 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALO: Semantic-Aware Distributed LLM Inference in Lossy Edge Network
Jan 16, 2026The deployment of large language models' (LLMs) inference at the edge can facilitate prompt service responsiveness while protecting user privacy. However, it is critically challenged by the resource constraints of a single edge node. Distributed inference has emerged to aggregate and leverage computational resources across multiple devices. Yet, existing methods typically require strict synchronization, which is often infeasible due to the unreliable network conditions. In this paper, we propose HALO, a novel framework that can boost the distributed LLM inference in lossy edge network. The core idea is to enable a relaxed yet effective synchronization by strategically allocating less critical neuron groups to unstable devices, thus avoiding the excessive waiting time incurred by delayed packets. HALO introduces three key mechanisms: (1) a semantic-aware predictor to assess the significance of neuron groups prior to activation. (2) a parallel execution scheme of neuron group loading during the model inference. (3) a load-balancing scheduler that efficiently orchestrates multiple devices with heterogeneous resources. Experimental results from a Raspberry Pi cluster demonstrate that HALO achieves a 3.41x end-to-end speedup for LLaMA-series LLMs under unreliable network conditions. It maintains performance comparable to optimal conditions and significantly outperforms the state-of-the-art in various scenarios.
OmniVGGT: Omni-Modality Driven Visual Geometry Grounded Transformer
Nov 14, 2025General 3D foundation models have started to lead the trend of unifying diverse vision tasks, yet most assume RGB-only inputs and ignore readily available geometric cues (e.g., camera intrinsics, poses, and depth maps). To address this issue, we introduce OmniVGGT, a novel framework that can effectively benefit from an arbitrary number of auxiliary geometric modalities during both training and inference. In our framework, a GeoAdapter is proposed to encode depth and camera intrinsics/extrinsics into a spatial foundation model. It employs zero-initialized convolutions to progressively inject geometric information without disrupting the foundation model's representation space. This design ensures stable optimization with negligible overhead, maintaining inference speed comparable to VGGT even with multiple additional inputs. Additionally, a stochastic multimodal fusion regimen is proposed, which randomly samples modality subsets per instance during training. This enables an arbitrary number of modality inputs during testing and promotes learning robust spatial representations instead of overfitting to auxiliary cues. Comprehensive experiments on monocular/multi-view depth estimation, multi-view stereo, and camera pose estimation demonstrate that OmniVGGT outperforms prior methods with auxiliary inputs and achieves state-of-the-art results even with RGB-only input. To further highlight its practical utility, we integrated OmniVGGT into vision-language-action (VLA) models. The enhanced VLA model by OmniVGGT not only outperforms the vanilla point-cloud-based baseline on mainstream benchmarks, but also effectively leverages accessible auxiliary inputs to achieve consistent gains on robotic tasks.
Cross-Receiver Generalization for RF Fingerprint Identification via Feature Disentanglement and Adversarial Training
Oct 10, 2025
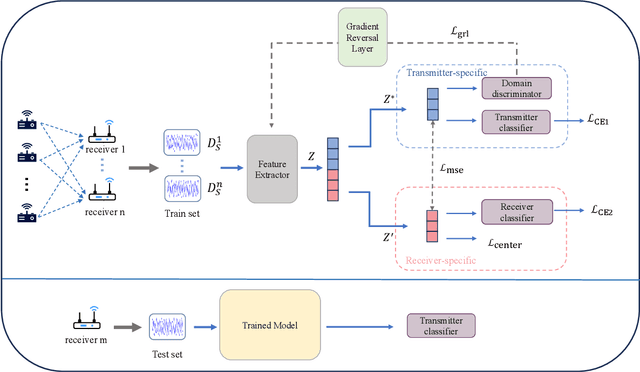
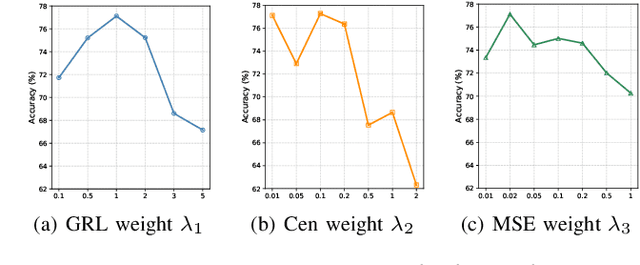
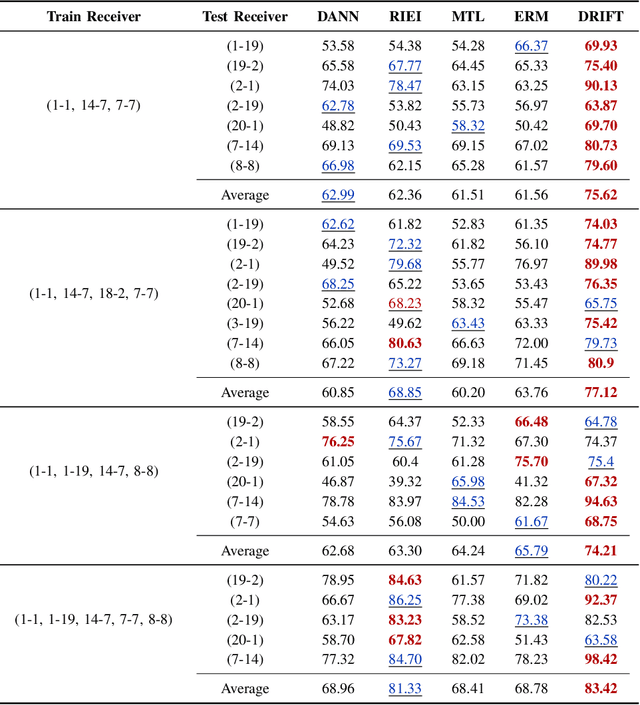
Radio frequency fingerprint identification (RFFI) is a critical technique for wireless network security, leveraging intrinsic hardware-level imperfections introduced during device manufacturing to enable precise transmitter identification. While deep neural networks have shown remarkable capability in extracting discriminative features, their real-world deployment is hindered by receiver-induced variability. In practice, RF fingerprint signals comprise transmitter-specific features as well as channel distortions and receiver-induced biases. Although channel equalization can mitigate channel noise, receiver-induced feature shifts remain largely unaddressed, causing the RFFI models to overfit to receiver-specific patterns. This limitation is particularly problematic when training and evaluation share the same receiver, as replacing the receiver in deployment can cause substantial performance degradation. To tackle this challenge, we propose an RFFI framework robust to cross-receiver variability, integrating adversarial training and style transfer to explicitly disentangle transmitter and receiver features. By enforcing domain-invariant representation learning, our method isolates genuine hardware signatures from receiver artifacts, ensuring robustness against receiver changes. Extensive experiments on multi-receiver datasets demonstrate that our approach consistently outperforms state-of-the-art baselines, achieving up to a 10% improvement in average accuracy across diverse receiver settings.
Probing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025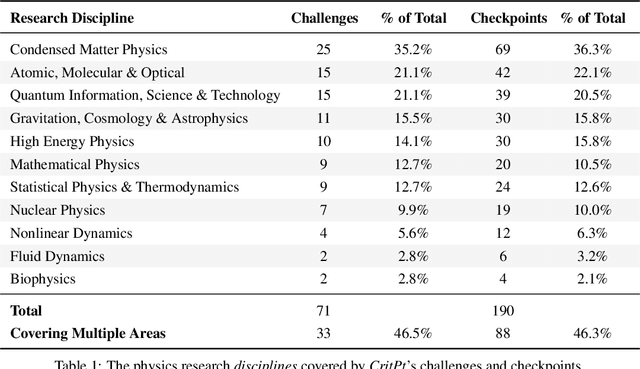
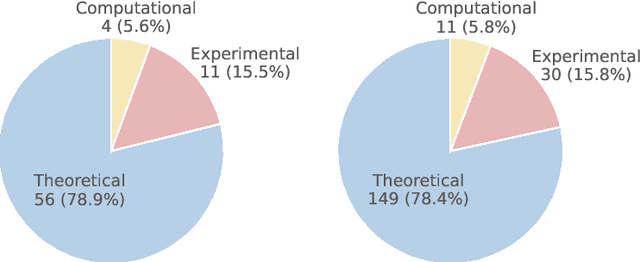
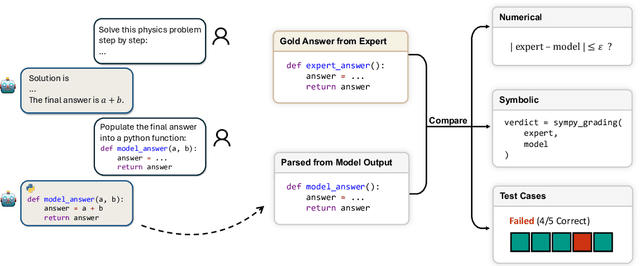

While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Efficient Edge LLMs Deployment via HessianAware Quantization and CPU GPU Collaborative
Aug 10, 2025With the breakthrough progress of large language models (LLMs) in natural language processing and multimodal tasks, efficiently deploying them on resource-constrained edge devices has become a critical challenge. The Mixture of Experts (MoE) architecture enhances model capacity through sparse activation, but faces two major difficulties in practical deployment: (1) The presence of numerous outliers in activation distributions leads to severe degradation in quantization accuracy for both activations and weights, significantly impairing inference performance; (2) Under limited memory, efficient offloading and collaborative inference of expert modules struggle to balance latency and throughput. To address these issues, this paper proposes an efficient MoE edge deployment scheme based on Hessian-Aware Quantization (HAQ) and CPU-GPU collaborative inference. First, by introducing smoothed Hessian matrix quantization, we achieve joint 8-bit quantization of activations and weights, which significantly alleviates the accuracy loss caused by outliers while ensuring efficient implementation on mainstream hardware. Second, we design an expert-level collaborative offloading and inference mechanism, which, combined with expert activation path statistics, enables efficient deployment and scheduling of expert modules between CPU and GPU, greatly reducing memory footprint and inference latency. Extensive experiments validate the effectiveness of our method on mainstream large models such as the OPT series and Mixtral 8*7B: on datasets like Wikitext2 and C4, the inference accuracy of the low-bit quantized model approaches that of the full-precision model, while GPU memory usage is reduced by about 60%, and inference latency is significantly improved.
Deploying Foundation Model Powered Agent Services: A Survey
Dec 18, 2024



Foundation model (FM) powered agent services are regarded as a promising solution to develop intelligent and personalized applications for advancing toward Artificial General Intelligence (AGI). To achieve high reliability and scalability in deploying these agent services, it is essential to collaboratively optimize computational and communication resources, thereby ensuring effective resource allocation and seamless service delivery. In pursuit of this vision, this paper proposes a unified framework aimed at providing a comprehensive survey on deploying FM-based agent services across heterogeneous devices, with the emphasis on the integration of model and resource optimization to establish a robust infrastructure for these services. Particularly, this paper begins with exploring various low-level optimization strategies during inference and studies approaches that enhance system scalability, such as parallelism techniques and resource scaling methods. The paper then discusses several prominent FMs and investigates research efforts focused on inference acceleration, including techniques such as model compression and token reduction. Moreover, the paper also investigates critical components for constructing agent services and highlights notable intelligent applications. Finally, the paper presents potential research directions for developing real-time agent services with high Quality of Service (QoS).
Unleashing the Power of Continual Learning on Non-Centralized Devices: A Survey
Dec 18, 2024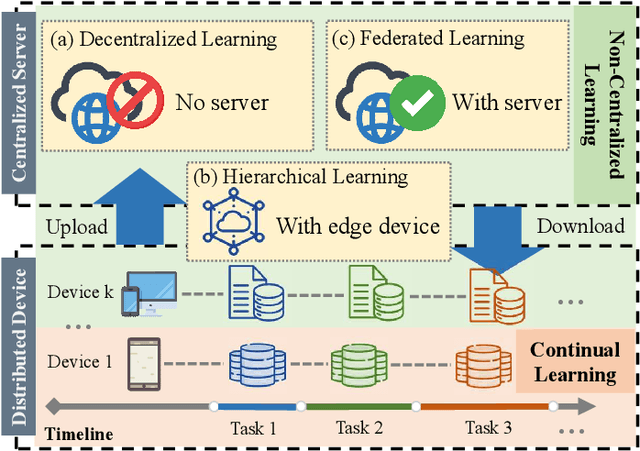
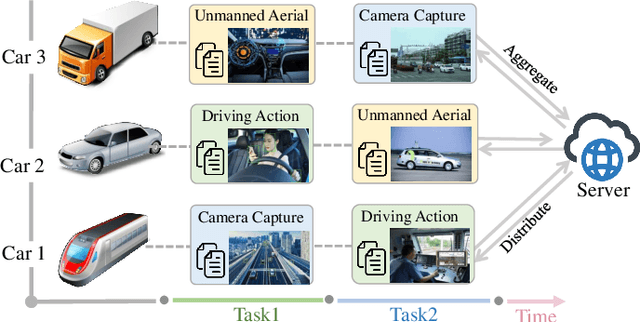
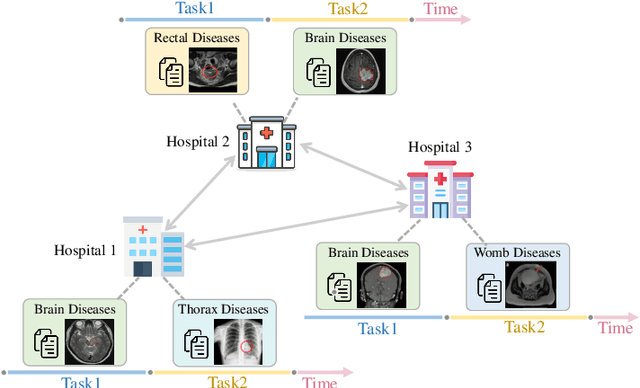
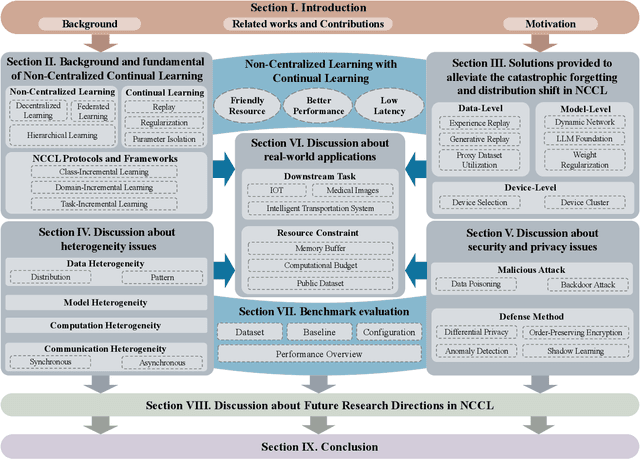
Non-Centralized Continual Learning (NCCL) has become an emerging paradigm for enabling distributed devices such as vehicles and servers to handle streaming data from a joint non-stationary environment. To achieve high reliability and scalability in deploying this paradigm in distributed systems, it is essential to conquer challenges stemming from both spatial and temporal dimensions, manifesting as distribution shifts, catastrophic forgetting, heterogeneity, and privacy issues. This survey focuses on a comprehensive examination of the development of the non-centralized continual learning algorithms and the real-world deployment across distributed devices. We begin with an introduction to the background and fundamentals of non-centralized learning and continual learning. Then, we review existing solutions from three levels to represent how existing techniques alleviate the catastrophic forgetting and distribution shift. Additionally, we delve into the various types of heterogeneity issues, security, and privacy attributes, as well as real-world applications across three prevalent scenarios. Furthermore, we establish a large-scale benchmark to revisit this problem and analyze the performance of the state-of-the-art NCCL approaches. Finally, we discuss the important challenges and future research directions in NCCL.
Boosting Fine-Grained Visual Anomaly Detection with Coarse-Knowledge-Aware Adversarial Learning
Dec 17, 2024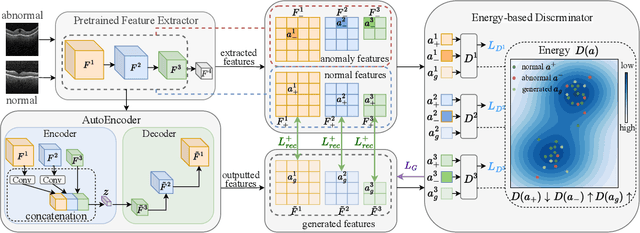
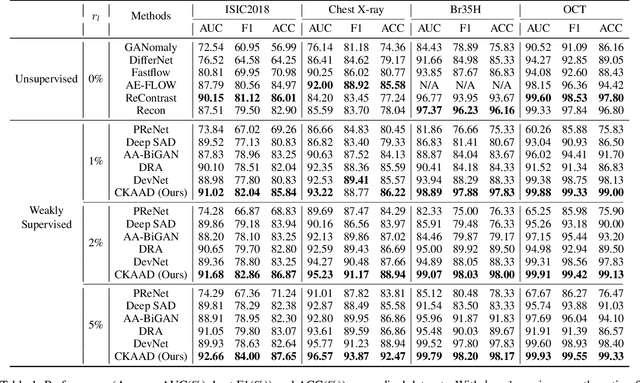
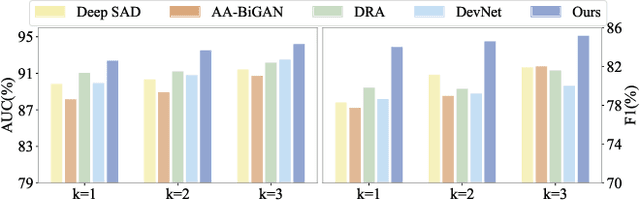

Many unsupervised visual anomaly detection methods train an auto-encoder to reconstruct normal samples and then leverage the reconstruction error map to detect and localize the anomalies. However, due to the powerful modeling and generalization ability of neural networks, some anomalies can also be well reconstructed, resulting in unsatisfactory detection and localization accuracy. In this paper, a small coarsely-labeled anomaly dataset is first collected. Then, a coarse-knowledge-aware adversarial learning method is developed to align the distribution of reconstructed features with that of normal features. The alignment can effectively suppress the auto-encoder's reconstruction ability on anomalies and thus improve the detection accuracy. Considering that anomalies often only occupy very small areas in anomalous images, a patch-level adversarial learning strategy is further developed. Although no patch-level anomalous information is available, we rigorously prove that by simply viewing any patch features from anomalous images as anomalies, the proposed knowledge-aware method can also align the distribution of reconstructed patch features with the normal ones. Experimental results on four medical datasets and two industrial datasets demonstrate the effectiveness of our method in improving the detection and localization performance.
A QoE-Aware Split Inference Accelerating Algorithm for NOMA-based Edge Intelligence
Sep 25, 2024
Even the AI has been widely used and significantly changed our life, deploying the large AI models on resource limited edge devices directly is not appropriate. Thus, the model split inference is proposed to improve the performance of edge intelligence, in which the AI model is divided into different sub models and the resource-intensive sub model is offloaded to edge server wirelessly for reducing resource requirements and inference latency. However, the previous works mainly concentrate on improving and optimizing the system QoS, ignore the effect of QoE which is another critical item for the users except for QoS. Even the QoE has been widely learned in EC, considering the differences between task offloading in EC and split inference in EI, and the specific issues in QoE which are still not addressed in EC and EI, these algorithms cannot work effectively in edge split inference scenarios. Thus, an effective resource allocation algorithm is proposed in this paper, for accelerating split inference in EI and achieving the tradeoff between inference delay, QoE, and resource consumption, abbreviated as ERA. Specifically, the ERA takes the resource consumption, QoE, and inference latency into account to find the optimal model split strategy and resource allocation strategy. Since the minimum inference delay and resource consumption, and maximum QoE cannot be satisfied simultaneously, the gradient descent based algorithm is adopted to find the optimal tradeoff between them. Moreover, the loop iteration GD approach is developed to reduce the complexity of the GD algorithm caused by parameter discretization. Additionally, the properties of the proposed algorithms are investigated, including convergence, complexity, and approximation error. The experimental results demonstrate that the performance of ERA is much better than that of the previous studies.
FedBAT: Communication-Efficient Federated Learning via Learnable Binarization
Aug 06, 2024



Federated learning is a promising distributed machine learning paradigm that can effectively exploit large-scale data without exposing users' privacy. However, it may incur significant communication overhead, thereby potentially impairing the training efficiency. To address this challenge, numerous studies suggest binarizing the model updates. Nonetheless, traditional methods usually binarize model updates in a post-training manner, resulting in significant approximation errors and consequent degradation in model accuracy. To this end, we propose Federated Binarization-Aware Training (FedBAT), a novel framework that directly learns binary model updates during the local training process, thus inherently reducing the approximation errors. FedBAT incorporates an innovative binarization operator, along with meticulously designed derivatives to facilitate efficient learning. In addition, we establish theoretical guarantees regarding the convergence of FedBAT. Extensive experiments are conducted on four popular datasets. The results show that FedBAT significantly accelerates the convergence and exceeds the accuracy of baselines by up to 9\%, even surpassing that of FedAvg in some cases.