 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinConsensus: A Consensus-Based Benchmark for Evaluating Chinese Medical LLMs across Difficulty Levels
Mar 03, 2026Large language models (LLMs) are increasingly applied to health management, showing promise across disease prevention, clinical decision-making, and long-term care. However, existing medical benchmarks remain largely static and task-isolated, failing to capture the openness, longitudinal structure, and safety-critical complexity of real-world clinical workflows. We introduce ClinConsensus, a Chinese medical benchmark curated, validated, and quality-controlled by clinical experts. ClinConsensus comprises 2500 open-ended cases spanning the full continuum of care--from prevention and intervention to long-term follow-up--covering 36 medical specialties, 12 common clinical task types, and progressively increasing levels of complexity. To enable reliable evaluation of such complex scenarios, we adopt a rubric-based grading protocol and propose the Clinically Applicable Consistency Score (CACS@k). We further introduce a dual-judge evaluation framework, combining a high-capability LLM-as-judge with a distilled, locally deployable judge model trained via supervised fine-tuning, enabling scalable and reproducible evaluation aligned with physician judgment. Using ClinConsensus, we conduct a comprehensive assessment of several leading LLMs and reveal substantial heterogeneity across task themes, care stages, and medical specialties. While top-performing models achieve comparable overall scores, they differ markedly in reasoning, evidence use, and longitudinal follow-up capabilities, and clinically actionable treatment planning remains a key bottleneck. We release ClinConsensus as an extensible benchmark to support the development and evaluation of medical LLMs that are robust, clinically grounded, and ready for real-world deployment.
Outcome Accuracy is Not Enough: Aligning the Reasoning Process of Reward Models
Feb 04, 2026Generative Reward Models (GenRMs) and LLM-as-a-Judge exhibit deceptive alignment by producing correct judgments for incorrect reasons, as they are trained and evaluated to prioritize Outcome Accuracy, which undermines their ability to generalize during RLHF. We introduce Rationale Consistency, a fine-grained metric that quantifies the alignment between the model's reasoning process and human judgment. Our evaluation of frontier models reveals that rationale consistency effectively discriminates among state-of-the-art models and detects deceptive alignment, while outcome accuracy falls short in both respects. To mitigate this gap, we introduce a hybrid signal that combines rationale consistency with outcome accuracy for GenRM training. Our training method achieves state-of-the-art performance on RM-Bench (87.1%) and JudgeBench (82%), surpassing outcome-only baselines by an average of 5%. Using RM during RLHF, our method effectively improves performance as demonstrated on Arena Hard v2, notably yielding a 7% improvement in creative writing tasks. Further analysis confirms that our method escapes the deceptive alignment trap, effectively reversing the decline in rationale consistency observed in outcome-only training.
PLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice
Jan 23, 2026As large language models (LLMs) are increasingly applied to legal domain-specific tasks, evaluating their ability to perform legal work in real-world settings has become essential. However, existing legal benchmarks rely on simplified and highly standardized tasks, failing to capture the ambiguity, complexity, and reasoning demands of real legal practice. Moreover, prior evaluations often adopt coarse, single-dimensional metrics and do not explicitly assess fine-grained legal reasoning. To address these limitations, we introduce PLawBench, a Practical Law Benchmark designed to evaluate LLMs in realistic legal practice scenarios. Grounded in real-world legal workflows, PLawBench models the core processes of legal practitioners through three task categories: public legal consultation, practical case analysis, and legal document generation. These tasks assess a model's ability to identify legal issues and key facts, perform structured legal reasoning, and generate legally coherent documents. PLawBench comprises 850 questions across 13 practical legal scenarios, with each question accompanied by expert-designed evaluation rubrics, resulting in approximately 12,500 rubric items for fine-grained assessment. Using an LLM-based evaluator aligned with human expert judgments, we evaluate 10 state-of-the-art LLMs. Experimental results show that none achieves strong performance on PLawBench, revealing substantial limitations in the fine-grained legal reasoning capabilities of current LLMs and highlighting important directions for future evaluation and development of legal LLMs. Data is available at: https://github.com/skylenage/PLawbench.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
RMTBench: Benchmarking LLMs Through Multi-Turn User-Centric Role-Playing
Jul 27, 2025Recent advancements in Large Language Models (LLMs) have shown outstanding potential for role-playing applications. Evaluating these capabilities is becoming crucial yet remains challenging. Existing benchmarks mostly adopt a \textbf{character-centric} approach, simplify user-character interactions to isolated Q&A tasks, and fail to reflect real-world applications. To address this limitation, we introduce RMTBench, a comprehensive \textbf{user-centric} bilingual role-playing benchmark featuring 80 diverse characters and over 8,000 dialogue rounds. RMTBench includes custom characters with detailed backgrounds and abstract characters defined by simple traits, enabling evaluation across various user scenarios. Our benchmark constructs dialogues based on explicit user motivations rather than character descriptions, ensuring alignment with practical user applications. Furthermore, we construct an authentic multi-turn dialogue simulation mechanism. With carefully selected evaluation dimensions and LLM-based scoring, this mechanism captures the complex intention of conversations between the user and the character. By shifting focus from character background to user intention fulfillment, RMTBench bridges the gap between academic evaluation and practical deployment requirements, offering a more effective framework for assessing role-playing capabilities in LLMs. All code and datasets will be released soon.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
A4-Unet: Deformable Multi-Scale Attention Network for Brain Tumor Segmentation
Dec 08, 2024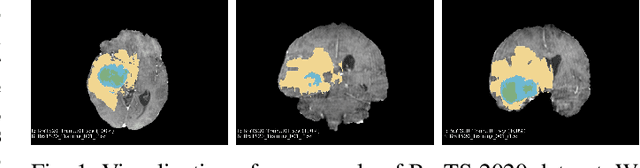
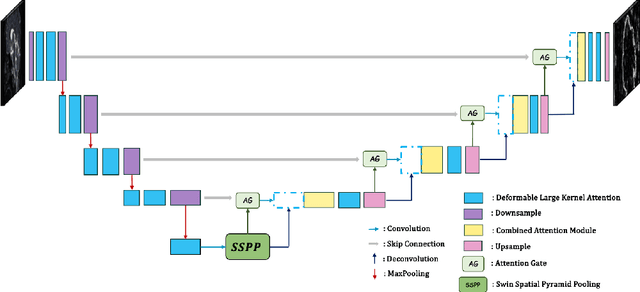
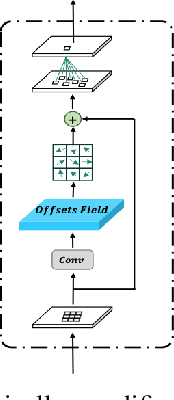
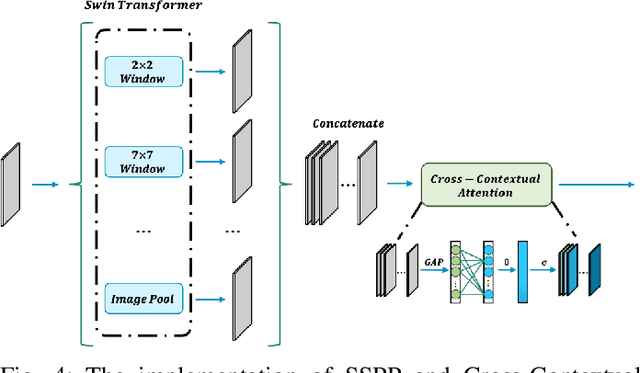
Brain tumor segmentation models have aided diagnosis in recent years. However, they face MRI complexity and variability challenges, including irregular shapes and unclear boundaries, leading to noise, misclassification, and incomplete segmentation, thereby limiting accuracy. To address these issues, we adhere to an outstanding Convolutional Neural Networks (CNNs) design paradigm and propose a novel network named A4-Unet. In A4-Unet, Deformable Large Kernel Attention (DLKA) is incorporated in the encoder, allowing for improved capture of multi-scale tumors. Swin Spatial Pyramid Pooling (SSPP) with cross-channel attention is employed in a bottleneck further to study long-distance dependencies within images and channel relationships. To enhance accuracy, a Combined Attention Module (CAM) with Discrete Cosine Transform (DCT) orthogonality for channel weighting and convolutional element-wise multiplication is introduced for spatial weighting in the decoder. Attention gates (AG) are added in the skip connection to highlight the foreground while suppressing irrelevant background information. The proposed network is evaluated on three authoritative MRI brain tumor benchmarks and a proprietary dataset, and it achieves a 94.4% Dice score on the BraTS 2020 dataset, thereby establishing multiple new state-of-the-art benchmarks. The code is available here: https://github.com/WendyWAAAAANG/A4-Unet.
Language Models can Self-Lengthen to Generate Long Texts
Oct 31, 2024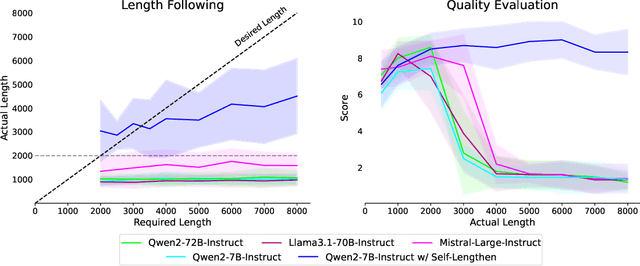
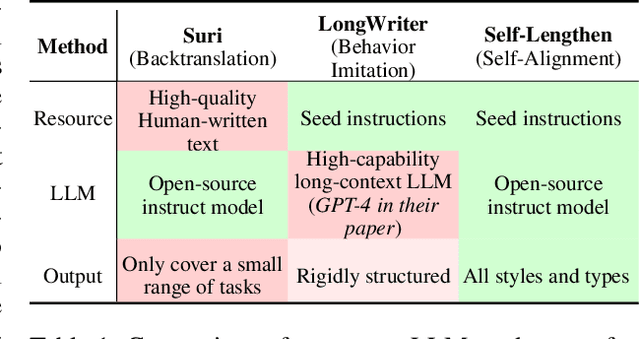
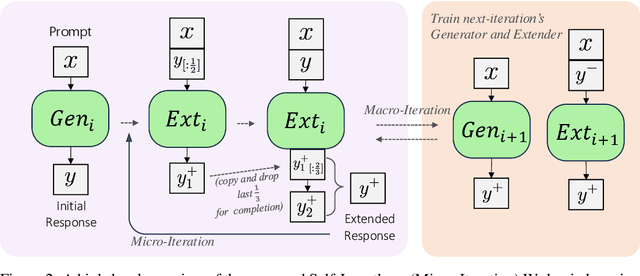
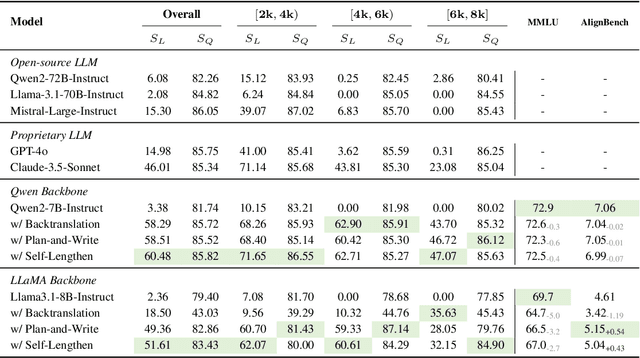
Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to process long contexts, yet a notable gap remains in generating long, aligned outputs. This limitation stems from a training gap where pre-training lacks effective instructions for long-text generation, and post-training data primarily consists of short query-response pairs. Current approaches, such as instruction backtranslation and behavior imitation, face challenges including data quality, copyright issues, and constraints on proprietary model usage. In this paper, we introduce an innovative iterative training framework called Self-Lengthen that leverages only the intrinsic knowledge and skills of LLMs without the need for auxiliary data or proprietary models. The framework consists of two roles: the Generator and the Extender. The Generator produces the initial response, which is then split and expanded by the Extender. This process results in a new, longer response, which is used to train both the Generator and the Extender iteratively. Through this process, the models are progressively trained to handle increasingly longer responses. Experiments on benchmarks and human evaluations show that Self-Lengthen outperforms existing methods in long-text generation, when applied to top open-source LLMs such as Qwen2 and LLaMA3. Our code is publicly available at https://github.com/QwenLM/Self-Lengthen.
Neuron-based Personality Trait Induction in Large Language Models
Oct 16, 2024
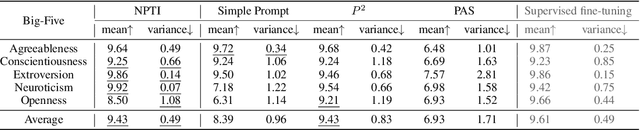


Large language models (LLMs) have become increasingly proficient at simulating various personality traits, an important capability for supporting related applications (e.g., role-playing). To further improve this capacity, in this paper, we present a neuron-based approach for personality trait induction in LLMs, with three major technical contributions. First, we construct PersonalityBench, a large-scale dataset for identifying and evaluating personality traits in LLMs. This dataset is grounded in the Big Five personality traits from psychology and is designed to assess the generative capabilities of LLMs towards specific personality traits. Second, by leveraging PersonalityBench, we propose an efficient method for identifying personality-related neurons within LLMs by examining the opposite aspects of a given trait. Third, we develop a simple yet effective induction method that manipulates the values of these identified personality-related neurons. This method enables fine-grained control over the traits exhibited by LLMs without training and modifying model parameters. Extensive experiments validate the efficacy of our neuron identification and trait induction methods. Notably, our approach achieves comparable performance as fine-tuned models, offering a more efficient and flexible solution for personality trait induction in LLMs. We provide access to all the mentioned resources at https://github.com/RUCAIBox/NPTI.
LLMBox: A Comprehensive Library for Large Language Models
Jul 08, 2024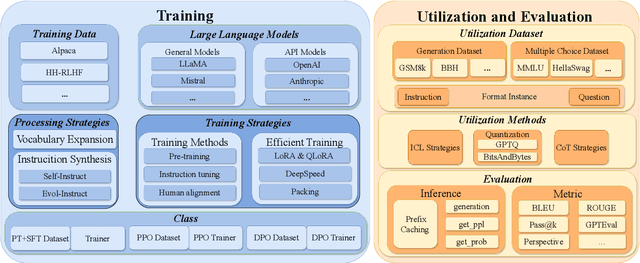
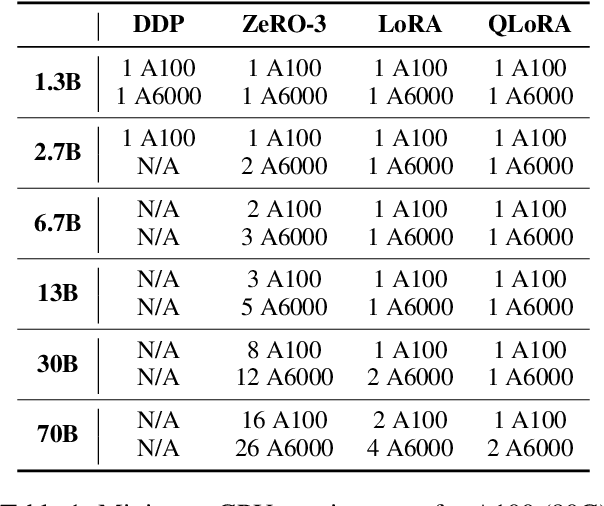


To facilitate the research on large language models (LLMs), this paper presents a comprehensive and unified library, LLMBox, to ease the development, use, and evaluation of LLMs. This library is featured with three main merits: (1) a unified data interface that supports the flexible implementation of various training strategies, (2) a comprehensive evaluation that covers extensive tasks, datasets, and models, and (3) more practical consideration, especially on user-friendliness and efficiency. With our library, users can easily reproduce existing methods, train new models, and conduct comprehensive performance comparisons. To rigorously test LLMBox, we conduct extensive experiments in a diverse coverage of evaluation settings, and experimental results demonstrate the effectiveness and efficiency of our library in supporting various implementations related to LLMs. The detailed introduction and usage guidance can be found at https://github.com/RUCAIBox/LLMBox.