 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman or LLM as Standardized Patients? A Comparative Study for Medical Education
Nov 12, 2025Standardized Patients (SP) are indispensable for clinical skills training but remain expensive, inflexible, and difficult to scale. Existing large-language-model (LLM)-based SP simulators promise lower cost yet show inconsistent behavior and lack rigorous comparison with human SP. We present EasyMED, a multi-agent framework combining a Patient Agent for realistic dialogue, an Auxiliary Agent for factual consistency, and an Evaluation Agent that delivers actionable feedback. To support systematic assessment, we introduce SPBench, a benchmark of real SP-doctor interactions spanning 14 specialties and eight expert-defined evaluation criteria. Experiments demonstrate that EasyMED matches human SP learning outcomes while producing greater skill gains for lower-baseline students and offering improved flexibility, psychological safety, and cost efficiency.
SAIL-Embedding Technical Report: Omni-modal Embedding Foundation Model
Oct 14, 2025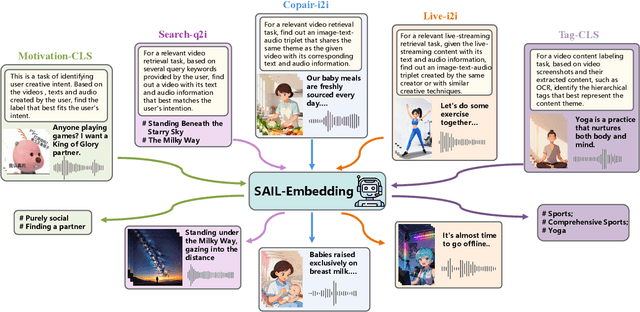

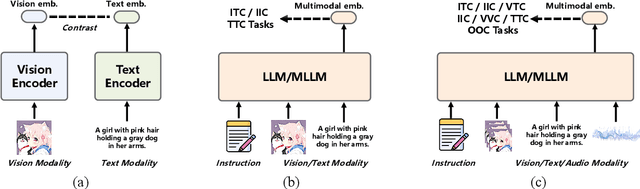
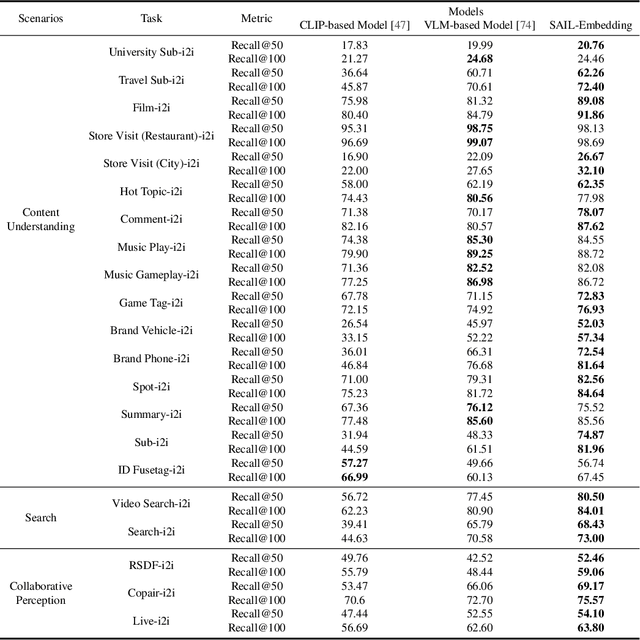
Multimodal embedding models aim to yield informative unified representations that empower diverse cross-modal tasks. Despite promising developments in the evolution from CLIP-based dual-tower architectures to large vision-language models, prior works still face unavoidable challenges in real-world applications and business scenarios, such as the limited modality support, unstable training mechanisms, and industrial domain gaps. In this work, we introduce SAIL-Embedding, an omni-modal embedding foundation model that addresses these issues through tailored training strategies and architectural design. In the optimization procedure, we propose a multi-stage training scheme to boost the multifaceted effectiveness of representation learning. Specifically, the content-aware progressive training aims to enhance the model's adaptability to diverse downstream tasks and master enriched cross-modal proficiency. The collaboration-aware recommendation enhancement training further adapts multimodal representations for recommendation scenarios by distilling knowledge from sequence-to-item and ID-to-item embeddings while mining user historical interests. Concurrently, we develop the stochastic specialization and dataset-driven pattern matching to strengthen model training flexibility and generalizability. Experimental results show that SAIL-Embedding achieves SOTA performance compared to other methods in different retrieval tasks. In online experiments across various real-world scenarios integrated with our model, we observe a significant increase in Lifetime (LT), which is a crucial indicator for the recommendation experience. For instance, the model delivers the 7-day LT gain of +0.158% and the 14-day LT gain of +0.144% in the Douyin-Selected scenario. For the Douyin feed rank model, the match features produced by SAIL-Embedding yield a +0.08% AUC gain.
Towards Assessing Medical Ethics from Knowledge to Practice
Aug 07, 2025The integration of large language models into healthcare necessitates a rigorous evaluation of their ethical reasoning, an area current benchmarks often overlook. We introduce PrinciplismQA, a comprehensive benchmark with 3,648 questions designed to systematically assess LLMs' alignment with core medical ethics. Grounded in Principlism, our benchmark features a high-quality dataset. This includes multiple-choice questions curated from authoritative textbooks and open-ended questions sourced from authoritative medical ethics case study literature, all validated by medical experts. Our experiments reveal a significant gap between models' ethical knowledge and their practical application, especially in dynamically applying ethical principles to real-world scenarios. Most LLMs struggle with dilemmas concerning Beneficence, often over-emphasizing other principles. Frontier closed-source models, driven by strong general capabilities, currently lead the benchmark. Notably, medical domain fine-tuning can enhance models' overall ethical competence, but further progress requires better alignment with medical ethical knowledge. PrinciplismQA offers a scalable framework to diagnose these specific ethical weaknesses, paving the way for more balanced and responsible medical AI.
RICO: Improving Accuracy and Completeness in Image Recaptioning via Visual Reconstruction
May 28, 2025Image recaptioning is widely used to generate training datasets with enhanced quality for various multimodal tasks. Existing recaptioning methods typically rely on powerful multimodal large language models (MLLMs) to enhance textual descriptions, but often suffer from inaccuracies due to hallucinations and incompleteness caused by missing fine-grained details. To address these limitations, we propose RICO, a novel framework that refines captions through visual reconstruction. Specifically, we leverage a text-to-image model to reconstruct a caption into a reference image, and prompt an MLLM to identify discrepancies between the original and reconstructed images to refine the caption. This process is performed iteratively, further progressively promoting the generation of more faithful and comprehensive descriptions. To mitigate the additional computational cost induced by the iterative process, we introduce RICO-Flash, which learns to generate captions like RICO using DPO. Extensive experiments demonstrate that our approach significantly improves caption accuracy and completeness, outperforms most baselines by approximately 10% on both CapsBench and CompreCap. Code released at https://github.com/wangyuchi369/RICO.
VidTwin: Video VAE with Decoupled Structure and Dynamics
Dec 23, 2024Recent advancements in video autoencoders (Video AEs) have significantly improved the quality and efficiency of video generation. In this paper, we propose a novel and compact video autoencoder, VidTwin, that decouples video into two distinct latent spaces: Structure latent vectors, which capture overall content and global movement, and Dynamics latent vectors, which represent fine-grained details and rapid movements. Specifically, our approach leverages an Encoder-Decoder backbone, augmented with two submodules for extracting these latent spaces, respectively. The first submodule employs a Q-Former to extract low-frequency motion trends, followed by downsampling blocks to remove redundant content details. The second averages the latent vectors along the spatial dimension to capture rapid motion. Extensive experiments show that VidTwin achieves a high compression rate of 0.20% with high reconstruction quality (PSNR of 28.14 on the MCL-JCV dataset), and performs efficiently and effectively in downstream generative tasks. Moreover, our model demonstrates explainability and scalability, paving the way for future research in video latent representation and generation. Our code has been released at https://github.com/microsoft/VidTok/tree/main/vidtwin.
Rethinking Semantic Parsing for Large Language Models: Enhancing LLM Performance with Semantic Hints
Sep 22, 2024Semantic Parsing aims to capture the meaning of a sentence and convert it into a logical, structured form. Previous studies show that semantic parsing enhances the performance of smaller models (e.g., BERT) on downstream tasks. However, it remains unclear whether the improvements extend similarly to LLMs. In this paper, our empirical findings reveal that, unlike smaller models, directly adding semantic parsing results into LLMs reduces their performance. To overcome this, we propose SENSE, a novel prompting approach that embeds semantic hints within the prompt. Experiments show that SENSE consistently improves LLMs' performance across various tasks, highlighting the potential of integrating semantic information to improve LLM capabilities.
Make Your Actor Talk: Generalizable and High-Fidelity Lip Sync with Motion and Appearance Disentanglement
Jun 12, 2024



We aim to edit the lip movements in talking video according to the given speech while preserving the personal identity and visual details. The task can be decomposed into two sub-problems: (1) speech-driven lip motion generation and (2) visual appearance synthesis. Current solutions handle the two sub-problems within a single generative model, resulting in a challenging trade-off between lip-sync quality and visual details preservation. Instead, we propose to disentangle the motion and appearance, and then generate them one by one with a speech-to-motion diffusion model and a motion-conditioned appearance generation model. However, there still remain challenges in each stage, such as motion-aware identity preservation in (1) and visual details preservation in (2). Therefore, to preserve personal identity, we adopt landmarks to represent the motion, and further employ a landmark-based identity loss. To capture motion-agnostic visual details, we use separate encoders to encode the lip, non-lip appearance and motion, and then integrate them with a learned fusion module. We train MyTalk on a large-scale and diverse dataset. Experiments show that our method generalizes well to the unknown, even out-of-domain person, in terms of both lip sync and visual detail preservation. We encourage the readers to watch the videos on our project page (https://Ingrid789.github.io/MyTalk/).
InstructAvatar: Text-Guided Emotion and Motion Control for Avatar Generation
May 24, 2024



Recent talking avatar generation models have made strides in achieving realistic and accurate lip synchronization with the audio, but often fall short in controlling and conveying detailed expressions and emotions of the avatar, making the generated video less vivid and controllable. In this paper, we propose a novel text-guided approach for generating emotionally expressive 2D avatars, offering fine-grained control, improved interactivity, and generalizability to the resulting video. Our framework, named InstructAvatar, leverages a natural language interface to control the emotion as well as the facial motion of avatars. Technically, we design an automatic annotation pipeline to construct an instruction-video paired training dataset, equipped with a novel two-branch diffusion-based generator to predict avatars with audio and text instructions at the same time. Experimental results demonstrate that InstructAvatar produces results that align well with both conditions, and outperforms existing methods in fine-grained emotion control, lip-sync quality, and naturalness. Our project page is https://wangyuchi369.github.io/InstructAvatar/.
LaDiC: Are Diffusion Models Really Inferior to Autoregressive Counterparts for Image-to-Text Generation?
Apr 16, 2024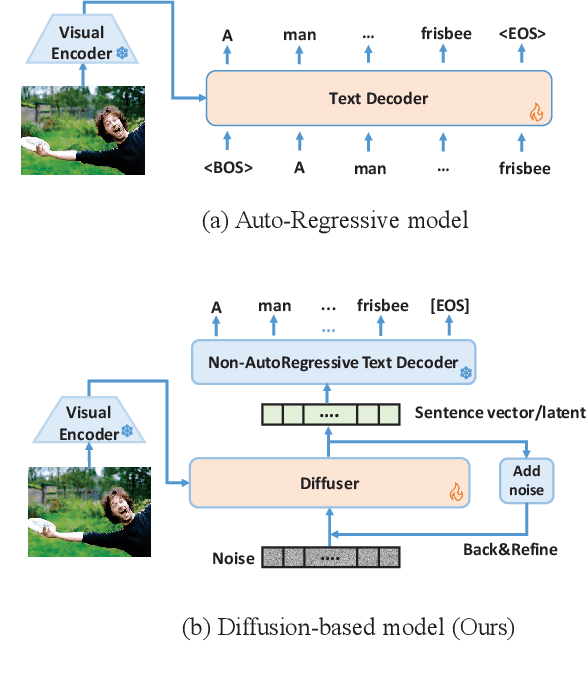
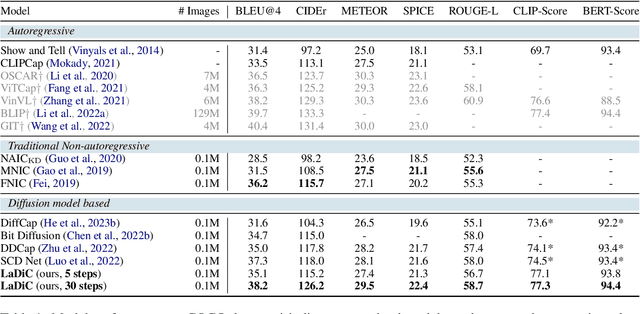
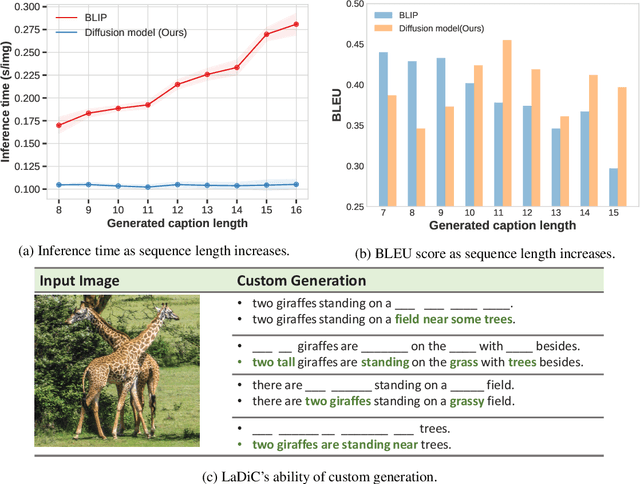
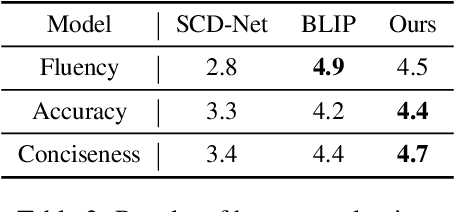
Diffusion models have exhibited remarkable capabilities in text-to-image generation. However, their performance in image-to-text generation, specifically image captioning, has lagged behind Auto-Regressive (AR) models, casting doubt on their applicability for such tasks. In this work, we revisit diffusion models, highlighting their capacity for holistic context modeling and parallel decoding. With these benefits, diffusion models can alleviate the inherent limitations of AR methods, including their slow inference speed, error propagation, and unidirectional constraints. Furthermore, we identify the prior underperformance of diffusion models stemming from the absence of an effective latent space for image-text alignment, and the discrepancy between continuous diffusion processes and discrete textual data. In response, we introduce a novel architecture, LaDiC, which utilizes a split BERT to create a dedicated latent space for captions and integrates a regularization module to manage varying text lengths. Our framework also includes a diffuser for semantic image-to-text conversion and a Back&Refine technique to enhance token interactivity during inference. LaDiC achieves state-of-the-art performance for diffusion-based methods on the MS COCO dataset with 38.2 BLEU@4 and 126.2 CIDEr, demonstrating exceptional performance without pre-training or ancillary modules. This indicates strong competitiveness with AR models, revealing the previously untapped potential of diffusion models in image-to-text generation.
UniEdit: A Unified Tuning-Free Framework for Video Motion and Appearance Editing
Feb 24, 2024

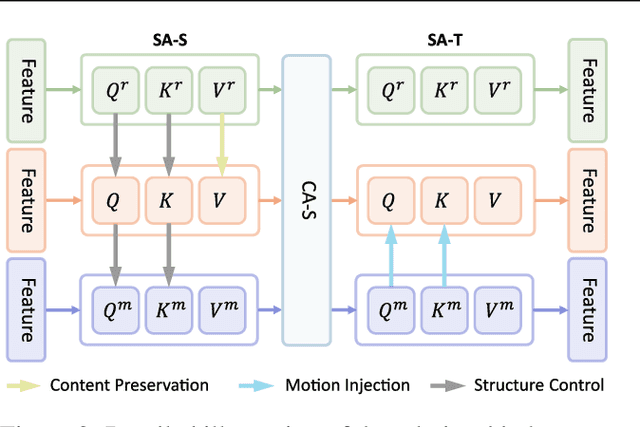

Recent advances in text-guided video editing have showcased promising results in appearance editing (e.g., stylization). However, video motion editing in the temporal dimension (e.g., from eating to waving), which distinguishes video editing from image editing, is underexplored. In this work, we present UniEdit, a tuning-free framework that supports both video motion and appearance editing by harnessing the power of a pre-trained text-to-video generator within an inversion-then-generation framework. To realize motion editing while preserving source video content, based on the insights that temporal and spatial self-attention layers encode inter-frame and intra-frame dependency respectively, we introduce auxiliary motion-reference and reconstruction branches to produce text-guided motion and source features respectively. The obtained features are then injected into the main editing path via temporal and spatial self-attention layers. Extensive experiments demonstrate that UniEdit covers video motion editing and various appearance editing scenarios, and surpasses the state-of-the-art methods. Our code will be publicly available.