 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFC-MIR: A Mobile Screen Awareness Framework for Intent-Aware Recommendation based on Frame-Compressed Multimodal Trajectory Reasoning
Dec 22, 2025Identifying user intent from mobile UI operation trajectories is critical for advancing UI understanding and enabling task automation agents. While Multimodal Large Language Models (MLLMs) excel at video understanding tasks, their real-time mobile deployment is constrained by heavy computational costs and inefficient redundant frame processing. To address these issues, we propose the FC-MIR framework: leveraging keyframe sampling and adaptive concatenation, it cuts visual redundancy to boost inference efficiency, while integrating state-of-the-art closed-source MLLMs or fine-tuned models (e.g., Qwen3-VL) for trajectory summarization and intent prediction. We further expand task scope to explore generating post-prediction operations and search suggestions, and introduce a fine-grained metric to evaluate the practical utility of summaries, predictions, and suggestions. For rigorous assessment, we construct a UI trajectory dataset covering scenarios from UI-Agents (Agent-I) and real user interactions (Person-I). Experimental results show our compression method retains performance at 50%-60% compression rates; both closed-source and fine-tuned MLLMs demonstrate strong intent summarization, supporting potential lightweight on-device deployment. However, MLLMs still struggle with useful and "surprising" suggestions, leaving room for improvement. Finally, we deploy the framework in a real-world setting, integrating UI perception and UI-Agent proxies to lay a foundation for future progress in this field.
GroundingME: Exposing the Visual Grounding Gap in MLLMs through Multi-Dimensional Evaluation
Dec 19, 2025Visual grounding, localizing objects from natural language descriptions, represents a critical bridge between language and vision understanding. While multimodal large language models (MLLMs) achieve impressive scores on existing benchmarks, a fundamental question remains: can MLLMs truly ground language in vision with human-like sophistication, or are they merely pattern-matching on simplified datasets? Current benchmarks fail to capture real-world complexity where humans effortlessly navigate ambiguous references and recognize when grounding is impossible. To rigorously assess MLLMs' true capabilities, we introduce GroundingME, a benchmark that systematically challenges models across four critical dimensions: (1) Discriminative, distinguishing highly similar objects, (2) Spatial, understanding complex relational descriptions, (3) Limited, handling occlusions or tiny objects, and (4) Rejection, recognizing ungroundable queries. Through careful curation combining automated generation with human verification, we create 1,005 challenging examples mirroring real-world complexity. Evaluating 25 state-of-the-art MLLMs reveals a profound capability gap: the best model achieves only 45.1% accuracy, while most score 0% on rejection tasks, reflexively hallucinating objects rather than acknowledging their absence, raising critical safety concerns for deployment. We explore two strategies for improvements: (1) test-time scaling selects optimal response by thinking trajectory to improve complex grounding by up to 2.9%, and (2) data-mixture training teaches models to recognize ungroundable queries, boosting rejection accuracy from 0% to 27.9%. GroundingME thus serves as both a diagnostic tool revealing current limitations in MLLMs and a roadmap toward human-level visual grounding.
C$^3$TG: Conflict-aware, Composite, and Collaborative Controlled Text Generation
Nov 16, 2025Recent advancements in large language models (LLMs) have demonstrated remarkable text generation capabilities. However, controlling specific attributes of generated text remains challenging without architectural modifications or extensive fine-tuning. Current methods typically toggle a single, basic attribute but struggle with precise multi-attribute control. In scenarios where attribute requirements conflict, existing methods lack coordination mechanisms, causing interference between desired attributes. Furthermore, these methods fail to incorporate iterative optimization processes in the controlled generation pipeline. To address these limitations, we propose Conflict-aware, Composite, and Collaborative Controlled Text Generation (C$^3$TG), a two-phase framework for fine-grained, multi-dimensional text attribute control. During generation, C$^3$TG selectively pairs the LLM with the required attribute classifiers from the 17 available dimensions and employs weighted KL-divergence to adjust token probabilities. The optimization phase then leverages an energy function combining classifier scores and penalty terms to resolve attribute conflicts through iterative feedback, enabling precise control over multiple dimensions simultaneously while preserving natural text flow. Experiments show that C$^3$TG significantly outperforms baselines across multiple metrics including attribute accuracy, linguistic fluency, and output diversity, while simultaneously reducing toxicity. These results establish C$^3$TG as an effective and flexible solution for multi-dimensional text attribute control that requires no costly model modifications.
Adaptive Redundancy Regulation for Balanced Multimodal Information Refinement
Nov 14, 2025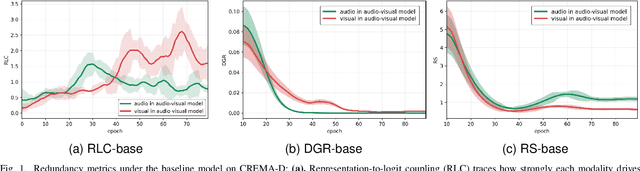
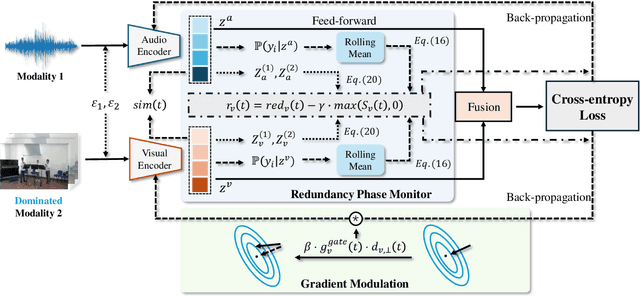
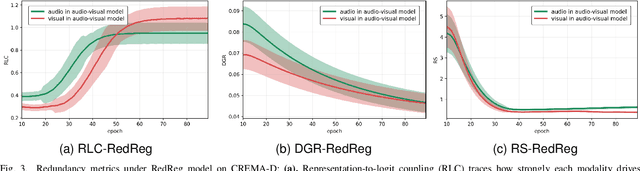
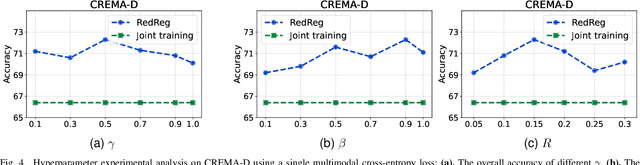
Multimodal learning aims to improve performance by leveraging data from multiple sources. During joint multimodal training, due to modality bias, the advantaged modality often dominates backpropagation, leading to imbalanced optimization. Existing methods still face two problems: First, the long-term dominance of the dominant modality weakens representation-output coupling in the late stages of training, resulting in the accumulation of redundant information. Second, previous methods often directly and uniformly adjust the gradients of the advantaged modality, ignoring the semantics and directionality between modalities. To address these limitations, we propose Adaptive Redundancy Regulation for Balanced Multimodal Information Refinement (RedReg), which is inspired by information bottleneck principle. Specifically, we construct a redundancy phase monitor that uses a joint criterion of effective gain growth rate and redundancy to trigger intervention only when redundancy is high. Furthermore, we design a co-information gating mechanism to estimate the contribution of the current dominant modality based on cross-modal semantics. When the task primarily relies on a single modality, the suppression term is automatically disabled to preserve modality-specific information. Finally, we project the gradient of the dominant modality onto the orthogonal complement of the joint multimodal gradient subspace and suppress the gradient according to redundancy. Experiments show that our method demonstrates superiority among current major methods in most scenarios. Ablation experiments verify the effectiveness of our method. The code is available at https://github.com/xia-zhe/RedReg.git
Synthesizing Sheet Music Problems for Evaluation and Reinforcement Learning
Sep 04, 2025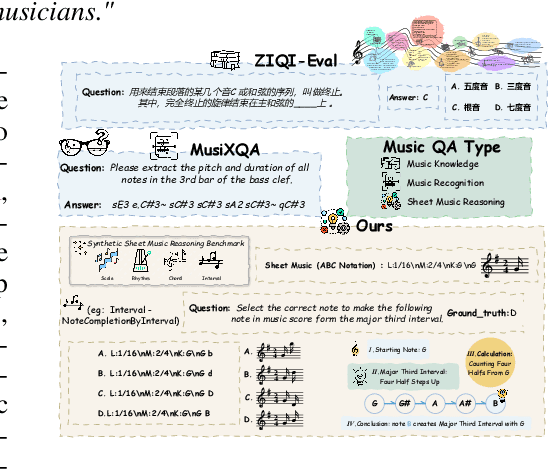

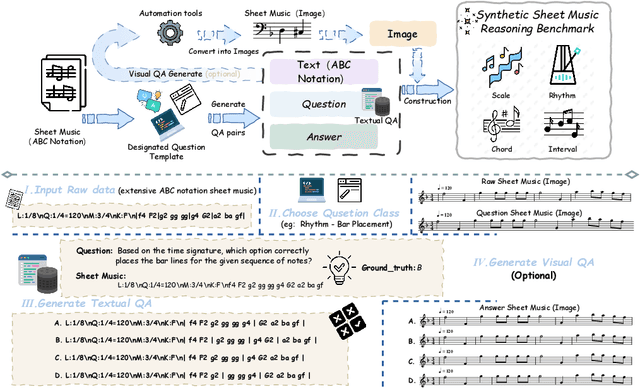
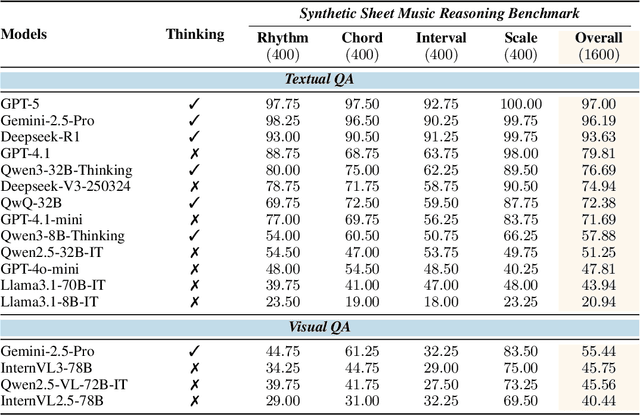
Enhancing the ability of Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs) to interpret sheet music is a crucial step toward building AI musicians. However, current research lacks both evaluation benchmarks and training data for sheet music reasoning. To address this, we propose the idea of synthesizing sheet music problems grounded in music theory, which can serve both as evaluation benchmarks and as training data for reinforcement learning with verifiable rewards (RLVR). We introduce a data synthesis framework that generates verifiable sheet music questions in both textual and visual modalities, leading to the Synthetic Sheet Music Reasoning Benchmark (SSMR-Bench) and a complementary training set. Evaluation results on SSMR-Bench show the importance of models' reasoning abilities in interpreting sheet music. At the same time, the poor performance of Gemini 2.5-Pro highlights the challenges that MLLMs still face in interpreting sheet music in a visual format. By leveraging synthetic data for RLVR, Qwen3-8B-Base and Qwen2.5-VL-Instruct achieve improvements on the SSMR-Bench. Besides, the trained Qwen3-8B-Base surpasses GPT-4 in overall performance on MusicTheoryBench and achieves reasoning performance comparable to GPT-4 with the strategies of Role play and Chain-of-Thought. Notably, its performance on math problems also improves relative to the original Qwen3-8B-Base. Furthermore, our results show that the enhanced reasoning ability can also facilitate music composition. In conclusion, we are the first to propose the idea of synthesizing sheet music problems based on music theory rules, and demonstrate its effectiveness not only in advancing model reasoning for sheet music understanding but also in unlocking new possibilities for AI-assisted music creation.
UMRE: A Unified Monotonic Transformation for Ranking Ensemble in Recommender Systems
Aug 11, 2025Industrial recommender systems commonly rely on ensemble sorting (ES) to combine predictions from multiple behavioral objectives. Traditionally, this process depends on manually designed nonlinear transformations (e.g., polynomial or exponential functions) and hand-tuned fusion weights to balance competing goals -- an approach that is labor-intensive and frequently suboptimal in achieving Pareto efficiency. In this paper, we propose a novel Unified Monotonic Ranking Ensemble (UMRE) framework to address the limitations of traditional methods in ensemble sorting. UMRE replaces handcrafted transformations with Unconstrained Monotonic Neural Networks (UMNN), which learn expressive, strictly monotonic functions through the integration of positive neural integrals. Subsequently, a lightweight ranking model is employed to fuse the prediction scores, assigning personalized weights to each prediction objective. To balance competing goals, we further introduce a Pareto optimality strategy that adaptively coordinates task weights during training. UMRE eliminates manual tuning, maintains ranking consistency, and achieves fine-grained personalization. Experimental results on two public recommendation datasets (Kuairand and Tenrec) and online A/B tests demonstrate impressive performance and generalization capabilities.
Entropy-Memorization Law: Evaluating Memorization Difficulty of Data in LLMs
Jul 08, 2025Large Language Models (LLMs) are known to memorize portions of their training data, sometimes reproducing content verbatim when prompted appropriately. In this work, we investigate a fundamental yet under-explored question in the domain of memorization: How to characterize memorization difficulty of training data in LLMs? Through empirical experiments on OLMo, a family of open models, we present the Entropy-Memorization Law. It suggests that data entropy is linearly correlated with memorization score. Moreover, in a case study of memorizing highly randomized strings, or "gibberish", we observe that such sequences, despite their apparent randomness, exhibit unexpectedly low empirical entropy compared to the broader training corpus. Adopting the same strategy to discover Entropy-Memorization Law, we derive a simple yet effective approach to distinguish training and testing data, enabling Dataset Inference (DI).
ForensicHub: A Unified Benchmark & Codebase for All-Domain Fake Image Detection and Localization
May 16, 2025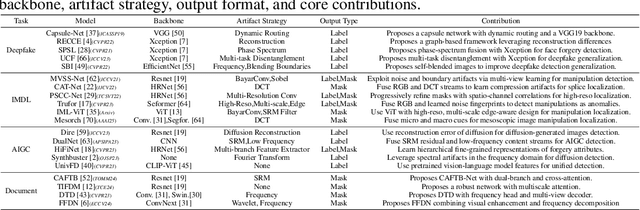
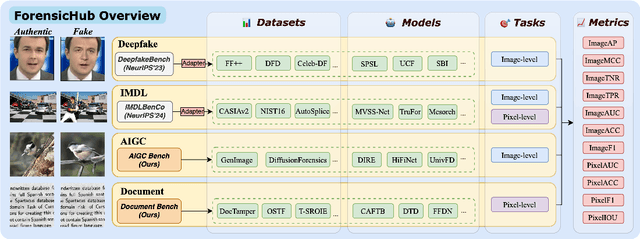
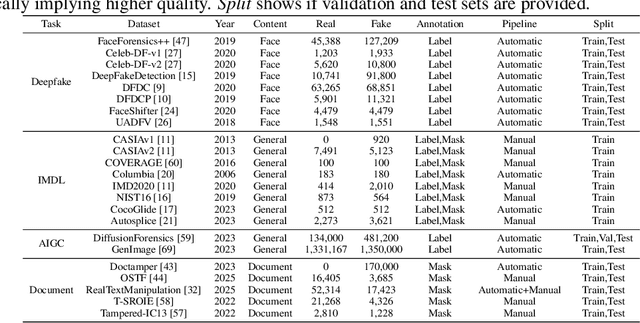
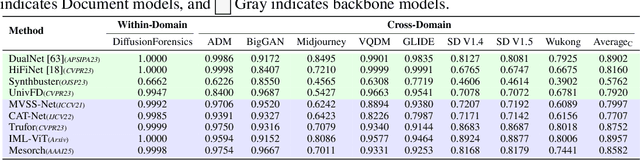
The field of Fake Image Detection and Localization (FIDL) is highly fragmented, encompassing four domains: deepfake detection (Deepfake), image manipulation detection and localization (IMDL), artificial intelligence-generated image detection (AIGC), and document image manipulation localization (Doc). Although individual benchmarks exist in some domains, a unified benchmark for all domains in FIDL remains blank. The absence of a unified benchmark results in significant domain silos, where each domain independently constructs its datasets, models, and evaluation protocols without interoperability, preventing cross-domain comparisons and hindering the development of the entire FIDL field. To close the domain silo barrier, we propose ForensicHub, the first unified benchmark & codebase for all-domain fake image detection and localization. Considering drastic variations on dataset, model, and evaluation configurations across all domains, as well as the scarcity of open-sourced baseline models and the lack of individual benchmarks in some domains, ForensicHub: i) proposes a modular and configuration-driven architecture that decomposes forensic pipelines into interchangeable components across datasets, transforms, models, and evaluators, allowing flexible composition across all domains; ii) fully implements 10 baseline models, 6 backbones, 2 new benchmarks for AIGC and Doc, and integrates 2 existing benchmarks of DeepfakeBench and IMDLBenCo through an adapter-based design; iii) conducts indepth analysis based on the ForensicHub, offering 8 key actionable insights into FIDL model architecture, dataset characteristics, and evaluation standards. ForensicHub represents a significant leap forward in breaking the domain silos in the FIDL field and inspiring future breakthroughs.
Palette of Language Models: A Solver for Controlled Text Generation
Mar 14, 2025



Recent advancements in large language models have revolutionized text generation with their remarkable capabilities. These models can produce controlled texts that closely adhere to specific requirements when prompted appropriately. However, designing an optimal prompt to control multiple attributes simultaneously can be challenging. A common approach is to linearly combine single-attribute models, but this strategy often overlooks attribute overlaps and can lead to conflicts. Therefore, we propose a novel combination strategy inspired by the Law of Total Probability and Conditional Mutual Information Minimization on generative language models. This method has been adapted for single-attribute control scenario and is termed the Palette of Language Models due to its theoretical linkage between attribute strength and generation style, akin to blending colors on an artist's palette. Moreover, positive correlation and attribute enhancement are advanced as theoretical properties to guide a rational combination strategy design. We conduct experiments on both single control and multiple control settings, and achieve surpassing results.
LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
Jan 07, 2025



The advent of real-time large multimodal models (LMMs) like GPT-4o has sparked considerable interest in efficient LMMs. LMM frameworks typically encode visual inputs into vision tokens (continuous representations) and integrate them and textual instructions into the context of large language models (LLMs), where large-scale parameters and numerous context tokens (predominantly vision tokens) result in substantial computational overhead. Previous efforts towards efficient LMMs always focus on replacing the LLM backbone with smaller models, while neglecting the crucial issue of token quantity. In this paper, we introduce LLaVA-Mini, an efficient LMM with minimal vision tokens. To achieve a high compression ratio of vision tokens while preserving visual information, we first analyze how LMMs understand vision tokens and find that most vision tokens only play a crucial role in the early layers of LLM backbone, where they mainly fuse visual information into text tokens. Building on this finding, LLaVA-Mini introduces modality pre-fusion to fuse visual information into text tokens in advance, thereby facilitating the extreme compression of vision tokens fed to LLM backbone into one token. LLaVA-Mini is a unified large multimodal model that can support the understanding of images, high-resolution images, and videos in an efficient manner. Experiments across 11 image-based and 7 video-based benchmarks demonstrate that LLaVA-Mini outperforms LLaVA-v1.5 with just 1 vision token instead of 576. Efficiency analyses reveal that LLaVA-Mini can reduce FLOPs by 77%, deliver low-latency responses within 40 milliseconds, and process over 10,000 frames of video on the GPU hardware with 24GB of memory.