 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLMs for Power System Simulations: A Feedback-driven Multi-agent Framework
Nov 21, 2024The integration of experimental technologies with large language models (LLMs) is transforming scientific research, positioning AI as a versatile research assistant rather than a mere problem-solving tool. In the field of power systems, however, managing simulations -- one of the essential experimental technologies -- remains a challenge for LLMs due to their limited domain-specific knowledge, restricted reasoning capabilities, and imprecise handling of simulation parameters. To address these limitations, we propose a feedback-driven, multi-agent framework that incorporates three proposed modules: an enhanced retrieval-augmented generation (RAG) module, an improved reasoning module, and a dynamic environmental acting module with an error-feedback mechanism. Validated on 69 diverse tasks from Daline and MATPOWER, this framework achieves success rates of 93.13% and 96.85%, respectively, significantly outperforming the latest LLMs (ChatGPT 4o and o1-preview), which achieved a 27.77% success rate on standard simulation tasks and 0% on complex tasks. Additionally, our framework also supports rapid, cost-effective task execution, completing each simulation in approximately 30 seconds at an average cost of 0.014 USD for tokens. Overall, this adaptable framework lays a foundation for developing intelligent LLM-based assistants for human researchers, facilitating power system research and beyond.
Zero-Shot Load Forecasting with Large Language Models
Nov 18, 2024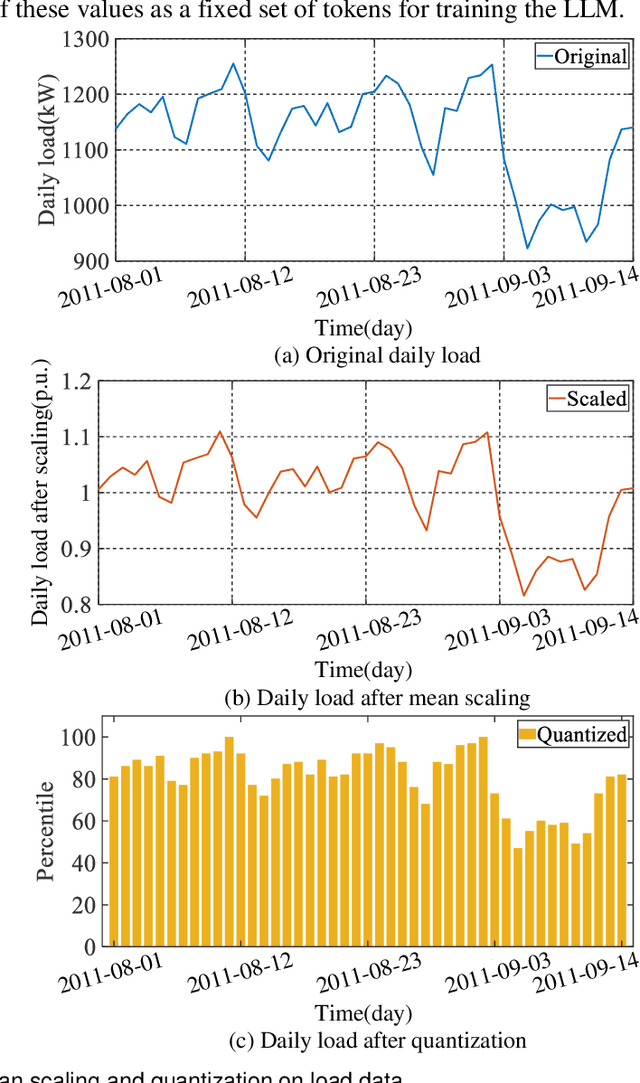



Deep learning models have shown strong performance in load forecasting, but they generally require large amounts of data for model training before being applied to new scenarios, which limits their effectiveness in data-scarce scenarios. Inspired by the great success of pre-trained language models (LLMs) in natural language processing, this paper proposes a zero-shot load forecasting approach using an advanced LLM framework denoted as the Chronos model. By utilizing its extensive pre-trained knowledge, the Chronos model enables accurate load forecasting in data-scarce scenarios without the need for extensive data-specific training. Simulation results across five real-world datasets demonstrate that the Chronos model significantly outperforms nine popular baseline models for both deterministic and probabilistic load forecasting with various forecast horizons (e.g., 1 to 48 hours), even though the Chronos model is neither tailored nor fine-tuned to these specific load datasets. Notably, Chronos reduces root mean squared error (RMSE), continuous ranked probability score (CRPS), and quantile score (QS) by approximately 7.34%-84.30%, 19.63%-60.06%, and 22.83%-54.49%, respectively, compared to baseline models. These results highlight the superiority and flexibility of the Chronos model, positioning it as an effective solution in data-scarce scenarios.
Enabling Large Language Models to Perform Power System Simulations with Previously Unseen Tools: A Case of Daline
Jun 26, 2024


The integration of experiment technologies with large language models (LLMs) is transforming scientific research, offering AI capabilities beyond specialized problem-solving to becoming research assistants for human scientists. In power systems, simulations are essential for research. However, LLMs face significant challenges in power system simulations due to limited pre-existing knowledge and the complexity of power grids. To address this issue, this work proposes a modular framework that integrates expertise from both the power system and LLM domains. This framework enhances LLMs' ability to perform power system simulations on previously unseen tools. Validated using 34 simulation tasks in Daline, a (optimal) power flow simulation and linearization toolbox not yet exposed to LLMs, the proposed framework improved GPT-4o's simulation coding accuracy from 0% to 96.07%, also outperforming the ChatGPT-4o web interface's 33.8% accuracy (with the entire knowledge base uploaded). These results highlight the potential of LLMs as research assistants in power systems.
Privacy-Preserving Distributed Joint Probability Modeling for Spatial-Correlated Wind Farms
Dec 17, 2018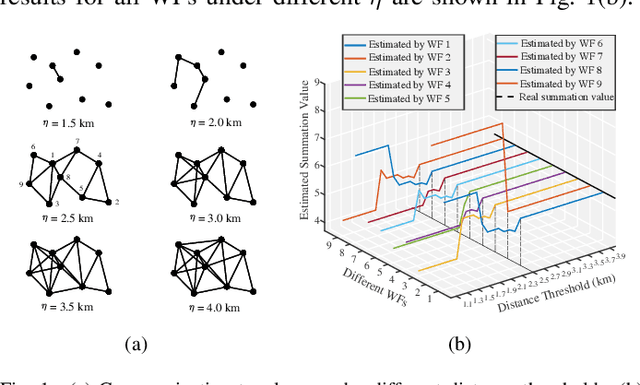
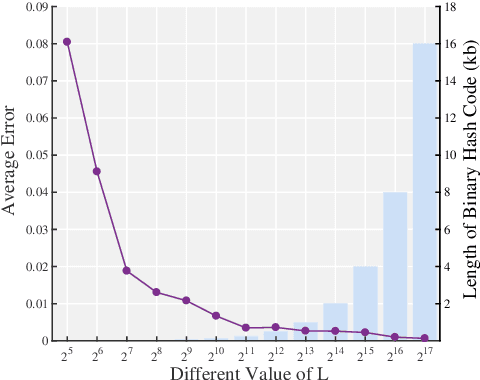
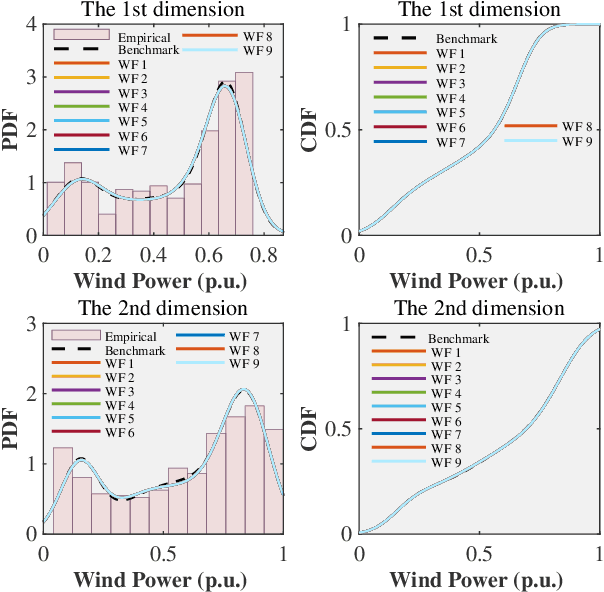
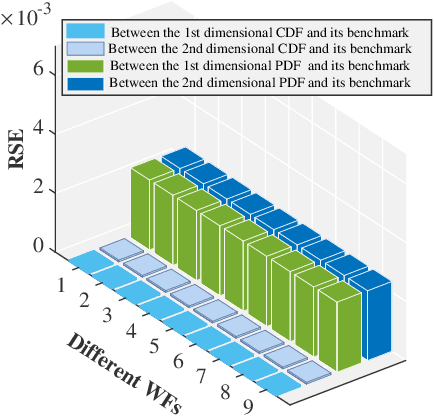
Building the joint probability distribution (JPD) of multiple spatial-correlated wind farms (WFs) is critical for chance-constrained optimal decision-making. The vertical partitioning historical wind power data of WFs is the premise of training the JPD. However, to protect data privacy, WFs with different stakeholders will refuse to share raw data directly or send raw data to a third party as no one knows whether the third party can be trusted. Moreover, the centralized training way is also faced with costly high bandwidth communication, single-point failure and limited scalability. To solve the problems, distributed algorithm is an alternative. But to the best of our knowledge, rarely has literature proposed privacy-preserving distributed (PPD) algorithm to build the JPD of spatial-correlated WFs. Therefore, based on the additive homomorphic encryption and the average consensus algorithm, we first propose a PPD summation algorithm. Meanwhile, based on the binary hash function and the average consensus algorithm, we then present a PPD inner product algorithm. Thereafter, combining the PPD summation and inner product algorithms, a PPD expectation-maximization algorithm for training the Gaussian-mixture-model-based JPD of WFs is eventually developed. The correctness and the robustness to communicate failure of the proposed algorithm is empirically verified using historical data.