 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Load Forecasting with Large Language Models
Nov 18, 2024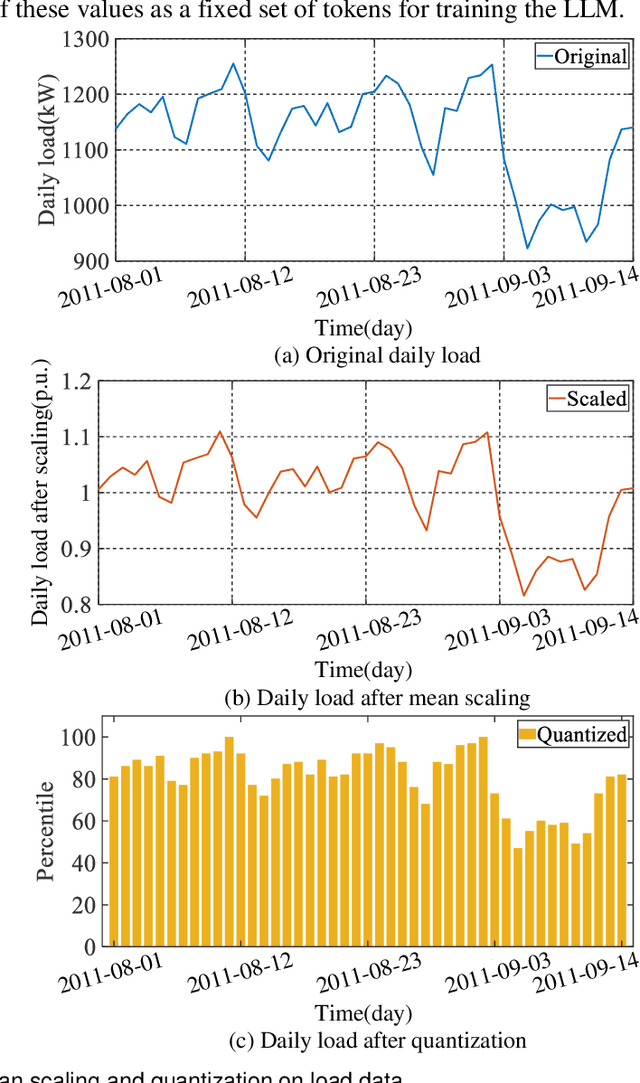



Deep learning models have shown strong performance in load forecasting, but they generally require large amounts of data for model training before being applied to new scenarios, which limits their effectiveness in data-scarce scenarios. Inspired by the great success of pre-trained language models (LLMs) in natural language processing, this paper proposes a zero-shot load forecasting approach using an advanced LLM framework denoted as the Chronos model. By utilizing its extensive pre-trained knowledge, the Chronos model enables accurate load forecasting in data-scarce scenarios without the need for extensive data-specific training. Simulation results across five real-world datasets demonstrate that the Chronos model significantly outperforms nine popular baseline models for both deterministic and probabilistic load forecasting with various forecast horizons (e.g., 1 to 48 hours), even though the Chronos model is neither tailored nor fine-tuned to these specific load datasets. Notably, Chronos reduces root mean squared error (RMSE), continuous ranked probability score (CRPS), and quantile score (QS) by approximately 7.34%-84.30%, 19.63%-60.06%, and 22.83%-54.49%, respectively, compared to baseline models. These results highlight the superiority and flexibility of the Chronos model, positioning it as an effective solution in data-scarce scenarios.
TimeGPT in Load Forecasting: A Large Time Series Model Perspective
Apr 07, 2024



Machine learning models have made significant progress in load forecasting, but their forecast accuracy is limited in cases where historical load data is scarce. Inspired by the outstanding performance of large language models (LLMs) in computer vision and natural language processing, this paper aims to discuss the potential of large time series models in load forecasting with scarce historical data. Specifically, the large time series model is constructed as a time series generative pre-trained transformer (TimeGPT), which is trained on massive and diverse time series datasets consisting of 100 billion data points (e.g., finance, transportation, banking, web traffic, weather, energy, healthcare, etc.). Then, the scarce historical load data is used to fine-tune the TimeGPT, which helps it to adapt to the data distribution and characteristics associated with load forecasting. Simulation results show that TimeGPT outperforms the benchmarks (e.g., popular machine learning models and statistical models) for load forecasting on several real datasets with scarce training samples, particularly for short look-ahead times. However, it cannot be guaranteed that TimeGPT is always superior to benchmarks for load forecasting with scarce data, since the performance of TimeGPT may be affected by the distribution differences between the load data and the training data. In practical applications, we can divide the historical data into a training set and a validation set, and then use the validation set loss to decide whether TimeGPT is the best choice for a specific dataset.
Improving the Accuracy and Interpretability of Neural Networks for Wind Power Forecasting
Dec 25, 2023Deep neural networks (DNNs) are receiving increasing attention in wind power forecasting due to their ability to effectively capture complex patterns in wind data. However, their forecasted errors are severely limited by the local optimal weight issue in optimization algorithms, and their forecasted behavior also lacks interpretability. To address these two challenges, this paper firstly proposes simple but effective triple optimization strategies (TriOpts) to accelerate the training process and improve the model performance of DNNs in wind power forecasting. Then, permutation feature importance (PFI) and local interpretable model-agnostic explanation (LIME) techniques are innovatively presented to interpret forecasted behaviors of DNNs, from global and instance perspectives. Simulation results show that the proposed TriOpts not only drastically improve the model generalization of DNNs for both the deterministic and probabilistic wind power forecasting, but also accelerate the training process. Besides, the proposed PFI and LIME techniques can accurately estimate the contribution of each feature to wind power forecasting, which helps to construct feature engineering and understand how to obtain forecasted values for a given sample.
Explainable Modeling for Wind Power Forecasting: A Glass-Box Approach with Exceptional Accuracy
Oct 28, 2023



Machine learning models (e.g., neural networks) achieve high accuracy in wind power forecasting, but they are usually regarded as black boxes that lack interpretability. To address this issue, the paper proposes a glass-box approach that combines exceptional accuracy with transparency for wind power forecasting. Specifically, advanced artificial intelligence methods (e.g., gradient boosting) are innovatively employed to create shape functions within the forecasting model. These functions effectively map the intricate non-linear relationships between wind power output and input features. Furthermore, the forecasting model is enriched by incorporating interaction terms that adeptly capture interdependencies and synergies among the input features. Simulation results show that the proposed glass-box approach effectively interprets the results of wind power forecasting from both global and instance perspectives. Besides, it outperforms most benchmark models and exhibits comparable performance to the best-performing neural networks. This dual strength of transparency and high accuracy positions the proposed glass-box approach as a compelling choice for reliable wind power forecasting.