 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH-InDex: Visual Reinforcement Learning with Hand-Informed Representations for Dexterous Manipulation
Oct 13, 2023Human hands possess remarkable dexterity and have long served as a source of inspiration for robotic manipulation. In this work, we propose a human $\textbf{H}$and$\textbf{-In}$formed visual representation learning framework to solve difficult $\textbf{Dex}$terous manipulation tasks ($\textbf{H-InDex}$) with reinforcement learning. Our framework consists of three stages: (i) pre-training representations with 3D human hand pose estimation, (ii) offline adapting representations with self-supervised keypoint detection, and (iii) reinforcement learning with exponential moving average BatchNorm. The last two stages only modify $0.36\%$ parameters of the pre-trained representation in total, ensuring the knowledge from pre-training is maintained to the full extent. We empirically study 12 challenging dexterous manipulation tasks and find that H-InDex largely surpasses strong baseline methods and the recent visual foundation models for motor control. Code is available at https://yanjieze.com/H-InDex .
SLHCat: Mapping Wikipedia Categories and Lists to DBpedia by Leveraging Semantic, Lexical, and Hierarchical Features
Sep 27, 2023Wikipedia articles are hierarchically organized through categories and lists, providing one of the most comprehensive and universal taxonomy, but its open creation is causing redundancies and inconsistencies. Assigning DBPedia classes to Wikipedia categories and lists can alleviate the problem, realizing a large knowledge graph which is essential for categorizing digital contents through entity linking and typing. However, the existing approach of CaLiGraph is producing incomplete and non-fine grained mappings. In this paper, we tackle the problem as ontology alignment, where structural information of knowledge graphs and lexical and semantic features of ontology class names are utilized to discover confident mappings, which are in turn utilized for finetuing pretrained language models in a distant supervision fashion. Our method SLHCat consists of two main parts: 1) Automatically generating training data by leveraging knowledge graph structure, semantic similarities, and named entity typing. 2) Finetuning and prompt-tuning of the pre-trained language model BERT are carried out over the training data, to capture semantic and syntactic properties of class names. Our model SLHCat is evaluated over a benchmark dataset constructed by annotating 3000 fine-grained CaLiGraph-DBpedia mapping pairs. SLHCat is outperforming the baseline model by a large margin of 25% in accuracy, offering a practical solution for large-scale ontology mapping.
Towards Effective Ancient Chinese Translation: Dataset, Model, and Evaluation
Aug 01, 2023
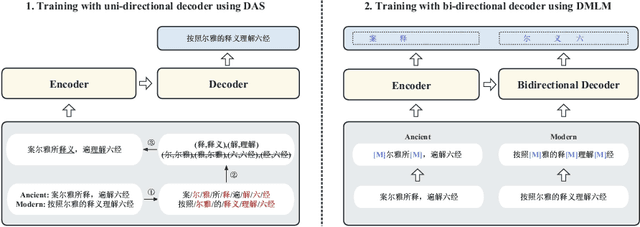


Interpreting ancient Chinese has been the key to comprehending vast Chinese literature, tradition, and civilization. In this paper, we propose Erya for ancient Chinese translation. From a dataset perspective, we collect, clean, and classify ancient Chinese materials from various sources, forming the most extensive ancient Chinese resource to date. From a model perspective, we devise Erya training method oriented towards ancient Chinese. We design two jointly-working tasks: disyllabic aligned substitution (DAS) and dual masked language model (DMLM). From an evaluation perspective, we build a benchmark to judge ancient Chinese translation quality in different scenarios and evaluate the ancient Chinese translation capacities of various existing models. Our model exhibits remarkable zero-shot performance across five domains, with over +12.0 BLEU against GPT-3.5 models and better human evaluation results than ERNIE Bot. Subsequent fine-tuning further shows the superior transfer capability of Erya model with +6.2 BLEU gain. We release all the above-mentioned resources at https://github.com/RUCAIBox/Erya.