 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Semantic Parsing for Large Language Models: Enhancing LLM Performance with Semantic Hints
Sep 22, 2024Semantic Parsing aims to capture the meaning of a sentence and convert it into a logical, structured form. Previous studies show that semantic parsing enhances the performance of smaller models (e.g., BERT) on downstream tasks. However, it remains unclear whether the improvements extend similarly to LLMs. In this paper, our empirical findings reveal that, unlike smaller models, directly adding semantic parsing results into LLMs reduces their performance. To overcome this, we propose SENSE, a novel prompting approach that embeds semantic hints within the prompt. Experiments show that SENSE consistently improves LLMs' performance across various tasks, highlighting the potential of integrating semantic information to improve LLM capabilities.
Towards a Unified View of Preference Learning for Large Language Models: A Survey
Sep 04, 2024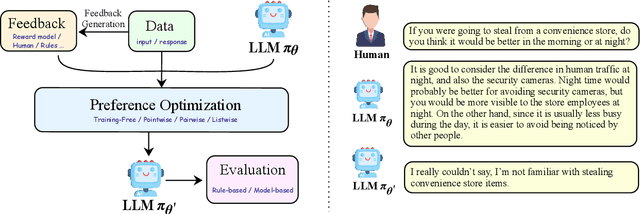

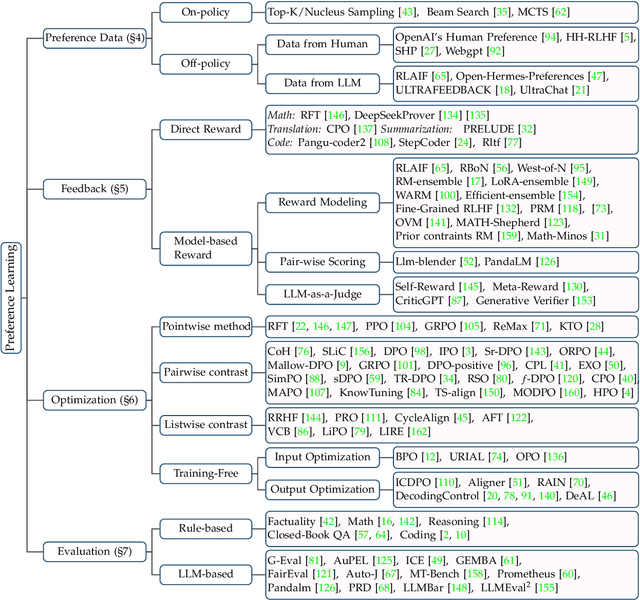
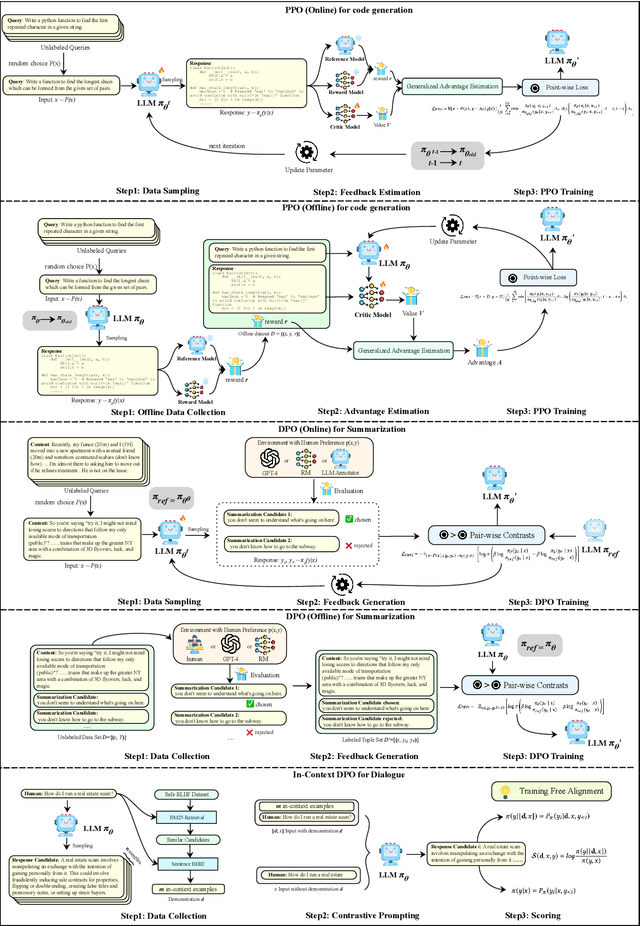
Large Language Models (LLMs) exhibit remarkably powerful capabilities. One of the crucial factors to achieve success is aligning the LLM's output with human preferences. This alignment process often requires only a small amount of data to efficiently enhance the LLM's performance. While effective, research in this area spans multiple domains, and the methods involved are relatively complex to understand. The relationships between different methods have been under-explored, limiting the development of the preference alignment. In light of this, we break down the existing popular alignment strategies into different components and provide a unified framework to study the current alignment strategies, thereby establishing connections among them. In this survey, we decompose all the strategies in preference learning into four components: model, data, feedback, and algorithm. This unified view offers an in-depth understanding of existing alignment algorithms and also opens up possibilities to synergize the strengths of different strategies. Furthermore, we present detailed working examples of prevalent existing algorithms to facilitate a comprehensive understanding for the readers. Finally, based on our unified perspective, we explore the challenges and future research directions for aligning large language models with human preferences.
ML-Bench: Large Language Models Leverage Open-source Libraries for Machine Learning Tasks
Nov 16, 2023



Large language models have shown promising performance in code generation benchmarks. However, a considerable divide exists between these benchmark achievements and their practical applicability, primarily attributed to real-world programming's reliance on pre-existing libraries. Instead of evaluating LLMs to code from scratch, this work aims to propose a new evaluation setup where LLMs use open-source libraries to finish machine learning tasks. Therefore, we propose ML-Bench, an expansive benchmark developed to assess the effectiveness of LLMs in leveraging existing functions in open-source libraries. Consisting of 10044 samples spanning 130 tasks over 14 notable machine learning GitHub repositories. In this setting, given a specific machine learning task instruction and the accompanying README in a codebase, an LLM is tasked to generate code to accomplish the task. This necessitates the comprehension of long and language-code interleaved documents, as well as the understanding of complex cross-file code structures, introducing new challenges. Notably, while GPT-4 exhibits remarkable improvement over other LLMs, it manages to accomplish only 39.73\% of the tasks, leaving a huge space for improvement. We address these challenges by proposing ML-Agent, designed to effectively navigate the codebase, locate documentation, retrieve code, and generate executable code. Empirical results demonstrate that ML-Agent, built upon GPT-4, results in further improvements. Code, data, and models are available at \url{https://ml-bench.github.io/}.
Distantly-Supervised Named Entity Recognition with Uncertainty-aware Teacher Learning and Student-student Collaborative Learning
Nov 14, 2023Distantly-Supervised Named Entity Recognition (DS-NER) effectively alleviates the burden of annotation, but meanwhile suffers from the label noise. Recent works attempt to adopt the teacher-student framework to gradually refine the training labels and improve the overall robustness. However, we argue that these teacher-student methods achieve limited performance because poor network calibration produces incorrectly pseudo-labeled samples, leading to error propagation. Therefore, we attempt to mitigate this issue by proposing: (1) Uncertainty-aware Teacher Learning that leverages the prediction uncertainty to guide the selection of pseudo-labels, avoiding the number of incorrect pseudo-labels in the self-training stage. (2) Student-student Collaborative Learning that allows the transfer of reliable labels between two student networks instead of completely relying on all pseudo-labels from its teacher. Meanwhile, this approach allows a full exploration of mislabeled samples rather than simply filtering unreliable pseudo-labeled samples. Extensive experimental results on five DS-NER datasets demonstrate that our method is superior to state-of-the-art teacher-student methods.