 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleLong: A Multi-Timescale Benchmark for Long Video Understanding
May 29, 2025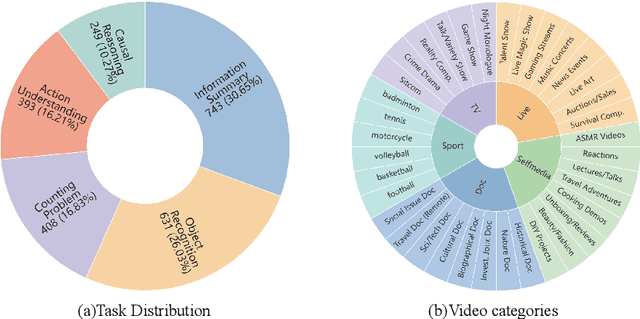



Although long-video understanding demands that models capture hierarchical temporal information -- from clip (seconds) and shot (tens of seconds) to event (minutes) and story (hours) -- existing benchmarks either neglect this multi-scale design or scatter scale-specific questions across different videos, preventing direct comparison of model performance across timescales on the same content. To address this, we introduce ScaleLong, the first benchmark to disentangle these factors by embedding questions targeting four hierarchical timescales -- clip (seconds), shot (tens of seconds), event (minutes), and story (hours) -- all within the same video content. This within-content multi-timescale questioning design enables direct comparison of model performance across timescales on identical videos. ScaleLong features 269 long videos (avg.\ 86\,min) from 5 main categories and 36 sub-categories, with 4--8 carefully designed questions, including at least one question for each timescale. Evaluating 23 MLLMs reveals a U-shaped performance curve, with higher accuracy at the shortest and longest timescales and a dip at intermediate levels. Furthermore, ablation studies show that increased visual token capacity consistently enhances reasoning across all timescales. ScaleLong offers a fine-grained, multi-timescale benchmark for advancing MLLM capabilities in long-video understanding. The code and dataset are available https://github.com/multimodal-art-projection/ScaleLong.
Multi-Agent Collaboration for Multilingual Code Instruction Tuning
Feb 11, 2025Recent advancement in code understanding and generation demonstrates that code LLMs fine-tuned on a high-quality instruction dataset can gain powerful capabilities to address wide-ranging code-related tasks. However, most previous existing methods mainly view each programming language in isolation and ignore the knowledge transfer among different programming languages. To bridge the gap among different programming languages, we introduce a novel multi-agent collaboration framework to enhance multilingual instruction tuning for code LLMs, where multiple language-specific intelligent agent components with generation memory work together to transfer knowledge from one language to another efficiently and effectively. Specifically, we first generate the language-specific instruction data from the code snippets and then provide the generated data as the seed data for language-specific agents. Multiple language-specific agents discuss and collaborate to formulate a new instruction and its corresponding solution (A new programming language or existing programming language), To further encourage the cross-lingual transfer, each agent stores its generation history as memory and then summarizes its merits and faults. Finally, the high-quality multilingual instruction data is used to encourage knowledge transfer among different programming languages to train Qwen2.5-xCoder. Experimental results on multilingual programming benchmarks demonstrate the superior performance of Qwen2.5-xCoder in sharing common knowledge, highlighting its potential to reduce the cross-lingual gap.
CodeElo: Benchmarking Competition-level Code Generation of LLMs with Human-comparable Elo Ratings
Jan 03, 2025With the increasing code reasoning capabilities of existing large language models (LLMs) and breakthroughs in reasoning models like OpenAI o1 and o3, there is a growing need to develop more challenging and comprehensive benchmarks that effectively test their sophisticated competition-level coding abilities. Existing benchmarks, like LiveCodeBench and USACO, fall short due to the unavailability of private test cases, lack of support for special judges, and misaligned execution environments. To bridge this gap, we introduce CodeElo, a standardized competition-level code generation benchmark that effectively addresses all these challenges for the first time. CodeElo benchmark is mainly based on the official CodeForces platform and tries to align with the platform as much as possible. We compile the recent six months of contest problems on CodeForces with detailed information such as contest divisions, problem difficulty ratings, and problem algorithm tags. We introduce a unique judging method in which problems are submitted directly to the platform and develop a reliable Elo rating calculation system that aligns with the platform and is comparable with human participants but has lower variance. By testing on our CodeElo, we provide the Elo ratings of 30 existing popular open-source and 3 proprietary LLMs for the first time. The results show that o1-mini and QwQ-32B-Preview stand out significantly, achieving Elo ratings of 1578 and 1261, respectively, while other models struggle even with the easiest problems, placing in the lowest 25 percent among all human participants. Detailed analysis experiments are also conducted to provide insights into performance across algorithms and comparisons between using C++ and Python, which can suggest directions for future studies.
Language Models can Self-Lengthen to Generate Long Texts
Oct 31, 2024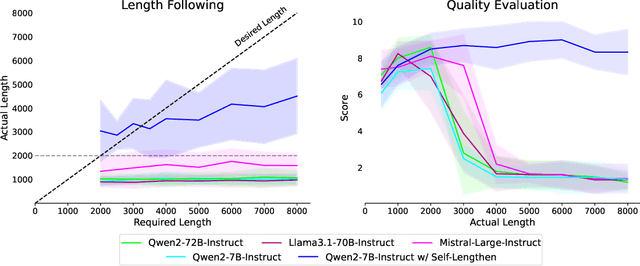
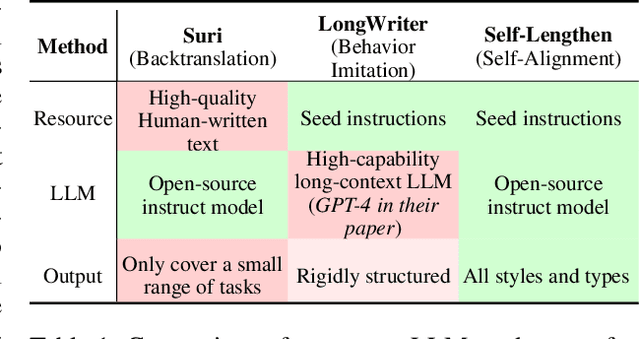
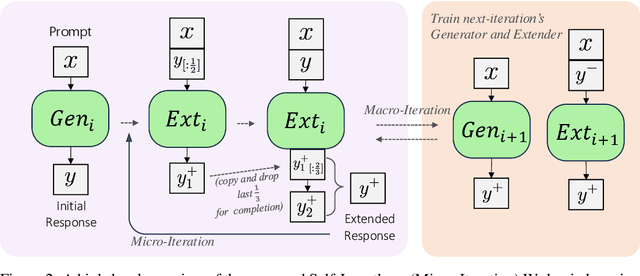
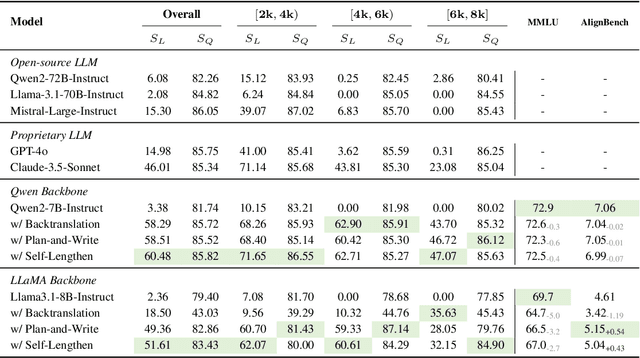
Recent advancements in Large Language Models (LLMs) have significantly enhanced their ability to process long contexts, yet a notable gap remains in generating long, aligned outputs. This limitation stems from a training gap where pre-training lacks effective instructions for long-text generation, and post-training data primarily consists of short query-response pairs. Current approaches, such as instruction backtranslation and behavior imitation, face challenges including data quality, copyright issues, and constraints on proprietary model usage. In this paper, we introduce an innovative iterative training framework called Self-Lengthen that leverages only the intrinsic knowledge and skills of LLMs without the need for auxiliary data or proprietary models. The framework consists of two roles: the Generator and the Extender. The Generator produces the initial response, which is then split and expanded by the Extender. This process results in a new, longer response, which is used to train both the Generator and the Extender iteratively. Through this process, the models are progressively trained to handle increasingly longer responses. Experiments on benchmarks and human evaluations show that Self-Lengthen outperforms existing methods in long-text generation, when applied to top open-source LLMs such as Qwen2 and LLaMA3. Our code is publicly available at https://github.com/QwenLM/Self-Lengthen.
Aligning CodeLLMs with Direct Preference Optimization
Oct 24, 2024The last year has witnessed the rapid progress of large language models (LLMs) across diverse domains. Among them, CodeLLMs have garnered particular attention because they can not only assist in completing various programming tasks but also represent the decision-making and logical reasoning capabilities of LLMs. However, current CodeLLMs mainly focus on pre-training and supervised fine-tuning scenarios, leaving the alignment stage, which is important for post-training LLMs, under-explored. This work first identifies that the commonly used PPO algorithm may be suboptimal for the alignment of CodeLLM because the involved reward rules are routinely coarse-grained and potentially flawed. We then advocate addressing this using the DPO algorithm. Based on only preference data pairs, DPO can render the model rank data automatically, giving rise to a fine-grained rewarding pattern more robust than human intervention. We also contribute a pipeline for collecting preference pairs for DPO on CodeLLMs. Studies show that our method significantly improves the performance of existing CodeLLMs on benchmarks such as MBPP and HumanEval.
Omni-MATH: A Universal Olympiad Level Mathematic Benchmark For Large Language Models
Oct 10, 2024
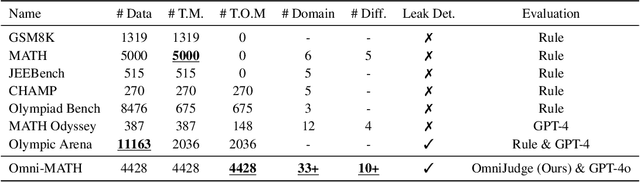

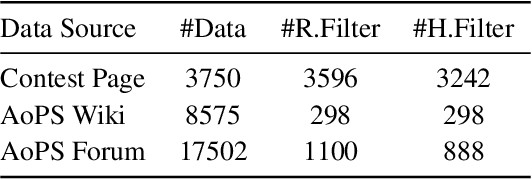
Recent advancements in large language models (LLMs) have led to significant breakthroughs in mathematical reasoning capabilities. However, existing benchmarks like GSM8K or MATH are now being solved with high accuracy (e.g., OpenAI o1 achieves 94.8% on MATH dataset), indicating their inadequacy for truly challenging these models. To bridge this gap, we propose a comprehensive and challenging benchmark specifically designed to assess LLMs' mathematical reasoning at the Olympiad level. Unlike existing Olympiad-related benchmarks, our dataset focuses exclusively on mathematics and comprises a vast collection of 4428 competition-level problems with rigorous human annotation. These problems are meticulously categorized into over 33 sub-domains and span more than 10 distinct difficulty levels, enabling a holistic assessment of model performance in Olympiad-mathematical reasoning. Furthermore, we conducted an in-depth analysis based on this benchmark. Our experimental results show that even the most advanced models, OpenAI o1-mini and OpenAI o1-preview, struggle with highly challenging Olympiad-level problems, with 60.54% and 52.55% accuracy, highlighting significant challenges in Olympiad-level mathematical reasoning.
Automatically Generating Numerous Context-Driven SFT Data for LLMs across Diverse Granularity
May 26, 2024Constructing high-quality query-response pairs from custom corpus is crucial for supervised fine-tuning (SFT) large language models (LLMs) in many applications, like creating domain-specific AI assistants or roleplaying agents. However, sourcing this data through human annotation is costly, and existing automated methods often fail to capture the diverse range of contextual granularity and tend to produce homogeneous data. To tackle these issues, we introduce a novel method named AugCon, capable of automatically generating context-driven SFT data across multiple levels of granularity with high diversity, quality and fidelity. AugCon begins by generating queries using the Context-Split-Tree (CST), an innovative approach for recursively deriving queries and splitting context to cover full granularity. Then, we train a scorer through contrastive learning to collaborate with CST to rank and refine queries. Finally, a synergistic integration of self-alignment and self-improving is introduced to obtain high-fidelity responses. Extensive experiments are conducted incorporating both human and automatic evaluations, encompassing a test scenario and four widely-used benchmarks in English and Chinese. The results highlight the significant advantages of AugCon in producing high diversity, quality, and fidelity SFT data against several state-of-the-art methods. All of our code, dataset, and fine-tuned model will be available at: https://github.com/quanshr/AugCon.
DMoERM: Recipes of Mixture-of-Experts for Effective Reward Modeling
Mar 02, 2024The performance of the reward model (RM) is a critical factor in improving the effectiveness of the large language model (LLM) during alignment fine-tuning. There remain two challenges in RM training: 1) training the same RM using various categories of data may cause its generalization performance to suffer from multi-task disturbance, and 2) the human annotation consistency rate is generally only $60\%$ to $75\%$, causing training data to contain a lot of noise. To tackle these two challenges, we introduced the idea of Mixture-of-Experts (MoE) into the field of RM for the first time. We propose the Double-Layer MoE RM (DMoERM). The outer layer MoE is a sparse model. After classifying an input into task categories, we route it to the corresponding inner layer task-specific model. The inner layer MoE is a dense model. We decompose the specific task into multiple capability dimensions and individually fine-tune a LoRA expert on each one. Their outputs are then synthesized by an MLP to compute the final rewards. To minimize costs, we call a public LLM API to obtain the capability preference labels. The validation on manually labeled datasets confirms that our model attains superior consistency with human preference and outstrips advanced generative approaches. Meanwhile, through BoN sampling and RL experiments, we demonstrate that our model outperforms state-of-the-art ensemble methods of RM and mitigates the overoptimization problem. Our code and dataset are available at: https://github.com/quanshr/DMoERM-v1.