g., efficiency, adaptivity), Domain (e.g., question answering, machine translation), and Method (e.g., adversarial training, linear attention). These elements represent high-level abstractions common in scientific work - motivations, problem settings, and technical approaches - and serve as building blocks for LLM-driven exploration. We mine elements from human experts or conference papers and show that prompting LLMs with curated combinations produces research ideas that are diverse, relevant, and grounded in current literature. This modern thinking machine offers a lightweight, interpretable tool for augmenting scientific creativity and suggests a path toward collaborative ideation between humans and AI.
Sharp Gap-Dependent Variance-Aware Regret Bounds for Tabular MDPs
Jun 06, 2025We consider the gap-dependent regret bounds for episodic MDPs. We show that the Monotonic Value Propagation (MVP) algorithm achieves a variance-aware gap-dependent regret bound of $$\tilde{O}\left(\left(\sum_{\Delta_h(s,a)>0} \frac{H^2 \log K \land \mathtt{Var}_{\max}^{\text{c}}}{\Delta_h(s,a)} +\sum_{\Delta_h(s,a)=0}\frac{ H^2 \land \mathtt{Var}_{\max}^{\text{c}}}{\Delta_{\mathrm{min}}} + SAH^4 (S \lor H) \right) \log K\right),$$ where $H$ is the planning horizon, $S$ is the number of states, $A$ is the number of actions, and $K$ is the number of episodes. Here, $\Delta_h(s,a) =V_h^* (a) - Q_h^* (s, a)$ represents the suboptimality gap and $\Delta_{\mathrm{min}} := \min_{\Delta_h (s,a) > 0} \Delta_h(s,a)$. The term $\mathtt{Var}_{\max}^{\text{c}}$ denotes the maximum conditional total variance, calculated as the maximum over all $(\pi, h, s)$ tuples of the expected total variance under policy $\pi$ conditioned on trajectories visiting state $s$ at step $h$. $\mathtt{Var}_{\max}^{\text{c}}$ characterizes the maximum randomness encountered when learning any $(h, s)$ pair. Our result stems from a novel analysis of the weighted sum of the suboptimality gap and can be potentially adapted for other algorithms. To complement the study, we establish a lower bound of $$\Omega \left( \sum_{\Delta_h(s,a)>0} \frac{H^2 \land \mathtt{Var}_{\max}^{\text{c}}}{\Delta_h(s,a)}\cdot \log K\right),$$ demonstrating the necessity of dependence on $\mathtt{Var}_{\max}^{\text{c}}$ even when the maximum unconditional total variance (without conditioning on $(h, s)$) approaches zero.
Understanding the Performance Gap in Preference Learning: A Dichotomy of RLHF and DPO
May 26, 2025We present a fine-grained theoretical analysis of the performance gap between reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO) under a representation gap. Our study decomposes this gap into two sources: an explicit representation gap under exact optimization and an implicit representation gap under finite samples. In the exact optimization setting, we characterize how the relative capacities of the reward and policy model classes influence the final policy qualities. We show that RLHF, DPO, or online DPO can outperform one another depending on the type of model mis-specifications. Notably, online DPO can outperform both RLHF and standard DPO when the reward and policy model classes are isomorphic and both mis-specified. In the approximate optimization setting, we provide a concrete construction where the ground-truth reward is implicitly sparse and show that RLHF requires significantly fewer samples than DPO to recover an effective reward model -- highlighting a statistical advantage of two-stage learning. Together, these results provide a comprehensive understanding of the performance gap between RLHF and DPO under various settings, and offer practical insights into when each method is preferred.
CASCADE Your Datasets for Cross-Mode Knowledge Retrieval of Language Models
Apr 02, 2025Language models often struggle with cross-mode knowledge retrieval -- the ability to access knowledge learned in one format (mode) when queried in another. We demonstrate that models trained on multiple data sources (e.g., Wikipedia and TinyStories) exhibit significantly reduced accuracy when retrieving knowledge in a format different from its original training mode. This paper quantitatively investigates this phenomenon through a controlled study of random token sequence memorization across different modes. We first explore dataset rewriting as a solution, revealing that effective cross-mode retrieval requires prohibitively extensive rewriting efforts that follow a sigmoid-like relationship. As an alternative, we propose CASCADE, a novel pretraining algorithm that uses cascading datasets with varying sequence lengths to capture knowledge at different scales. Our experiments demonstrate that CASCADE outperforms dataset rewriting approaches, even when compressed into a single model with a unified loss function. This work provides both qualitative evidence of cross-mode retrieval limitations and a practical solution to enhance language models' ability to access knowledge independently of its presentational format.
Extragradient Preference Optimization (EGPO): Beyond Last-Iterate Convergence for Nash Learning from Human Feedback
Mar 11, 2025Reinforcement learning from human feedback (RLHF) has become essential for improving language model capabilities, but traditional approaches rely on the assumption that human preferences follow a transitive Bradley-Terry model. This assumption fails to capture the non-transitive nature of populational human preferences. Nash learning from human feedback (NLHF), targeting non-transitive preferences, is a problem of computing the Nash equilibrium (NE) of the two-player constant-sum game defined by the human preference. We introduce Extragradient preference optimization (EGPO), a novel algorithm for NLHF achieving last-iterate linear convergence to the NE of KL-regularized games and polynomial convergence to the NE of original games, while being robust to noise. Unlike previous approaches that rely on nested optimization, we derive an equivalent implementation using gradients of an online variant of the identity preference optimization (IPO) loss, enabling more faithful implementation for neural networks. Our empirical evaluations demonstrate EGPO's superior performance over baseline methods when training for the same number of epochs, as measured by pairwise win-rates using the ground truth preference. These results validate both the theoretical strengths and practical advantages of EGPO for language model alignment with non-transitive human preferences.
The Crucial Role of Samplers in Online Direct Preference Optimization
Sep 29, 2024



Direct Preference Optimization (DPO) has emerged as a stable, scalable, and efficient solution for language model alignment. Despite its empirical success, the $\textit{optimization}$ properties, particularly the impact of samplers on its convergence rates, remain underexplored. In this paper, we provide a rigorous analysis of DPO's $\textit{convergence rates}$ with different sampling strategies under the exact gradient setting, revealing a surprising separation: uniform sampling achieves $\textit{linear}$ convergence, while our proposed online sampler achieves $\textit{quadratic}$ convergence. We further adapt the sampler to practical settings by incorporating posterior distributions and $\textit{logit mixing}$, demonstrating significant improvements over previous approaches. On Safe-RLHF dataset, our method exhibits a $4.5$% improvement over vanilla DPO and a $3.0$% improvement over on-policy DPO; on Iterative-Prompt, our approach outperforms vanilla DPO, on-policy DPO, and Hybrid GSHF by over $4.2$%. Our results not only offer insights into the theoretical standing of DPO but also pave the way for potential algorithm designs in the future.
Multi-Agent Reinforcement Learning from Human Feedback: Data Coverage and Algorithmic Techniques
Sep 04, 2024



We initiate the study of Multi-Agent Reinforcement Learning from Human Feedback (MARLHF), exploring both theoretical foundations and empirical validations. We define the task as identifying Nash equilibrium from a preference-only offline dataset in general-sum games, a problem marked by the challenge of sparse feedback signals. Our theory establishes the upper complexity bounds for Nash Equilibrium in effective MARLHF, demonstrating that single-policy coverage is inadequate and highlighting the importance of unilateral dataset coverage. These theoretical insights are verified through comprehensive experiments. To enhance the practical performance, we further introduce two algorithmic techniques. (1) We propose a Mean Squared Error (MSE) regularization along the time axis to achieve a more uniform reward distribution and improve reward learning outcomes. (2) We utilize imitation learning to approximate the reference policy, ensuring stability and effectiveness in training. Our findings underscore the multifaceted approach required for MARLHF, paving the way for effective preference-based multi-agent systems.
Reflect-RL: Two-Player Online RL Fine-Tuning for LMs
Feb 20, 2024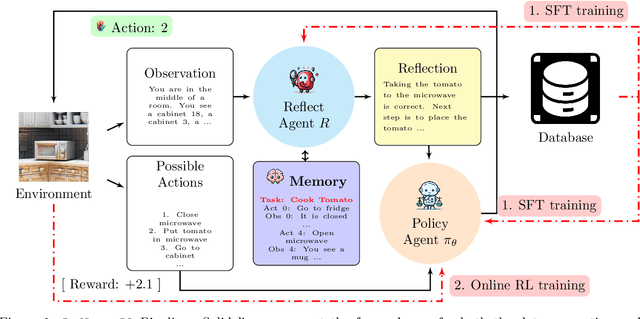
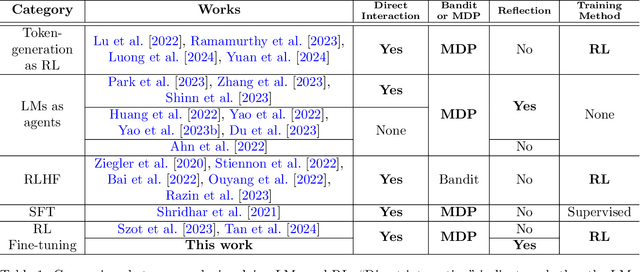
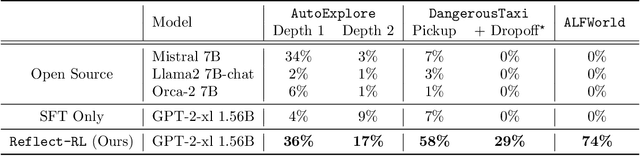
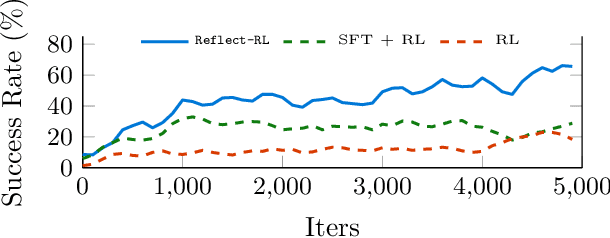
As language models (LMs) demonstrate their capabilities in various fields, their application to tasks requiring multi-round interactions has become increasingly popular. These tasks usually have complex dynamics, so supervised fine-tuning (SFT) on a limited offline dataset does not yield good performance. However, only a few works attempted to directly train the LMs within interactive decision-making environments. We aim to create an effective mechanism to fine-tune LMs with online reinforcement learning (RL) in these environments. We propose Reflect-RL, a two-player system to fine-tune an LM using online RL, where a frozen reflection model assists the policy model. To generate data for the warm-up SFT stage, we use negative example generation to enhance the error-correction ability of the reflection model. Furthermore, we designed single-prompt action enumeration and applied curriculum learning to allow the policy model to learn more efficiently. Empirically, we verify that Reflect-RL outperforms SFT and online RL without reflection. Testing results indicate GPT-2-xl after Reflect-RL also outperforms those of untuned pre-trained LMs, such as Mistral 7B.