 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Performance Gap in Preference Learning: A Dichotomy of RLHF and DPO
May 26, 2025We present a fine-grained theoretical analysis of the performance gap between reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO) under a representation gap. Our study decomposes this gap into two sources: an explicit representation gap under exact optimization and an implicit representation gap under finite samples. In the exact optimization setting, we characterize how the relative capacities of the reward and policy model classes influence the final policy qualities. We show that RLHF, DPO, or online DPO can outperform one another depending on the type of model mis-specifications. Notably, online DPO can outperform both RLHF and standard DPO when the reward and policy model classes are isomorphic and both mis-specified. In the approximate optimization setting, we provide a concrete construction where the ground-truth reward is implicitly sparse and show that RLHF requires significantly fewer samples than DPO to recover an effective reward model -- highlighting a statistical advantage of two-stage learning. Together, these results provide a comprehensive understanding of the performance gap between RLHF and DPO under various settings, and offer practical insights into when each method is preferred.
The Crucial Role of Samplers in Online Direct Preference Optimization
Sep 29, 2024



Direct Preference Optimization (DPO) has emerged as a stable, scalable, and efficient solution for language model alignment. Despite its empirical success, the $\textit{optimization}$ properties, particularly the impact of samplers on its convergence rates, remain underexplored. In this paper, we provide a rigorous analysis of DPO's $\textit{convergence rates}$ with different sampling strategies under the exact gradient setting, revealing a surprising separation: uniform sampling achieves $\textit{linear}$ convergence, while our proposed online sampler achieves $\textit{quadratic}$ convergence. We further adapt the sampler to practical settings by incorporating posterior distributions and $\textit{logit mixing}$, demonstrating significant improvements over previous approaches. On Safe-RLHF dataset, our method exhibits a $4.5$% improvement over vanilla DPO and a $3.0$% improvement over on-policy DPO; on Iterative-Prompt, our approach outperforms vanilla DPO, on-policy DPO, and Hybrid GSHF by over $4.2$%. Our results not only offer insights into the theoretical standing of DPO but also pave the way for potential algorithm designs in the future.
Decoding-Time Language Model Alignment with Multiple Objectives
Jun 27, 2024



Aligning language models (LMs) to human preferences has emerged as a critical pursuit, enabling these models to better serve diverse user needs. Existing methods primarily focus on optimizing LMs for a single reward function, limiting their adaptability to varied objectives. Here, we propose $\textbf{multi-objective decoding (MOD)}$, a decoding-time algorithm that outputs the next token from a linear combination of predictions of all base models, for any given weightings over different objectives. We exploit a common form among a family of $f$-divergence regularized alignment approaches (such as PPO, DPO, and their variants) to identify a closed-form solution by Legendre transform, and derive an efficient decoding strategy. Theoretically, we show why existing approaches can be sub-optimal even in natural settings and obtain optimality guarantees for our method. Empirical results demonstrate the effectiveness of the algorithm. For example, compared to a parameter-merging baseline, MOD achieves 12.8% overall reward improvement when equally optimizing towards $3$ objectives. Moreover, we experiment with MOD on combining three fully-finetuned LLMs of different model sizes, each aimed at different objectives such as safety, coding, and general user preference. Unlike traditional methods that require careful curation of a mixture of datasets to achieve comprehensive improvement, we can quickly experiment with preference weightings using MOD to find the best combination of models. Our best combination reduces toxicity on Toxigen to nearly 0% and achieves 7.9--33.3% improvement across other three metrics ($\textit{i.e.}$, Codex@1, GSM-COT, BBH-COT).
Rethinking Transformers in Solving POMDPs
May 30, 2024



Sequential decision-making algorithms such as reinforcement learning (RL) in real-world scenarios inevitably face environments with partial observability. This paper scrutinizes the effectiveness of a popular architecture, namely Transformers, in Partially Observable Markov Decision Processes (POMDPs) and reveals its theoretical limitations. We establish that regular languages, which Transformers struggle to model, are reducible to POMDPs. This poses a significant challenge for Transformers in learning POMDP-specific inductive biases, due to their lack of inherent recurrence found in other models like RNNs. This paper casts doubt on the prevalent belief in Transformers as sequence models for RL and proposes to introduce a point-wise recurrent structure. The Deep Linear Recurrent Unit (LRU) emerges as a well-suited alternative for Partially Observable RL, with empirical results highlighting the sub-optimal performance of the Transformer and considerable strength of LRU.
Unleashing the Power of Pre-trained Language Models for Offline Reinforcement Learning
Nov 07, 2023
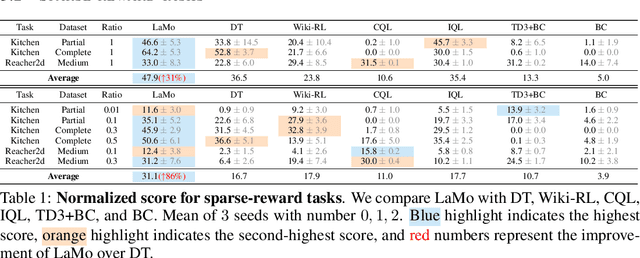
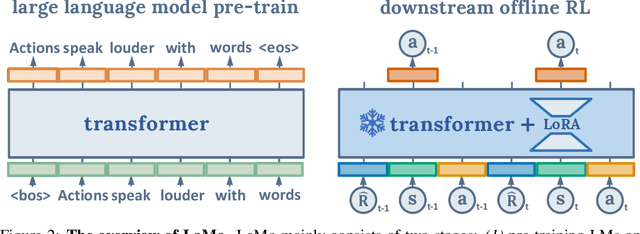
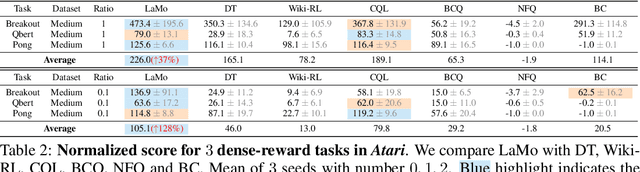
Offline reinforcement learning (RL) aims to find a near-optimal policy using pre-collected datasets. In real-world scenarios, data collection could be costly and risky; therefore, offline RL becomes particularly challenging when the in-domain data is limited. Given recent advances in Large Language Models (LLMs) and their few-shot learning prowess, this paper introduces $\textbf{La}$nguage Models for $\textbf{Mo}$tion Control ($\textbf{LaMo}$), a general framework based on Decision Transformers to effectively use pre-trained Language Models (LMs) for offline RL. Our framework highlights four crucial components: (1) Initializing Decision Transformers with sequentially pre-trained LMs, (2) employing the LoRA fine-tuning method, in contrast to full-weight fine-tuning, to combine the pre-trained knowledge from LMs and in-domain knowledge effectively, (3) using the non-linear MLP transformation instead of linear projections, to generate embeddings, and (4) integrating an auxiliary language prediction loss during fine-tuning to stabilize the LMs and retain their original abilities on languages. Empirical results indicate $\textbf{LaMo}$ achieves state-of-the-art performance in sparse-reward tasks and closes the gap between value-based offline RL methods and decision transformers in dense-reward tasks. In particular, our method demonstrates superior performance in scenarios with limited data samples. Our project website is $\href{https://lamo2023.github.io}{\text{this https URL}}$.
H-InDex: Visual Reinforcement Learning with Hand-Informed Representations for Dexterous Manipulation
Oct 13, 2023Human hands possess remarkable dexterity and have long served as a source of inspiration for robotic manipulation. In this work, we propose a human $\textbf{H}$and$\textbf{-In}$formed visual representation learning framework to solve difficult $\textbf{Dex}$terous manipulation tasks ($\textbf{H-InDex}$) with reinforcement learning. Our framework consists of three stages: (i) pre-training representations with 3D human hand pose estimation, (ii) offline adapting representations with self-supervised keypoint detection, and (iii) reinforcement learning with exponential moving average BatchNorm. The last two stages only modify $0.36\%$ parameters of the pre-trained representation in total, ensuring the knowledge from pre-training is maintained to the full extent. We empirically study 12 challenging dexterous manipulation tasks and find that H-InDex largely surpasses strong baseline methods and the recent visual foundation models for motor control. Code is available at https://yanjieze.com/H-InDex .
A Novel Gradient Descent Least Squares (GDLS) Algorithm for SMV Gridless Line Spectrum Estimation with Efficiency
Mar 16, 2022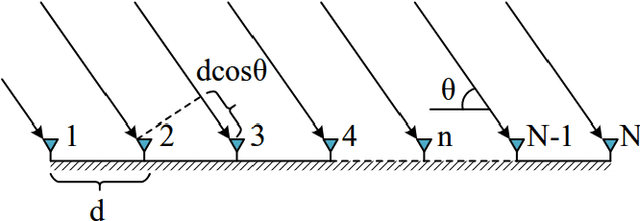


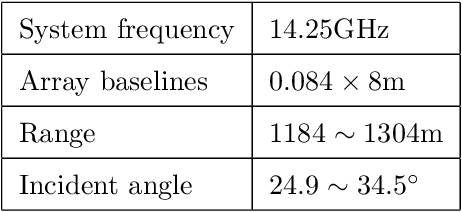
This paper presents a novel efficient method for gridless line spectrum estimation problem with single snapshot, namely the gradient descent least squares (GDLS) method. Conventional single snapshot (a.k.a. SMV measurement) line spectrum estimation methods either rely on smoothing techniques that sacrifice the array aperture, or adopt the sparsity constraint and utilize compressed sensing (CS) method by defining prior grids and resulting in the off-grid problem. Recently emerged atomic norm minimization (ANM) methods achieved gridless SMV line spectrum estimation, but its computational complexity is extremely high; thus it is practically infeasible in real applications with large problem scales. Our proposed GDLS method reformulates the line spectrum estimations problem into a least squares (LS) estimation problem and solves the corresponding objective function via gradient descent algorithm in an iterative fashion with efficiency. The convergence guarantee, computational complexity, as well as performance analysis are discussed in this paper. Numerical simulations and real data experiments show that the proposed GDLS algorithm outperforms the state-of-the-art methods e.g., CS and ANM, in terms of estimation performances. It can completely avoid the off-grid problem, and its computational complexity is significantly lower than ANM. Our method shows great potential in various applications e.g. direction of arrival (DOA) estimation and tomographic synthetic aperture radar (TomoSAR) imaging.