 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRE-TRAC: REcursive TRAjectory Compression for Deep Search Agents
Feb 02, 2026LLM-based deep research agents are largely built on the ReAct framework. This linear design makes it difficult to revisit earlier states, branch into alternative search directions, or maintain global awareness under long contexts, often leading to local optima, redundant exploration, and inefficient search. We propose Re-TRAC, an agentic framework that performs cross-trajectory exploration by generating a structured state representation after each trajectory to summarize evidence, uncertainties, failures, and future plans, and conditioning subsequent trajectories on this state representation. This enables iterative reflection and globally informed planning, reframing research as a progressive process. Empirical results show that Re-TRAC consistently outperforms ReAct by 15-20% on BrowseComp with frontier LLMs. For smaller models, we introduce Re-TRAC-aware supervised fine-tuning, achieving state-of-the-art performance at comparable scales. Notably, Re-TRAC shows a monotonic reduction in tool calls and token usage across rounds, indicating progressively targeted exploration driven by cross-trajectory reflection rather than redundant search.
Waveform-domain NOMA: An Enabler for ISAC in Uplink Transmission
Nov 11, 2025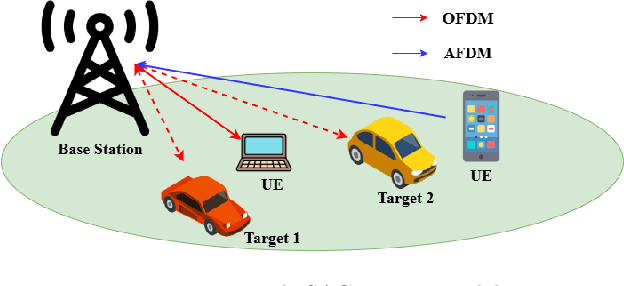
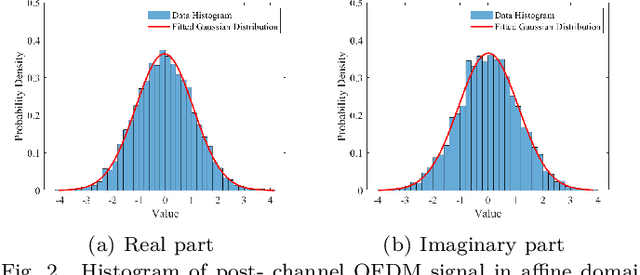
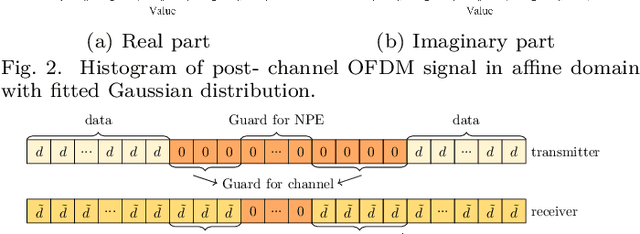
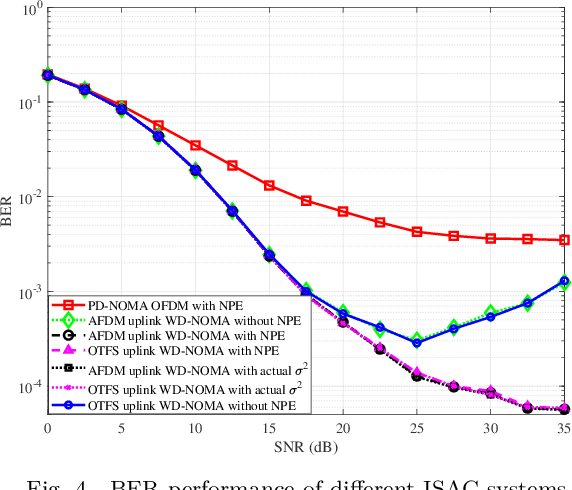
According to the recent 3GPP decisions on 6G air interface, orthogonal frequency-division multiplexing (OFDM)-based waveforms are the primary candidates for future integrated sensing and communication (ISAC) systems. In this paper, we consider a monostatic sensing scenario in which OFDM is used for the downlink and its reflected echo signal is used for sensing. OFDM and discrete Fourier transform-spread OFDM (DFT-s-OFDM) are the options for uplink transmission. When OFDM is used in the uplink, the power difference between this signal and the echo signal leads to a power-domain non-orthogonal multiple access (PD-NOMA) scenario. In contrast, adopting DFT-s-OFDM as uplink signal enables a waveform-domain NOMA(WD-NOMA). Affine frequency-division multiplexing (AFDM) and orthogonal time frequency space (OTFS) have been proven to be DFT-s-OFDM based waveforms. This work focuses on such a WD-NOMA system, where AFDM or OTFS is used as uplink waveform and OFDM is employed for downlink transmission and sensing. We show that the OFDM signal exhibits additive white Gaussian noise (AWGN)-like behavior in the affine domain, allowing it to be modeled as white noise in uplink symbol detection. To enable accurate data detection performance, an AFDM frame design and a noise power estimation (NPE) method are developed. Furthermore, a two-dimensional orthogonal matching pursuit (2D-OMP) algorithm is applied for sensing by iteratively identifying delay-Doppler components of each target. Simulation results demonstrate that the WD-NOMA ISAC system, employing either AFDM or OTFS, outperforms the PD-NOMA ISAC system that uses only the OFDM waveform in terms of bit error rate (BER) performance. Furthermore, the proposed NPE method yields additional improvements in BER.
Phi-Ground Tech Report: Advancing Perception in GUI Grounding
Jul 31, 2025



With the development of multimodal reasoning models, Computer Use Agents (CUAs), akin to Jarvis from \textit{"Iron Man"}, are becoming a reality. GUI grounding is a core component for CUAs to execute actual actions, similar to mechanical control in robotics, and it directly leads to the success or failure of the system. It determines actions such as clicking and typing, as well as related parameters like the coordinates for clicks. Current end-to-end grounding models still achieve less than 65\% accuracy on challenging benchmarks like ScreenSpot-pro and UI-Vision, indicating they are far from being ready for deployment. % , as a single misclick can result in unacceptable consequences. In this work, we conduct an empirical study on the training of grounding models, examining details from data collection to model training. Ultimately, we developed the \textbf{Phi-Ground} model family, which achieves state-of-the-art performance across all five grounding benchmarks for models under $10B$ parameters in agent settings. In the end-to-end model setting, our model still achieves SOTA results with scores of \textit{\textbf{43.2}} on ScreenSpot-pro and \textit{\textbf{27.2}} on UI-Vision. We believe that the various details discussed in this paper, along with our successes and failures, not only clarify the construction of grounding models but also benefit other perception tasks. Project homepage: \href{https://zhangmiaosen2000.github.io/Phi-Ground/}{https://zhangmiaosen2000.github.io/Phi-Ground/}
PAPR of DFT-s-OTFS with Pulse Shaping
Jul 16, 2025Orthogonal Time Frequency Space (OTFS) suffers from high peak-to-average power ratio (PAPR) when the number of Doppler bins is large. To address this issue, a discrete Fourier transform spread OTFS (DFT-s-OTFS) scheme is employed by applying DFT spreading across the Doppler dimension. This paper presents a thorough PAPR analysis of DFT-s-OTFS in the uplink scenario using different pulse shaping filters and resource allocation strategies. Specifically, we derive a PAPR upper bound of DFT-s-OTFS with interleaved and block Doppler resource allocation schemes. Our analysis reveals that DFT-s-OTFS with interleaved allocation yields a lower PAPR than that of block allocation. Furthermore, we show that interleaved allocation produces a periodic time-domain signal composed of repeated quadrature amplitude modulated (QAM) symbols which simplifies the transmitter design. Based on our analytical results, the root raised cosine (RRC) pulse generally results in a higher maximum PAPR compared to the rectangular pulse. Simulation results confirm the validity of the derived PAPR upper bounds. Furthermore, we also demonstrate through BER simulation analysis that the DFT-s-OTFS gives the same performance as OTFS without DFT spreading.
Delay-Doppler Multiplexing With Global Filtering
Jan 23, 2025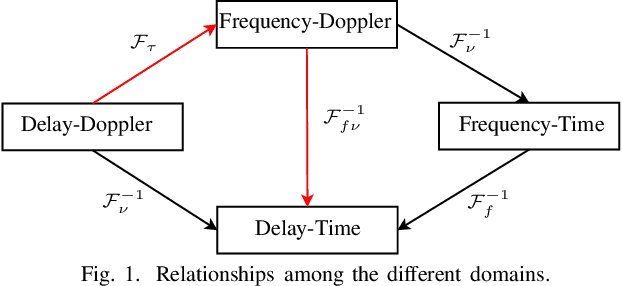
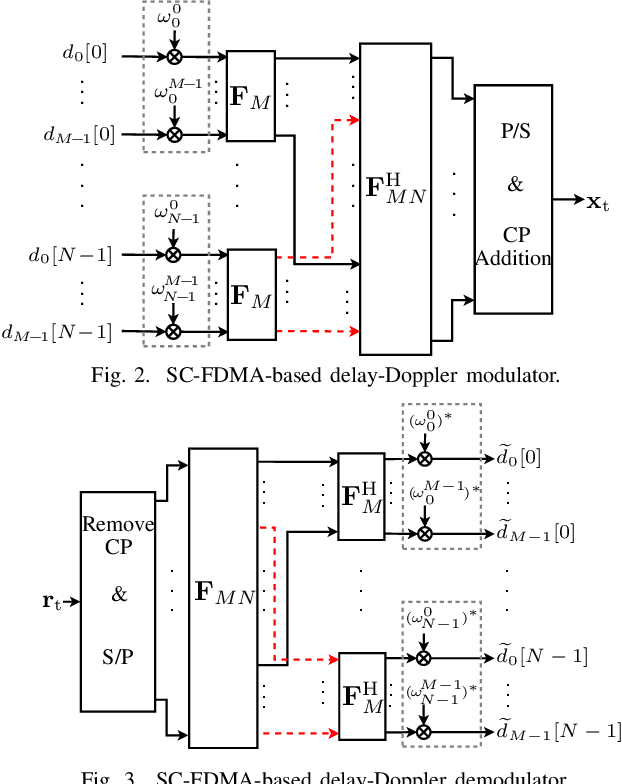
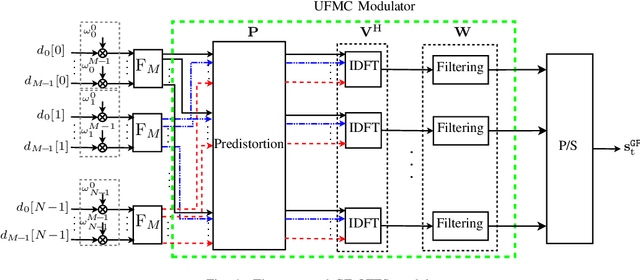
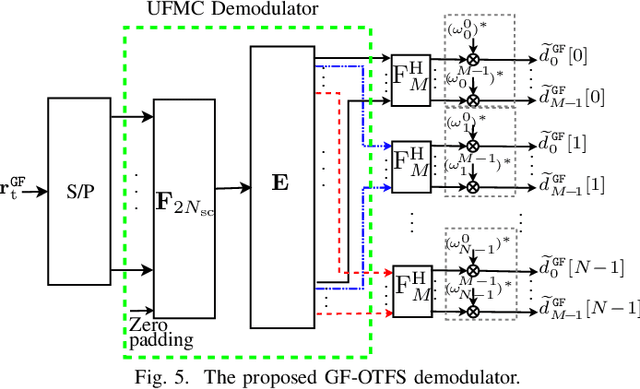
This paper proposes a novel modulation technique called globally filtered orthogonal time frequency space (GF-OTFS) which integrates single-carrier frequency division multiple access (SC-FDMA)-based delay-Doppler representation with universal filtered multi-carrier (UFMC) modulation. Our proposed technique first arranges the frequency-Doppler bins of an orthogonal time frequency space (OTFS) frame in adjacency using SC-FDMA and then applies universal filtering to the neighboring signals to mitigate inter-Doppler interference (IDI). By employing this approach, GF-OTFS achieves superior spectral containment and effectively mitigates interference caused by Doppler shifts in dynamic, time-varying channels. This paper also presents a detailed mathematical formulation of the proposed modulation technique. Furthermore, a comprehensive performance evaluation is conducted, comparing our GF-OTFS approach to state-of-the-art techniques, including Doppler-resilient UFMC (DR-UFMC) and receiver windowed OTFS (RW-OTFS). Key performance metrics, such as bit error rate (BER) and out-of-band (OOB) emissions, as well as the Doppler spread reduction are analyzed to assess the effectiveness of each approach. The results indicate that our proposed technique achieves comparable BER performance while significantly improving spectral containment.
Disentangle Estimation of Causal Effects from Cross-Silo Data
Jan 04, 2024Estimating causal effects among different events is of great importance to critical fields such as drug development. Nevertheless, the data features associated with events may be distributed across various silos and remain private within respective parties, impeding direct information exchange between them. This, in turn, can result in biased estimations of local causal effects, which rely on the characteristics of only a subset of the covariates. To tackle this challenge, we introduce an innovative disentangle architecture designed to facilitate the seamless cross-silo transmission of model parameters, enriched with causal mechanisms, through a combination of shared and private branches. Besides, we introduce global constraints into the equation to effectively mitigate bias within the various missing domains, thereby elevating the accuracy of our causal effect estimation. Extensive experiments conducted on new semi-synthetic datasets show that our method outperforms state-of-the-art baselines.
GAIA: Zero-shot Talking Avatar Generation
Nov 26, 2023



Zero-shot talking avatar generation aims at synthesizing natural talking videos from speech and a single portrait image. Previous methods have relied on domain-specific heuristics such as warping-based motion representation and 3D Morphable Models, which limit the naturalness and diversity of the generated avatars. In this work, we introduce GAIA (Generative AI for Avatar), which eliminates the domain priors in talking avatar generation. In light of the observation that the speech only drives the motion of the avatar while the appearance of the avatar and the background typically remain the same throughout the entire video, we divide our approach into two stages: 1) disentangling each frame into motion and appearance representations; 2) generating motion sequences conditioned on the speech and reference portrait image. We collect a large-scale high-quality talking avatar dataset and train the model on it with different scales (up to 2B parameters). Experimental results verify the superiority, scalability, and flexibility of GAIA as 1) the resulting model beats previous baseline models in terms of naturalness, diversity, lip-sync quality, and visual quality; 2) the framework is scalable since larger models yield better results; 3) it is general and enables different applications like controllable talking avatar generation and text-instructed avatar generation.
Multiple View Geometry Transformers for 3D Human Pose Estimation
Nov 18, 2023



In this work, we aim to improve the 3D reasoning ability of Transformers in multi-view 3D human pose estimation. Recent works have focused on end-to-end learning-based transformer designs, which struggle to resolve geometric information accurately, particularly during occlusion. Instead, we propose a novel hybrid model, MVGFormer, which has a series of geometric and appearance modules organized in an iterative manner. The geometry modules are learning-free and handle all viewpoint-dependent 3D tasks geometrically which notably improves the model's generalization ability. The appearance modules are learnable and are dedicated to estimating 2D poses from image signals end-to-end which enables them to achieve accurate estimates even when occlusion occurs, leading to a model that is both accurate and generalizable to new cameras and geometries. We evaluate our approach for both in-domain and out-of-domain settings, where our model consistently outperforms state-of-the-art methods, and especially does so by a significant margin in the out-of-domain setting. We will release the code and models: https://github.com/XunshanMan/MVGFormer.